
DCGAN: The Art of Generating Lifelike Human Faces

Generative Adversarial Networks (GANs) have revolutionised the sphere of image generation, and the Deep Convolutional GAN (DCGAN) architecture has proven to be particularly effective in generating lifelike human faces. In this text, we are going to explore the principles and dealing of DCGANs, discuss the important thing components of the architecture, and delve into the technique of generating human faces using DCGANs. By the top of this text, you’ll have a comprehensive understanding of how DCGANs might be used to create highly realistic images.
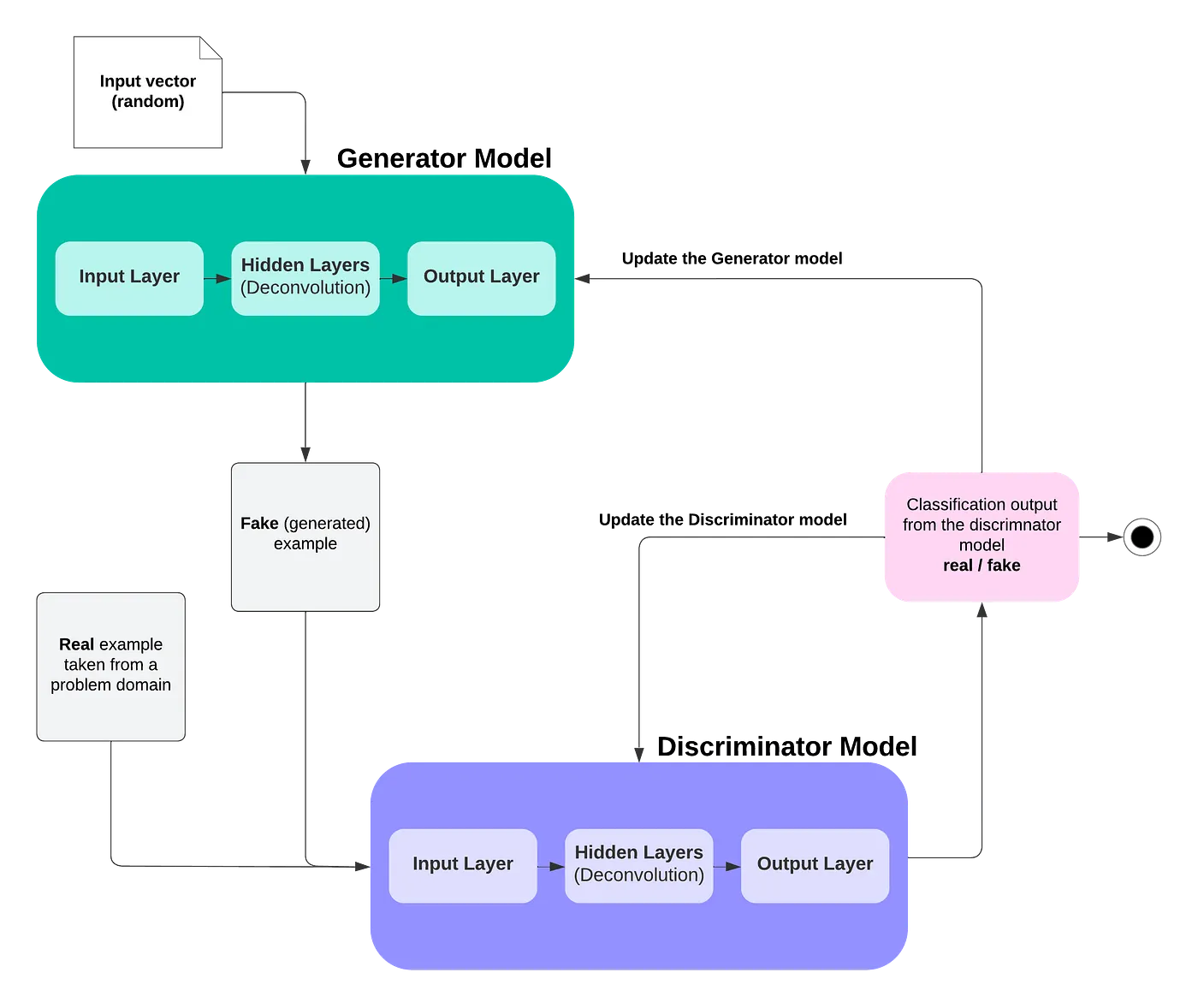
DCGANs are a variety of GAN architecture that employ deep convolutional layers with the intention to generate high-quality images. GANs consist of two primary components — the discriminator and the generator. The discriminator learns to differentiate between real and faux images, while the generator learns to create realistic images to idiot the discriminator. This adversarial training process results in the development of each the discriminator and the generator over time.
DCGANs leverage the ability of convolutional neural networks (CNNs) to extract meaningful features from images. Convolutional layers are used to perform convolutions on the input data, allowing the network to learn the important thing features of the photographs. Transposed convolutional layers, also often known as deconvolutional layers, are utilized in the generator to upsample the input noise vector and transform it into a picture.

The DCGAN architecture consists of multiple convolutional and transposed convolutional layers, together with other components akin to activation functions and batch normalisation layers. Let’s take a more in-depth have a look at each of those components:
Convolutional layers play an important role in DCGANs as they allow the network to extract meaningful information from the input data. These layers apply filters, also often known as kernels, to the input data and produce convolved features. By stacking multiple convolutional layers, the network can learn increasingly complex features and capture the essence of the photographs.
Transposed convolutional layers, also often known as deconvolutional layers, are utilized in the generator to upsample the input noise vector and transform it into a picture. These layers apply filters to the input data and produce output feature maps with larger dimensions. By progressively increasing the size of the feature maps, the generator is capable of generate images with the specified resolution.
Activation functions introduce non-linearity into the network and help to capture complex patterns in the info. In DCGANs, activation functions akin to ReLU (Rectified Linear Unit) are commonly used. ReLU applies the function max(0, x) to the input, effectively setting negative values to zero and preserving positive values.
Batch normalization is a method used to enhance the soundness and performance of neural networks. It normalizes the activations of the network by adjusting and scaling them to have zero mean and unit variance. This helps to forestall the network from getting stuck in saturation regions and accelerates the training process.
Training a DCGAN involves a two-step process: training the discriminator and training the generator. The discriminator is trained on a dataset of real images and faux images generated by the generator. Its objective is to appropriately classify the actual and faux images. The generator is trained to generate images that idiot the discriminator, making it imagine that they’re real.

Through the training process, the generator and discriminator are updated iteratively, with the generator attempting to improve its ability to generate realistic images and the discriminator attempting to improve its ability to differentiate between real and faux images. This adversarial training process continues until each the generator and discriminator have reached a state of equilibrium, where the generator is able to generating highly realistic images. The code of might be found here.
To generate lifelike human faces with DCGAN, we’d like a dataset of real human faces to coach the network. The dataset must be diverse and representative of the specified output. Once the network is trained on the dataset, we are able to input random noise vectors into the generator and procure synthesised images of human faces because the output.
The standard of the generated faces depends upon various aspects, including the complexity of the dataset, the architecture of the DCGAN, and the training process. With careful tuning and optimisation, it is feasible to attain highly realistic and visually appealing results.

While DCGANs have achieved remarkable success in generating lifelike human faces, there are still challenges to beat and avenues for improvement. A few of the challenges include the generation of diverse and novel faces, handling variations in pose and expression, and addressing biases present within the training data.
In the longer term, researchers are exploring techniques akin to conditional GANs, which permit for more control over the generated images by conditioning the generator on additional information. Moreover, the usage of more advanced architectures, akin to StyleGAN, can further enhance the standard and realism of the generated faces.
DCGANs have revolutionised the sphere of image generation, particularly within the domain of generating lifelike human faces. By leveraging deep convolutional layers, these networks are capable of manufacturing highly realistic and visually appealing images. The adversarial training process between the generator and discriminator results in continuous improvement and refinement of the generated images. With further advancements and research, DCGANs hold the potential to turn out to be much more powerful and versatile tools for image generation.
jazz relaxing music