
Resulting from its vast potential and commercialization opportunities, particularly in gaming, broadcasting, and video streaming, the Metaverse is currently one among the fastest-growing technologies. Modern Metaverse applications utilize AI frameworks, including computer vision and diffusion models, to boost their realism. A big challenge for Metaverse applications is integrating various diffusion pipelines that provide low latency and high throughput, ensuring effective interaction between humans and these applications.
Today’s diffusion-based AI frameworks excel in creating images from textual or image prompts but fall short in real-time interactions. This limitation is especially evident in tasks that require continuous input and high throughput, corresponding to video game graphics, Metaverse applications, broadcasting, and live video streaming.
In this text, we’ll discuss StreamDiffusion, a real-time diffusion pipeline developed to generate interactive and realistic images, addressing the present limitations of diffusion-based frameworks in tasks involving continuous input. StreamDiffusion is an revolutionary approach that transforms the sequential noising of the unique image into batch denoising, aiming to enable high throughput and fluid streams. This approach moves away from the standard wait-and-interact method utilized by existing diffusion-based frameworks. Within the upcoming sections, we’ll delve into the StreamDiffusion framework intimately, exploring its working, architecture, and comparative results against current state-of-the-art frameworks. Let’s start.
Metaverse are performance intensive applications as they process a considerable amount of data including texts, animations, videos, and pictures in real-time to supply its users with its trademark interactive interfaces and experience. Modern Metaverse applications depend on AI-based frameworks including computer vision, image processing, and diffusion models to realize low latency and a high throughput to make sure a seamless user experience. Currently, a majority of Metaverse applications depend on reducing the occurrence of denoising iterations to make sure high throughput and enhance the appliance’s interactive capabilities in real-time. These frameworks go for a standard strategy that either involves re-framing the diffusion process with neural ODEs (Abnormal Differential Equations) or reducing multi-step diffusion models into just a few steps or perhaps a single step. Although the approach delivers satisfactory results, it has certain limitations including limited flexibility, and high computational costs.
However, the StreamDiffusion is a pipeline level solution that starts from an orthogonal direction and enhances the framework’s capabilities to generate interactive images in real-time while ensuring a high throughput. StreamDiffusion uses an easy strategy through which as an alternative of denoising the unique input, the framework batches the denoising step. The strategy takes inspiration from asynchronous processing because the framework doesn’t should wait for the primary denoising stage to finish before it will possibly move on to the second stage, as demonstrated in the next image. To tackle the difficulty of U-Net processing frequency and input frequency synchronously, the StreamDiffusion framework implements a queue technique to cache the input and the outputs.
Although the StreamDiffusion pipeline seeks inspiration from asynchronous processing, it is exclusive in its own way because it implements GPU parallelism that enables the framework to utilize a single UNet component to denoise a batched noise latent feature. Moreover, existing diffusion-based pipelines emphasize on the given prompts within the generated images by incorporating classifier-free guidance, because of this of which the present pipelines are rigged with redundant and excessive computational overheads. To make sure the StreamDiffusion pipeline don’t encounter the identical issues, it implements an revolutionary RCFG or Residual Classifier-Free Guidance approach that uses a virtual residual noise to approximate the negative conditions, thus allowing the framework to calculate the negative noise conditions within the initial stages of the method itself. Moreover, the StreamDiffusion pipeline also reduces the computational requirements of a standard diffusion-pipeline by implementing a stochastic similarity filtering strategy that determines whether the pipeline should process the input images by computing the similarities between continuous inputs.
The StreamDiffusion framework is built on the learnings of diffusion models, and acceleration diffusion models.
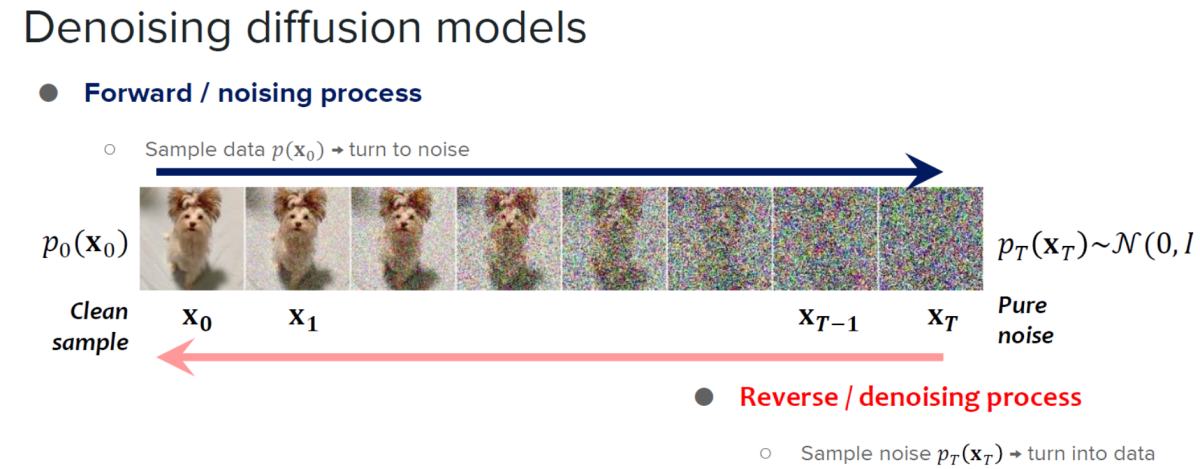
Diffusion models are known for his or her exceptional image generation capabilities and the quantity of control they provide. Owing to their capabilities, diffusion models have found their applications in image editing, text to image generation, and video generation. Moreover, development of consistent models have demonstrated the potential to boost the sample processing efficiency without compromising on the standard of the photographs generated by the model that has opened recent doors to expand the applicability and efficiency of diffusion models by reducing the variety of sampling steps. Although extremely capable, diffusion models are likely to have a significant limitation: slow image generation. To tackle this limitation, developers introduced accelerated diffusion models, diffusion-based frameworks that don’t require additional training steps or implement predictor-corrector strategies and adaptive step-size solvers to extend the output speeds.
The distinguishing factor between StreamDiffusion and traditional diffusion-based frameworks is that while the latter focuses totally on low latency of individual models, the previous introduces a pipeline-level approach designed for achieving high throughputs enabling efficient interactive diffusion.
StreamDiffusion : Working and Architecture
The StreamDiffusion pipeline is a real-time diffusion pipeline developed for generating interactive and realistic images, and it employs 6 key components namely: RCFG or Residual Classifier Free Guidance, Stream Batch strategy, Stochastic Similarity Filter, an input-output queue, model acceleration tools with autoencoder, and a pre-computation procedure. Let’s discuss these components intimately.
Stream Batch Strategy
Traditionally, the denoising steps in a diffusion model are performed sequentially, leading to a major increase within the U-Net processing time to the variety of processing steps. Nonetheless, it is important to extend the variety of processing steps to generate high-fidelity images, and the StreamDiffusion framework introduces the Stream Batch technique to overcome high-latency resolution in interactive diffusion frameworks.
Within the Stream Batch strategy, the sequential denoising operations are restructured into batched processes with each batch corresponding to a predetermined variety of denoising steps, and the variety of these denoising steps is set by the scale of every batch. Because of the approach, each element within the batch can proceed one step further using the only passthrough UNet within the denoising sequence. By implementing the stream batch strategy iteratively, the input images encoded at timestep “t” may be transformed into their respective image to image results at timestep “t+n”, thus streamlining the denoising process.
Residual Classifier Free Guidance
CFG or Classifier Free Guidance is an AI algorithm that performs a number of vector calculations between the unique conditioning term and a negative conditioning or unconditioning term to boost the effect of original conditioning. The algorithm strengthens the effect of the prompt despite the fact that to compute the negative conditioning residual noise, it’s obligatory to pair individual input latent variables with negative conditioning embedding followed up by passing the embeddings through the UNet at reference time.
To tackle this issue posed by Classifier Free Guidance algorithm, the StreamDiffusion framework introduces Residual Classifier Free Guidance algorithm with the aim to scale back computational costs for extra UNet interference for negative conditioning embedding. First, the encoded latent input is transferred to the noise distribution through the use of values determined by the noise scheduler. Once the latent consistency model has been implemented, the algorithm can predict data distribution, and use the CFG residual noise to generate the following step noise distribution.
Input Output Queue
The key issue with high-speed image generation frameworks is their neural network modules including the UNet and VAE components. To maximise the efficiency and overall output speed, image generation frameworks move processes like pre and post processing images that don’t require additional handling by the neural network modules outside of the pipeline, post which they’re processed in parallel. Moreover, by way of handling the input image, specific operations including conversion of tensor format, resizing input images, and normalization are executed by the pipeline meticulously.
To tackle the disparity in processing frequencies between the model throughput and the human input, the pipeline integrates an input-output queuing system that allows efficient parallelization as demonstrated in the next image.
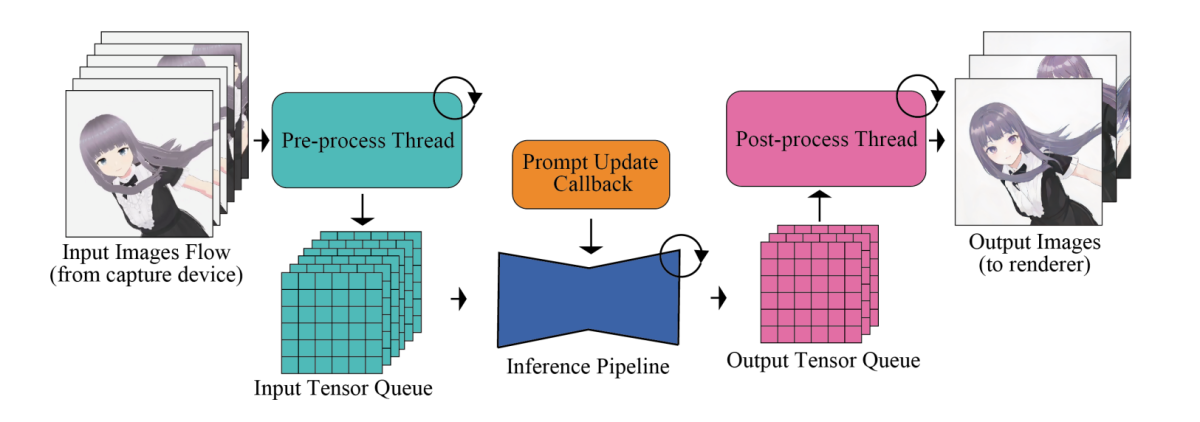
The processed input tensors are first queued methodically for Diffusion models, and through each frame, the model retrieves probably the most recent tensor from the input queue, and forwards the tensor to the VAE encoder, thus initiating the image generation process. At the identical time, the tensor output from the VAE decoder is fed into the output queue. Finally, the processed image data is transmitted to the rendering client.
Stochastic Similarity Filter
In scenarios where the photographs either remain unchanged or show minimal changes with no static environment or without lively user interaction, input images resembling one another are fed repeatedly into UNet and VAE components. The repeated feeding results in generation of near equivalent images and extra consumption of GPU resources. Moreover, in scenarios involving continuous inputs, unmodified input images might surface occasionally. To beat this issue and stop unnecessary utilization of resources, the StreamDiffusion pipeline employs a Stochastic Similarity Filter component in its pipeline. The Stochastic Similarity Filter first calculates the cosine similarity between the reference image and the input image, and uses the cosine similarity rating to calculate the probability of skipping the following UNet and VAE processes.
On the premise of the probability rating, the pipeline decides whether subsequent processes like VAE Encoding, VAE Decoding, and U-Net needs to be skipped or not. If these processes are usually not skipped, the pipeline saves the input image at the moment, and concurrently updates the reference image to be utilized in the longer term. This probability-based skipping mechanism allows the StreamDiffusion pipeline to completely operate in dynamic scenarios with low inter-frame similarity whereas in static scenarios, the pipeline operates with higher inter-frame similarity. The approach helps in conserving the computational resources and likewise ensures optimal GPU utilization based on the similarity of the input images.
Pre-Computation
The UNet architecture needs each conditioning embeddings in addition to input latent variables. Traditionally, the conditioning embeddings are derived from prompt embeddings that remain constant across frames. To optimize the derivation from prompt embeddings, the StreamDiffusion pipeline pre-computed these prompt embeddings and stores them in a cache, that are then called in streaming or interactive mode. Inside the UNet framework, the Key-Value pair is computed on the premise of every frame’s pre-computed prompt embedding, and with slight modifications within the U-Net, these Key-Value pairs may be reused.
Model Acceleration and Tiny AutoEncoder
The StreamDiffusion pipeline employs TensorRT, an optimization toolkit from Nvidia for deep learning interfaces, to construct the VAE and UNet engines, to speed up the inference speed. To realize this, the TensorRT component performs quite a few optimizations on neural networks which can be designed to spice up efficiency and enhance throughput for deep learning frameworks and applications.
To optimize speed, the StreamDiffusion configures the framework to make use of fixed input dimensions and static batch sizes to make sure optimal memory allocation and computational graphs for a selected input size in an try and achieve faster processing times.
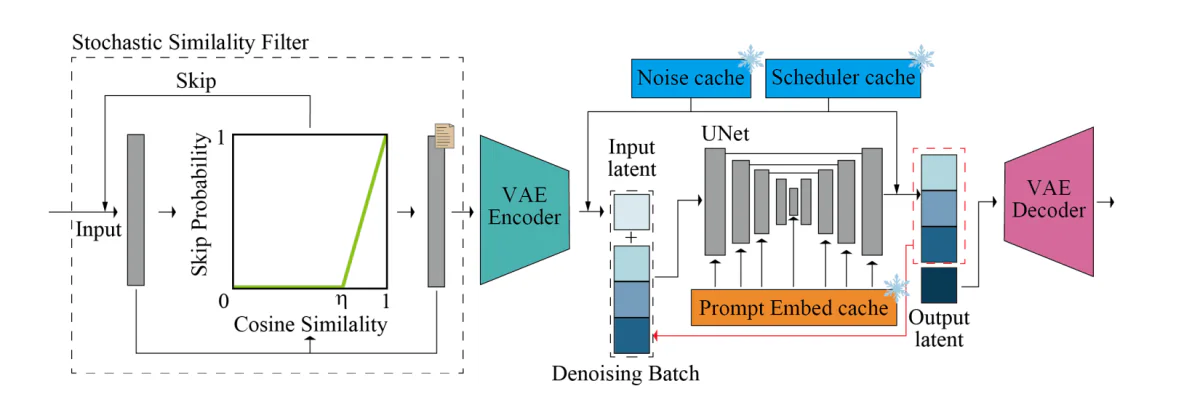
The above figure provides an outline of the inference pipeline. The core diffusion pipeline houses the UNet and VAE components. The pipeline incorporates a denoising batch, sampled noise cache, pre-computed prompt embedding cache, and scheduler values cache to boost the speed, and the flexibility of the pipeline to generate images in real-time. The Stochastic Similarity Filter or SSF is deployed to optimize GPU usage, and likewise to gate the pass of the diffusion model dynamically.
StreamDiffusion : Experiments and Results
To guage its capabilities, the StreamDiffusion pipeline is implemented on LCM and SD-turbo frameworks. The TensorRT by NVIDIA is used because the model accelerator, and to enable lightweight efficiency VAE, the pipeline employs the TAESD component. Let’s now have a have a look at how the StreamDiffusion pipeline performs in comparison against current state-of-the-art frameworks.
Quantitative Evaluation
The next figure demonstrates the efficiency comparison between the unique sequential UNet and the denoising batch components within the pipeline, and as it will possibly be seen, implementing the denoising batch approach helps in reducing the processing time significantly by almost 50% in comparison to the standard UNet loops at sequential denoising steps.
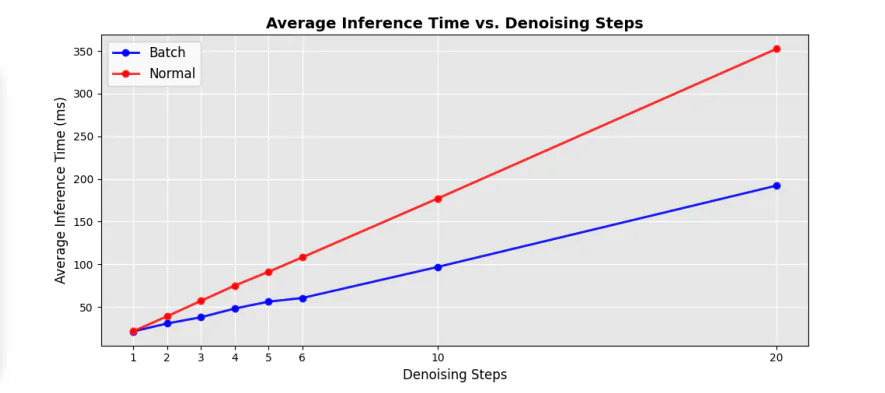
Moreover, the common inference time at different denoising steps also witnesses a considerable boost with different speedup aspects in comparison against current state-of-the-art pipelines, and the outcomes are demonstrated in the next image.

Moving along, the StreamDiffusion pipeline with the RCFG component demonstrates less inference time in comparison against pipelines including the standard CFG component.
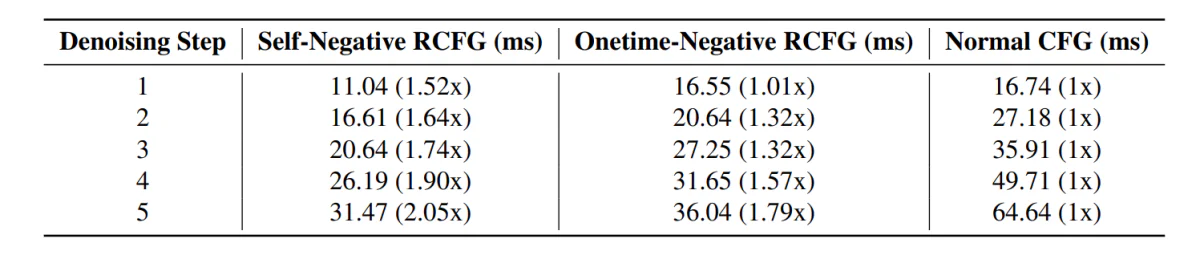
Moreover, the impact of using the RCFG component its evident in the next images in comparison to using the CFG component.

As it will possibly be seen, using CFG intesifies the impact of the textual prompt in image generation, and the image resembles the input prompts so much more in comparison to the photographs generated by the pipeline without using the CFG component. The outcomes improve further with using the RCFG component because the influence of the prompts on the generated images is kind of significant in comparison to the unique CFG component.
Final Thoughts
In this text, now we have talked about StreamDiffusion, a real-time diffusion pipeline developed for generating interactive and realistic images, and tackle the present limitations posed by diffusion-based frameworks on tasks involving continuous input. StreamDiffusion is an easy and novel approach that goals to remodel the sequential noising of the unique image into batch denoising. StreamDiffusion goals to enable high throughput and fluid streams by eliminating the standard wait and interact approach opted by current diffusion-based frameworks. The potential efficiency gains highlights the potential of StreamDiffusion pipeline for industrial applications offering high-performance computing and compelling solutions for generative AI.