
Meta has unveiled a recent image-generating artificial intelligence (AI) model that may reason like humans.
This model is characterised by analyzing a given image using the prevailing background knowledge and understanding what’s contained in your complete image like a human, just as an individual understands a recent environment through the previously learned background knowledge.
Through this, the error of generating images with fewer or more fingers, which was often seen in existing image-generating AI, isn’t any longer committed.
On the thirteenth (local time), Meta released the ‘I-JEPA’ model, which might infer background knowledge of images, as an open source on its blog.
I-Zepa is an AI model designed to more accurately analyze and complete unfinished images in a ‘human-like’ way.
This approach builds on a recent AI inference method devised by Yann LeCun Meta Chief AI Scientist. It’s characterised by making AI systems able to learning and reasoning like animals and humans.
Existing image-generating AI models create recent images by analyzing the encircling pixels of a given image. It learns by removing or distorting a few of the inputs to the model.
For instance, erase a part of an image or hide some words in a text passage. It then tries to predict which pixels or words are corrupted or missing. Nevertheless, the downside is that the model tries to fill in all of the missing information, though the world is inherently unpredictable.
In consequence, existing generative models focus an excessive amount of on irrelevant details as a substitute of capturing high-level predictable concepts, making them vulnerable to mistakes that humans would never make. For instance, it is rather difficult for a generative model to accurately generate a human hand.
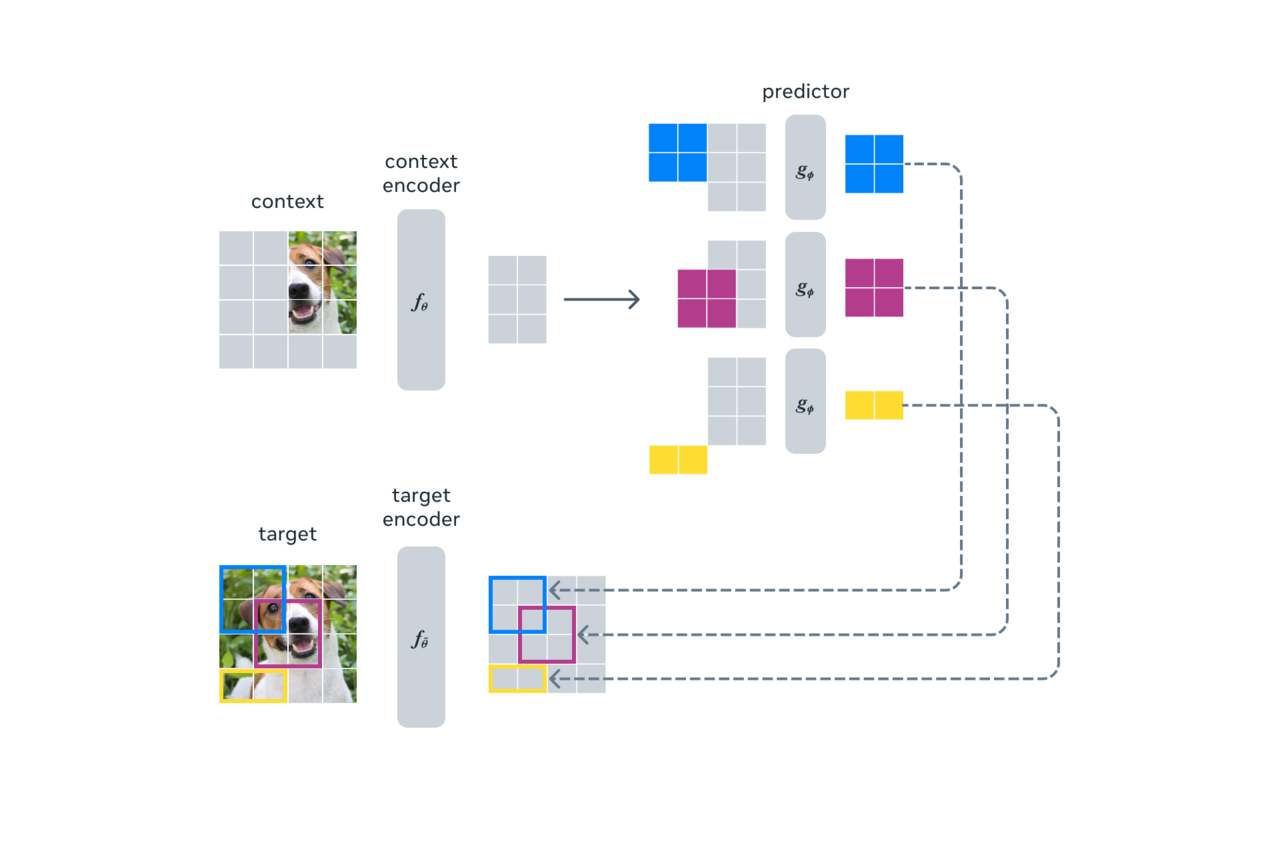
I-Zepa uses a very different method. The model goals to predict the representation of a missing image or piece of text from representations of other parts inside the same image by learning by comparing abstract representations of images moderately than comparing pixels themselves.
The essential idea of I-zepa is to predict missing information in an abstract representation just like what people normally understand.
Unlike existing generative models that predict in units of pixels or tokens, it predicts the representation of assorted blocks occurring in the identical image by dividing a picture into large blocks and learning semantic features between blocks.
For instance, seeing an image of a bird with missing legs, the model recognizes the bird and semantically recognizes that the bird’s legs should be filled in.

I-zepa offers strong performance on many computer vision tasks and is significantly more computationally efficient than other computer vision models. As well as, the expressions learned with I-zepa might be utilized in quite a lot of applications without fine-tuning.
For instance, training a 632 million-parameter visual transformer model using 16 A100 GPUs in lower than 72 hours resulted in raw-shot classification on ImageNet with only 12 labeled examples per class. Achieved state-of-the-art performance for Other methods typically take 2 to 10 times more GPU time when trained with the identical amount of information, and have much higher error rates.
Meanwhile, the paper on I-zepa, ‘Self-supervised learning of images using joint embedding prediction architecture’, can be presented on the ‘Computer Vision and Pattern Recognition Conference (CVPR 2023)’ held in Vancouver, Canada from the 18th to the twenty second. am. The training code and model checkpoints are currently open-sourced through GitHub.
Reporter Park Chan cpark@aitimes.com
jazz music helps you concentrate
Uçak uçur para kazan aviator oyunu için sitemize bekliyoruz başlangıç bonusu veriyoruz Aviator oyunu için buraya tıkla
aviator,aviator oyunu,uçak oyunu