
Have you ever ever been given the responsibility of analysing a great quantity of knowledge, but found it difficult to understand and extract meaningful insights from it? As data collection continues to grow, so does the variety of features or dimensions that have to be analysed. Nonetheless, with an increasing variety of features, a recent problem arises- . This phenomenon poses a big challenge for data scientists and machine learning algorithms, resulting in poor performance and inaccurate evaluation. In this text, we’ll explore the curse of dimensionality and its impact on high-dimensional data evaluation, in addition to the techniques that may also help overcome it.
Demystifying the Curse of Dimensionality
The curse of dimensionality is the challenge of precisely modelling and analysing high-dimensional data. This will be observed in various fields corresponding to numerical evaluation, sampling, combinatorics, machine learning, data mining, and databases. For now, Let’s delve into the implications of the curse of dimensionality when it arises in the sector of machine learning.
1. Hughes Phenomenon
As, the dimensionality of knowledge increases, the number of knowledge points to perform a very good classification model increases exponentially. With a rise in dimensions, data tends to grow to be more sparse, making it difficult to construct a generalized model. To enhance the model’s generalization, more training data could also be obligatory.
The Hughes Phenomenon states that, if the training data size is fixed, the performance of a classifier increases with the variety of features as much as a certain point, but beyond this optimal number, adding more features of the identical size because the training set can actually harm and degrade the classifier’s performance.
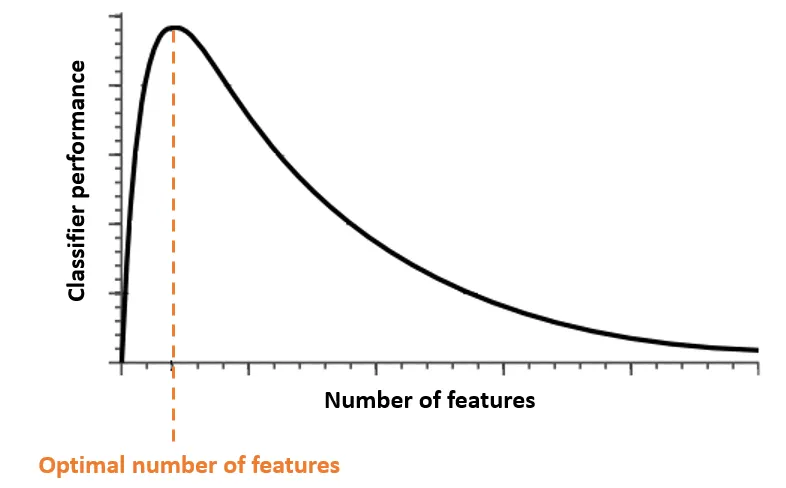
2. Distance Functions

The curse of dimensionality may also affect distance functions utilized in machine learning and data evaluation. Because the variety of dimensions increases, the gap between any two data points becomes larger, and this could cause distance-based algorithms to perform poorly. The sparsity of knowledge in high-dimensional space implies that even the nearest neighbors of a given point could also be distant, making it difficult to accurately cluster or classify data points. This may result in inaccurate predictions and decreased performance in distance-based algorithms.
Due to this fact, careful consideration should be taken when selecting a distance function for high-dimensional data to mitigate the results of the curse of dimensionality.
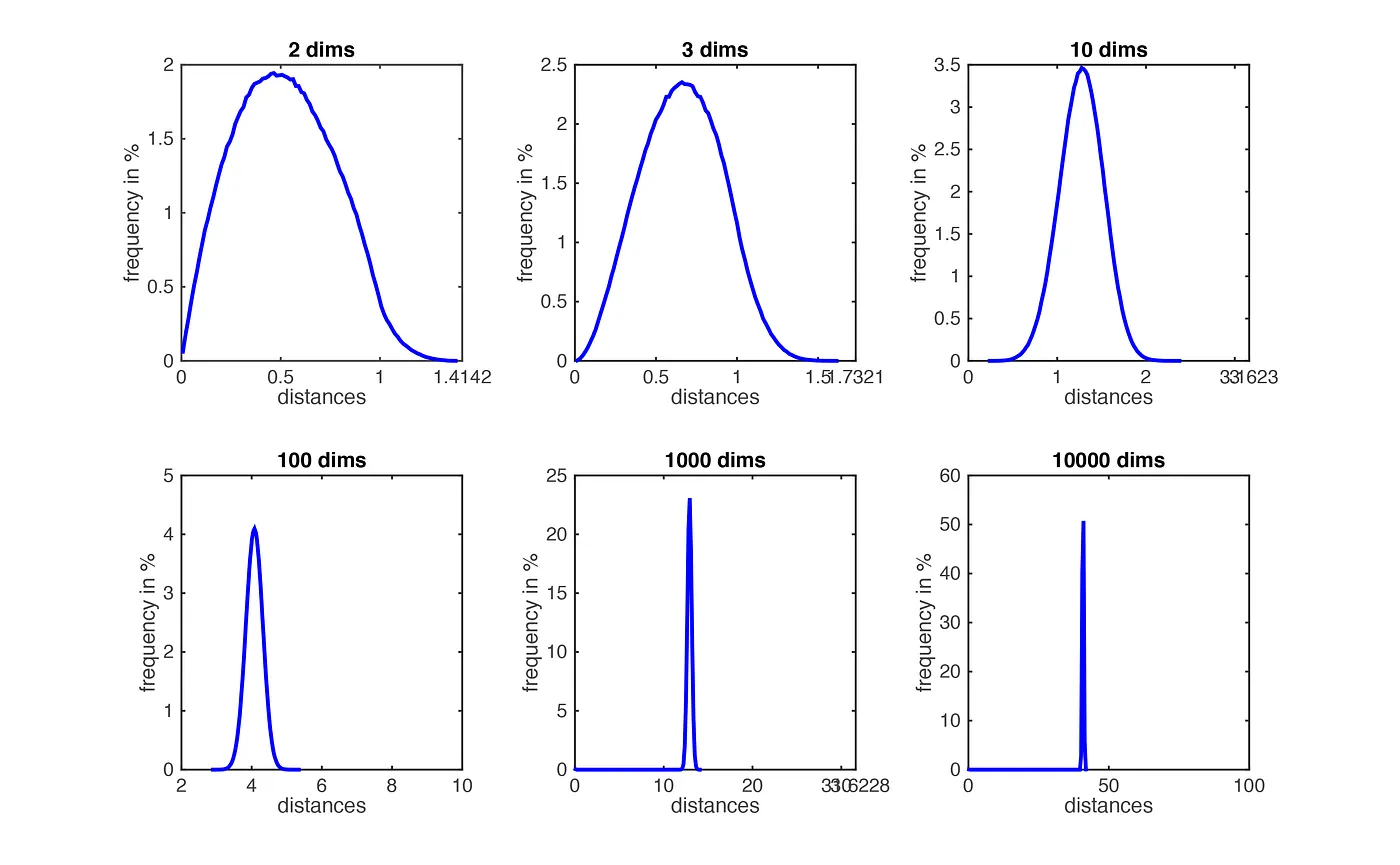
How does the curse of dimensionality affects K-Nearest Neighbors algorithm?
Because the dimensionality increases and the Euclidean distance function is used, the curse of dimensionality becomes apparent within the K-Nearest Neighbors algorithm. This results in decreased interpretability of the model and increased run-time complexity, making it unsuitable for low-latency applications.
: (i) Provided that an appropriate distance measure is chosen for a given problem(eg; cosine similarity for higher dimensional text data), the KNN algorithm will perform well.
3. Overfitting
Let’s proceed discussing the K-Nearest Neighbors Algorithm. It’s observed that the KNN algorithm is more prone to be overfitted as a result of the curse of dimensionality and sparsity attributable to the high-dimensional training data. Regularization is one method to avoid overfitting. Nonetheless, in models where regularization shouldn’t be applicable, corresponding to decision trees and KNN.
: We will use forward feature selection to choose essentially the most useful subset of features using class labels and dimensionality reduction techniques like Principal Component Evaluation (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) to assist us avoid the curse of dimensionality. Dimensionality reduction shouldn’t be a classification-oriented technique, slightly they struggle to choose the features based on co-variance and the proximity distance amongst them.
The curse of dimensionality can affect three key areas: the quantity of knowledge we want, distance functions, and overfitting. To cut back its impact, we will implement alternative distance functions and employ techniques for dimensionality reduction.
Hope this helps! Looking forward to sharing one other charming article with you within the near future!
You can too connect with me on Linked In: https://www.linkedin.com/in/anupama-k-79770b17a/
relaxing music
bahis oyna para kazan http://www.aviatorace.com
yapılan büyüyü bozmak için http://www.medyumnazar.com