
From food and shelter to self-actualization: Easy methods to use a scientific approach to create the foundations that support self-service analytics
I’ve been pondering back to the 90s, when self-service business intelligence (BI) tools like Business Objects and Cognos first rolled out. Heck, like all overly-enthusiastic software engineers, I even helped construct one in my temporary stint at Citigroup. At the moment, my youthful self made two very quick predictions:
- Excel is dead
- Self-service data goes to quickly take over
OK, so I’m not quite Nostradamus. After Citigroup, I discovered myself a decade right into a profession as a BI consultant — do some data engineering (ETL back then, not ELT), slap a BI tool on top, train business users, rinse and repeat. We arrange some “great stuff,” but gig after gig left one unsatisfying result:
Business users weren’t adopting the software and self-serving at the speed we expected.
A small percentage of “power users” (often on the tech side) would pick up the tools and create various levels of dashboards and reports, but there was no widespread adoption on the business side. And there remained a heavy dependency on consultants.
BI vendor sales pitch: 100% self-service data democracy
My expectation: 60–80% adoption
Reality: <20% adoption, optimistically
After some time, these projects began to feel like a̶n̶ ̶a̶b̶s̶o̶l̶u̶t̶e̶ ̶f̶a̶i̶l̶u̶r̶e̶ an awesome opportunity to learn. What was accountable? The tools, the users, IT, the consultants? We’re circa 2010 and there’s beginning to be loads of documentation of failed BI projects. Not “failed” in that projects never produced meaningful results, but failed in that they rarely reached their full potential. Business domains still had a heavy dependency on IT for data. Clean, trustworthy data was not quickly available.
An interesting thing happens at this cut-off date: an information visualization product called Tableau starts gaining widespread adoption. It’s in all places, and it’s the answer to data democracy. Then Power BI is available in to compete as a best-of-both-worlds data visualization and reporting tool. Nonetheless, a decade or more in, we still see the identical thing with these newer tools: abysmal self-service adoption of BI tools. Clearly, I’m not alone.
The worldwide BI adoption rate across all organizations is 26%. (360Suite 2021)
I couldn’t just sit on the sidelines. Naturally, I needed to create what the world all the time needed: the BI tool to resolve self-service. Yes, I’d finally get it right, I told myself. So I created FlexIt Analytics with that goal. Well, remember my predictions from earlier? Yep, again, I used to be very unsuitable. Let me get straight to the purpose:
There never was and never will probably be a single magical solution to creating data analytics accessible to the masses in a meaningful way.
No BI tool goes to resolve self-service. What we are able to do, nonetheless, is take a step back and think concerning the problem from a “big picture,” non-tech perspective, and maybe gain some useful insights and methods to maneuver forward.
Transport yourself back in time to highschool, if you happen to will, and take a look at to recall that invigorating Psychology lecture on human motivation. For those who didn’t cover this at school, or can’t remember, here’s a recap:
American psychologist Abraham Maslow proposed a theory of human motivation which argued that basic needs have to be satisfied before an individual can attain higher needs. As we move up the hierarchy, we move from lower-level short term needs like food and water to higher-level needs which have longer duration, are more complex, and increasingly difficult to achieve. The very best level is self-actualization and transcendence.
In a nutshell, you wish a basic foundation before you progress to the subsequent level. Anyone in the information world will immediately recognize this and understand that this is applicable on to achieving the “self-actualization of knowledge,” which is clearly “self-service.” Come on, they each have “self,” it will probably’t be a coincidence. Let’s dig in.
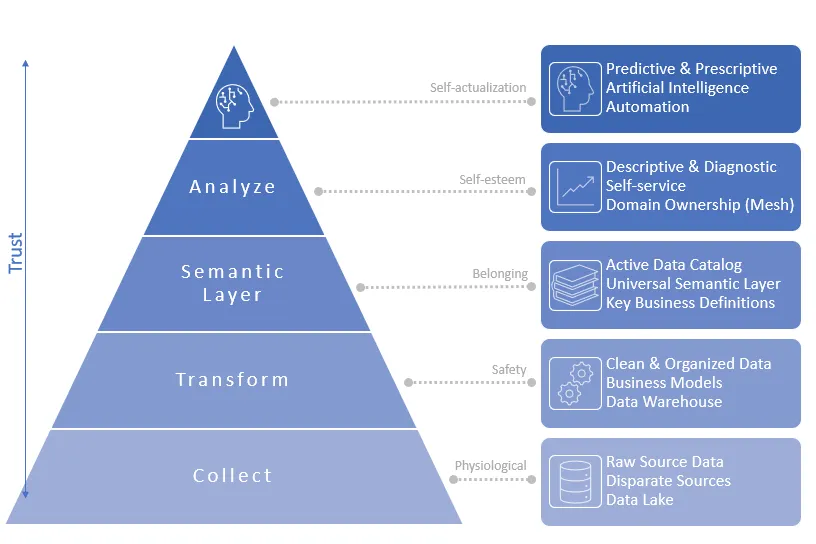
We’re going to indicate the identical image from the highest since it’s not only an Insta-worthy beaut of a graphic, but additionally extremely helpful in our upcoming evaluation. Like Maslow’s hierarchy, the Self-Service Data Analytics Hierarchy of Needs shows how each level supports and enables the extent above it. Moreover, you’ll see that the upper you go, more trust is each needed and delivered.
One More Time, DJ:
Collection
At the bottom, Maslow’s physiological needs are obvious: food, water, shelter. Likewise, the bottom level of the Self-Service Hierarchy of Needs is clear — data collection. It is advisable to have collected the information. Let’s take this a step further and say that your foundation needs to gather raw data from disparate sources. In the fashionable data world, that is the Extract and Load portion of ELT (Extract, Load, Transform), and ends in what we’ll call a Data Lake, for simplicity sake. Note the differentiation between the normal/older data warehousing concept of ETL (Extract -> Transform -> Load), that isn’t any longer relevant for a lot of reasons that we’ll cover in one other article.
The last point to make here is that any data evaluation produced from this level will have to be done by higher-skill analysts/data scientists, and has a lower level of trust in that it hasn’t undergone the upper levels of the hierarchy. The analogy can be something like this: are you able to skip right to the top-level transcendence? Possibly, but at the tip of the weekend when the party is over, it’s unlikely you’ll have the ability to sustain it.
Transformation
The following level in Maslow’s hierarchy is safety, which incorporates things like security, social stability, predictability, and control. In our Self-Service Hierarchy, we achieve that predictability, stability, and control by cleansing and organizing our data as business models in our data warehouse. This often takes the shape of multi-dimensional star schema models. With the raw source data from the lower Collection level, analysts might need to affix plenty of disparate tables together for customer data. On this level, that disparate data has been brought together in a typical table, called the Customer Dimension. Also on this process, data is cleaned (duplicate, mismatching names for a similar customer) and helpful calculations are pre-computed (e.g., first order date), allowing for much simpler SQL.
At the tip, we’ve established one other level of safety and trust in the information, but additionally enabled a recent group of analysts with self-service because they don’t have to know the business complexity of the underlying source data. Also very necessary to notice, at this level we must always see involvement from business domain owners. The transformation process is supposed to support real business needs, so business owners have to be involved. In the fashionable data world, we begin to see “analytic engineers” as a critical role to support this hybrid need.
Semantic Layer
Maslow’s third level is love and belonging through relationships and connectedness. The correlation with our Self-Service Hierarchy is uncanny, because the semantic layer is literally where you arrange your relationships (table joins), and is what brings all the pieces together. I could go on-and-on with semantic-layers, and do within the post linked here:
I’ll argue that this level is an important for enabling true self-service, and that business domain owners have to be heavily involved. The “universal semantic layer” can provide a single-source of truth that powers self-service analytics through data literacy, simplicity, and trust. Analysts can depend on business-friendly field and entity names, data catalog descriptions, and maybe most significantly, they don’t have to know the way tables join to one another (or at the least tips on how to write the SQL). We even have access to critical things like data lineage (trace a field back to the source table), synonyms (you call it “sales”, I call it “revenue”), and data freshness (when was the information last refreshed).
One necessary thing to notice here, especially for you historians who might say “Business Objects had this within the 90s.” We’ve not yet reached the “Evaluation layer” (BI tool level). For a lot of reasons, that are elaborated upon within the post linked above (“Semantic-free is the longer term of Business Intelligence”), it’s critical that you just don’t stuff your online business logic semantic layer right into a BI tool. The “semantic layer” level in our Self-Service Hierarchy should support the subsequent layer, not be it.
Evaluation
At this level, now we’re talking BI tools, reports, dashboards, and what most individuals take into consideration after we speak about self-service analytics. For those who found the semantic-layer correlation to Maslow’s hierarchy as uncanny as I did, then hold on to your seats for Maslow’s self-esteem level. Here, he breaks needs into “lower” version needs like status, recognition, fame, prestige, and a focus, in addition to “higher” version needs like strength, competence, mastery, self-confidence, independence, and freedom. Hello “data heroes,” “Zen Masters,” and gurus.
At this level in our Self-Service Hierarchy, we begin to see business domain ownership and self-service analytics, with a concentrate on two of the 4 kinds of analytics:
1. Descriptive — reports and dashboards that show what happened
2. Diagnostic — evaluation that shows why that happened
You’re constructing your dashboards from a clean data warehouse with a well-modeled transformation layer and universal semantic layer on top, right?
Paradoxically, it may be the BI tools that we thought were enabling self-service that were actually doing the most important disservice. We all know that Tableau (an incredible viz tool with enormous value, to be certain) gained early traction in bypassing slow-moving IT and selling on to the business, and continues to take advantage of this divide. Far too many implementations involve exporting data from hand-written SQL on source databases or static BI reports, and importing that .CSV into Tableau. While you possibly can decide to eat healthy at this all-you-can-eat buffet, the truth is usually quite different. The mess that ensues can often lavatory down businesses a lot that they are going to never reach the subsequent levels, in order that they proceed to supply only descriptive dashboards about things that happened.
Self-Actualization and Transcendence
The very best level of Maslow’s hierarchy is around self-fulfillment, personal growth, and reaching your full potential. Just like life, in the information world, there isn’t any pinnacle that you just reach and say “that’s it, all done.” It’s a continuing work-in-progress, very difficult to achieve, and may seemingly go on endlessly. At this level, we move beyond the fundamental descriptive and diagnostic analytics, and have established a really high level of trust in our data and process. This allows the subsequent two kinds of analytics:
3. Predictive — determining what is going to occur next
4. Prescriptive — based on predictions, recommend the optimal path forward
At this point, we’ve a robust foundation in all our layers of knowledge and may begin to make meaningful strides towards leveraging artificial intelligence, automating business processes, and tackling more advanced use-cases.
OK, so we’ve established a framework for improving our “data life,” with the lofty goal of knowledge self-actualization. Now, let’s dig in and determine how we get there. First, let’s take a take a look at what we want to concentrate on: people, process, and tools.

People
I come from the Tech side, so wish to create technical solutions to resolve business problems. Surely, if I get some business requirements, lock myself in a dark room, and bang out some code, then I can create a bit of software to reply the business needs. My mistake, and the error of many others, is a scarcity of concentrate on the softer side of things: people. This sounds obvious, but I believe us Tech folks have to admit that we regularly create incredible software products after which hand them to business users and say “Tada, here it’s!” We’re baffled when it’s not used the way in which we anticipated, or they “just don’t get it.”
The human side of technology might be baffling and mystifying, however it doesn’t have to be. On the core of this, we want to ascertain trust and competency by specializing in just a few key areas. First, there must be buy-in, otherwise the forces pushing against you possibly can derail even great technical solutions. With that, there must be serious collaboration with the concept we’re working toward a “business-driven” data solution relatively than a “data-driven” solution. Every part we do must be with the business needs in mind. As we construct, we want to take into consideration how we are able to enable competency in our delivered product. In the information world, how can we enable “data literacy?” Sure, the business should know their data, but after we put their business through the technical grinder after which present it back to them, it’s not all the time as obvious as we expect. We’d like to enable data-literacy with data catalogs and semantic layers. Finally, after we roll out our solutions, we are able to’t just do standard roll-out sessions and trainings that come off as lectures. We’d like to concentrate on “just-in-time” training that focuses on real data needs for the time being in time when a business user needs to resolve real data problems.
Process
Even when we get the people part right, we are able to still be easily derailed. To remain on the right track, we want to also get the method part right. One of the obvious issues up to now few many years, especially on the Tech side, is that many projects were undertaken with a waterfall approach, where the final result is purported to be established at first of the project. Our first step, especially in the information world where constructing our data-driven org can take a few years, is to be nimble and concentrate on the ever-changing business needs by taking an agile approach.
Agile was developed as a versatile method that welcomes incorporating changes of direction even late in the method, in addition to accounting for stakeholders’ feedback throughout the method. — Forbes
Certainly one of the massive mistakes of individuals doing “agile” is that they do a bunch of disparate sprint projects that don’t lead to a coherent end product. We will need to have an end goal in mind, even when we’re not taking a waterfall approach. There have to be standards and data governance in place to ensure we stay focused on this end goal. It’s also necessary that the business side owns their data, relatively than Tech. They have to be intimately involved on this process. Finally, the method must concentrate on continuous improvement. What’s working? What’s not working? Why? Then, go fix these and proceed to deliver.
Tools
Early on, we relied on the tools to be our magic solutions to our problems. As I established earlier, the tools usually are not the answer. They’re not even near 1/third of the answer. I believe it’s something like 50% People, 30% Process, and only 20% Tools. Being a BI tool provider, that’s a rough outlook. Nevertheless, it’s true.
With that being said, there are a handful of things the tools can do to enable the general people and process components. Clearly, they have to be intuitive in order that they don’t require deep knowledge of tips on how to use them, and I believe that loads of modern BI tools try this. Certainly one of the areas where I believe they’re lacking is within the “plug-and-play.” As I discussed earlier, we put an excessive amount of business logic in our tools, so switching from one tool to a different is a significant lift. Not to say the proven fact that many organizations have 3 or more BI tools, often accessing the identical datasets. What we want to do is take that business logic out of the BI tool and push it all the way down to a centralized semantic layer that each one BI tools can plug in to.
Moreover, our tools have to integrate with other tools relatively than attempt to be one monolithic do-it-all tool. That is one area that the “modern data stack” gets right, however it’s necessary that we don’t go too far the opposite way and have 100’s of tools that create a confusing and messy architecture. At the tip of the day, keep in mind that the tools are only here to support the people and process.
Now that we’ve established a framework and the general components of a data-driven organization, let’s speak about how we get there.

Step 1: Buy-in
First things first, it’s essential establish key stakeholders and get buy-in from the chief level. Without this, you risk lacking the “people-power” to deliver in your self-service framework and components. Getting widespread buy-in might be very difficult, so determine who might be the early champions. At the tip of those steps, you’ll start again at step 1, continuing to construct your data driven organization and getting more buy-in along the way in which. You’re going for a snowball effect here.
Step 2: Start Small
Continuing the snowball analogy, we’re constructing a snowman. With that, after all we start small and construct up. We’re pondering of the thing we’re constructing in components, and we take an agile approach, taking an agile approach to deliver on real business needs. We would like a “quick win” in our first iteration in order that we are able to compound on these positive results, getting more people bought in along the way in which.
Step 3: Construct Process
These agile “quick wins” are liable to creating wild-west messy architectures. For this reason we immediately establish standards and data governance, which offer a foundation and keep us laser focused on delivering quality, accurate and reliable data products. Tools like Github go a good distance in supporting our standards and data governance.
Step 4: Democratize
The info governance will allow us to more safely roll out these data products with more confidence and fewer risk. In democratizing our data, we want to:
- Eliminate data silos — these are “black-box” data sources controlled by one department, often Tech, and isolated from the broader organization.
- Construct data literacy — we cannot expect the business users to instantly understand the what IT is delivering, regardless that it’s their data. Data catalogs can go an extended strategy to support data literacy, but this might be tricky. Oftentimes, we find yourself with spreadsheet data dictionaries that get stale and wind up gathering dust. We’d like to maneuver to a more dynamic and lively data catalog that enables business users to take motion on the information catalog entities, in addition to provide feedback on definitions, etc. for continuous improvement.
- Construct trust — to democratize data, IT must trust that the business goes to make use of the information properly. The business must trust that IT goes to deliver accurate, reliable, and timely data. Every step of the way in which, trust must be established and maintained.
Step 5: Collaborate
Now that we’ve taken steps to democratize data, we want to ensure we’re collaborating and dealing together to develop solutions, but additionally to offer critical feedback that can improve things. It is vital to form some type of DART (Data Analytics and Reporting Team) group that has a cross section of members from tech to business and meets usually to work through issues.
Step 6: Evaluate
At the tip, we want to spotlight the win while also ensuring we constructively discuss things that didn’t work or must be improved. Without being too dogmatic, or making up KPI’s, we want to determine a strategy to measure success. Are people pleased with the outcomes from this primary iteration? Did we create an immediately useful data product? Then, we iterate and constantly improve on what worked and what didn’t work.
Then, rinse-and-repeat, start back at step 1 with more buy-in and a next results-driven project.
Putting all of it together, we covered three key areas to focus and create our data-driven organization and enable self-service. One very necessary thing to notice is that we usually are not going from zero self-service to a completely data-democratized organization. We’re attempting to move the needle, little by little, and constantly improve to enable more people within the organization to be involved in data. To recap, listed here are the 3 ways we are able to focus this effort:
- The Framework — a hierarchy of needs that may inform what we want to construct to enable a data-driven organization
- The Components — the components of this data-driven organization, namely the people, process, and tools.
- Steps to Create — a six step approach that focuses on these components to construct our data-driven organization throughout the framework.
Good luck in your self-service endeavors!
Please comment, I’d love to listen to your thoughts here, or reach out to Andrew Taft