
테크크런치는 13일(현지시간) 스태빌리티 AI가 디퓨전)Diffusion) 모델에 기반한 음악 생성 AI 모델 ‘스테이블 오디오’를 출시한다고 소개했다.
이에 따르면 스테이블 오디오는 최대 95초 길이의 고품질 44.1kHZ 음악이나 음향 효과 오디오를 생성할 수 있다. 약 12억개 매개변수로 구성, 이전의 음악 생성기인 ‘댄스 디퓨전’보다 오디오 품질과 길이를 효과적으로 조절할 수 있다.
스테이블 오디오는 이미지 생성 AI인 스테이블 디퓨전을 구동하는 것과 동일한 ‘확산(디퓨전) 모델’을 사용한다. 이는 의도적으로 오류를 도입한 훈련 데이터셋으로 구축한 신경망으로, 노이즈를 줄여가면서 의미있는 오디오 파일을 생성하는 방식이다.
일반적으로 확산 모델은 생성하는 오디오 클립의 크기가 한정된다. 즉 30초 사운드 클립으로 훈련한 AI는 40초나 20초짜리 파일을 생성할 수 없다. 이 문제를 해결하기 위해 스테이블 오디오는 ‘잠재 확산(latent diffusion)’으로 알려진 특수 확산 모델을 사용한다.
잠재 확산 모델은 ‘오토인코더(autoencoder)’라는 신경망을 함께 사용, 불필요한 정보를 제거한 훈련 데이터셋을 사용한다. 정제를 통해 데이터셋의 품질을 높였기 때문에, 이를 학습한 잠재 확산 모델은 큰 용량의 고품질 결과물을 생성할 수 있다.
스테이블 오디오의 핵심 구성 요소는 9억700만개의 매개 변수를 가진 잠재 확산 모델 ‘U-넷(U-Net)’이다. 1만9500시간의 오디오를 포함한 파일 80만개 이상을 학습했다. 또 텍스트 기반 메타데이터와 상황별 정보를 추가, AI 훈련 프로세스를 최적화했다.
이를 통해 엔비디아의 ‘A100’ GPU에서 44.1kHz 샘플링 속도로 95초의 오디오를 1초 안에 생성할 수 있다.
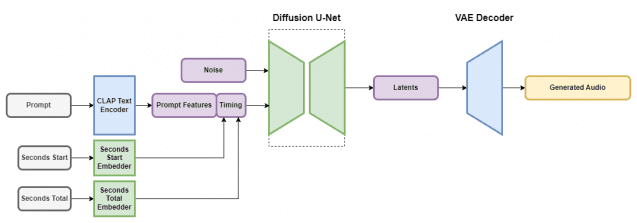
스테이블 오디오의 핵심 구성 요소는 9억700만개의 매개 변수를 가진 잠재 확산 모델 ‘U-넷(U-Net)’이다. 1만9500시간의 오디오를 포함한 파일 80만개 이상을 학습했다. 또 텍스트 기반 메타데이터와 상황별 정보를 추가, AI 훈련 프로세스를 최적화했다.
이를 통해 엔비디아의 ‘A100’ GPU에서 44.1kHz 샘플링 속도로 95초의 오디오를 1초 안에 생성할 수 있다.
스태빌리티 AI는 앞으로 오디오 생성 모델과 훈련용 데이터셋을 개선할 계획이다. 또 스테이블 오디오를 기반으로 하는 오픈소스 모델도 출시할 예정이다.
한편 스태빌리티 AI는 대표 제품인 이미지 생성 모델 ‘스테이블 디퓨전’에 이어 노래와 음향효과를 생성하는 ‘댄스 디퓨전’, 텍스트와 코드를 생성하는 언어모델 ‘스테이블LM’, AI 챗봇 ‘스테이블비쿠냐’, 텍스트 생성 대형언어모델(LLM) ‘프리윌리’, 코드 생성 LLM ‘스테이블코드’ 등 1년새 6개의 생성 AI 모델을 내놓는 등 전방위로 확장하고 있다.
특히 스테이블 오디오는 상업용으로 먼저 공개, 매출에 집중하는 것으로 알려졌다.
이 회사는 지난해 여름 스테이블 디퓨전을 오픈 소스로 출시, 10억달러(약 1조3000억원)의 기업가치로 1억100만달러(약 1320억원)의 투자를 유치하며 단번에 유니콘 반열에 올랐다.
하지만 이후 별다른 수익을 올리지 못한 데다 저작권 소송과 임금 체불, CEO 논란 등을 겪으며, 최근 투자 유치에 어려움을 겪는 것으로 알려졌다.
박찬 기자 cpark@aitimes.com