
신경망에서 추론을 위해 활성화되는 뉴런의 수를 최소화하는 새로운 딥러닝 아키텍처가 나왔다. 이를 통해 대형언어모델(LLM)의 추론 속도와 비용을 최대 300배까지 줄였다고 밝혔다.
벤처비트는 24일(현지시간) 취리히 연방 공과대학교 연구진이 LLM의 기반이 되는 트랜스포머 신경망의 피드 포워드 레이어에서 추론에 적합한 뉴런을 식별함으로써 계산 부하를 줄이는 ‘패스트 피드 포워드(Fast Feed Forward)’ 아키텍처를 공개했다고 소개했다.
일반적으로 문장 속 단어와 같은 순차 데이터를 학습해 맥락과 의미를 추적하는 트랜스포머 모델은 서로 떨어져 있는 데이터 요소들의 의미를 이해라는 ‘어텐션(attention)’ 레이어와 입력 데이터 변환을 담당하는 피드 포워드 레이어로 구성된다.
특히 피드 포워드 레이어는 모든 뉴런과 입력 매개변수의 곱을 계산해야 하는 계산 집약적인 부분으로, 모델 성능의 핵심이다.
연구진은 피드 포워드 레이어 내의 모든 뉴런이 입력에 대한 추론 프로세스 동안 활성화될 필요가 없다는 점에 착안, 새로운 패스트 피드 포워드(FFF) 아키텍처를 도입했다.
FFF는 기존 피드 포워드 네트워크에서 사용하는 ‘밀집 행렬 곱셈(DMM)’을 대체하는 ‘조건부 행렬 곱셈(CMM)’이라는 수학적 연산을 사용한다.
DMM는 모든 입력 매개변수에 네트워크의 모든 뉴런을 곱하는 계산 집약적이고 비효율적인 프로세스다. 반면에 CMM은 뉴런을 이진 트리(binary tree)로 배열, 입력에 따라 조건부로 하나의 분기만 실행함으로써 소수의 뉴런을 사용하는 방식으로 추론을 처리한다. 즉 FFF는 각 계산에 적합한 뉴런을 식별, 계산 부하를 크게 줄여 빠르고 효율적으로 언어 모델을 작동하도록 만들 수 있다.
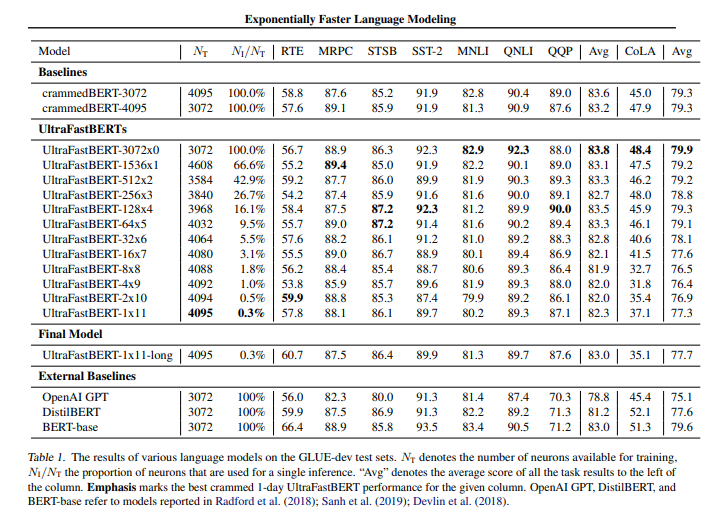
연구진은 이 기술을 검증하기 위해 트랜스포머 기반의 구글 ‘버트(BERT)’의 피드 포워드 레이어를 FFF로 대체한 ‘패스트 보트(Fast BERT)’ 모델을 개발했다.
패스트 버트 모델은 일반 언어 이해 평가(GLUE) 벤치마크의 다양한 작업에 대해 미세조정한 결과, 비슷한 크기와 훈련 절차를 거친 기존 버트 모델과 비슷한 성능을 보였다.
단일 ‘A6000’ GPU에서 단 하루 동안 훈련한 패스트 버트 모델은 버트 모델 성능의 최소 96%를 유지했으며, 가장 뛰어난 실험 결과에서는 피드 포워드 레이어의 뉴런을 고작 0.3%만 사용하면서 기존 버트 모델과 동일한 성능을 보였다.
특히 연구진은 FFF 네트워크를 LLM에 통합하면 엄청난 가속 가능성이 있다고 주장했다. 예를 들어 ‘GPT-3’에서 각 트랜스포머의 피드 포워드 네트워크는 4만9152개의 뉴런으로 구성되지만, 15층 깊이의 FFF 네트워크로 대체할 경우 총 6만5536개의 뉴런을 포함하지만 실제 추론에는 GPT-3 뉴런의 약 0.03%에 해당하는 16개만 사용한다.
결과적으로 FFF 아키텍처를 도입함으로써 기존 피드 포워드 신경망에서 사용하던 DMM을 위한 하드웨어 및 소프트웨어를 최적화할 수 있다.
또 FFF 네트워크를 기반으로 구현된 CMM을 통해 DMM에 비해에 추론 속도가 78배 향상됐다는 결과도 얻었다. 연구진은 더 뛰어난 하드웨어와 낮은 수준의 알고리즘으로 구현할 경우, 추론 속도가 300배 이상 향상될 가능성이 있다고 설명했다.
연구진은 “이 연구는 LLM의 메모리 및 컴퓨팅 병목 현상을 해결, 보다 간소화되고 효율적인 언어 모델을 위한 길을 열어줄 것”이라고 말했다.
이처럼 최근 LLM에 대한 연구는 효율성 향상으로 비용과 시간을 절감하는 쪽에 초점이 맞춰지고 있다.
지난주에는 스탠포드 대학교와 UC 버클리 대학교 연구진이 단일 GPU에서 수백 또는 수천개의 모델을 실행할 수 있도록 해주는 LLM 미세조정 기술 ‘S–로라(S-LoRA)’를 공개했다.
마이크로소프트(MS)가 지난주 발표한 경량 언어모델(sLLM) ‘오르카 2(Orca 2)’도 70억 및 130억개의 매개변수에 불과하지만, 더 큰 대형언어모델(LLM) 보다 뛰어난 추론 능력을 보이는 장점을 가지고 있다.
박찬 기자 cpark@aitimes.com