
Rakuten has launched a big language model (LLM) trained on a large-scale Japanese dataset. The reason is that the tokenizer vocabulary was significantly increased to process complex Japanese characters, and the common rating was 68.74 within the benchmark. As such, the performance of Japanese models is rapidly improving recently.
AIM, a technology media outlet, recently reported that Rakuten is an LLM product line specializing in Japanese with 7 billion parameters. Rakuten AI-7B released as open sourceIt was reported that it was done.
Based on this, the inspiration model, RakutenAI-7B, learned a considerable amount of English and Japanese text data and was developed by repeatedly training on France's Mistral AI's open source model Gachoongchi.
Because Japanese comprises Chinese characters, its script structure is more complex than English or other languages. Accordingly, the tokenization process, which fragments text to suit the model, was inefficient and sometimes required additional support, making it difficult for foreign models resembling ChatGPT to perform well.
Subsequently, the researchers expanded the tokenizer vocabulary from 32,000 to 48,000 and improved the ratio of characters per token. It was explained that through this, the efficiency of processing complex Japanese characters was increased.
As well as, the standard of the training dataset was improved by utilizing strict data filtering technology. Through this, it was introduced that learning and performance were improved with 175 billion high-quality tokens.
Because of this, this model recorded a mean of 62.83 within the Japanese model evaluation benchmark harness, taking first place, ahead of the Japanese open source model by greater than 3 points. As well as, the 'RakutenAI-7B-Instruction' model that applied reinforcement learning scored 68.74 points, 2 points ahead of the opposite model (Youri-7B).
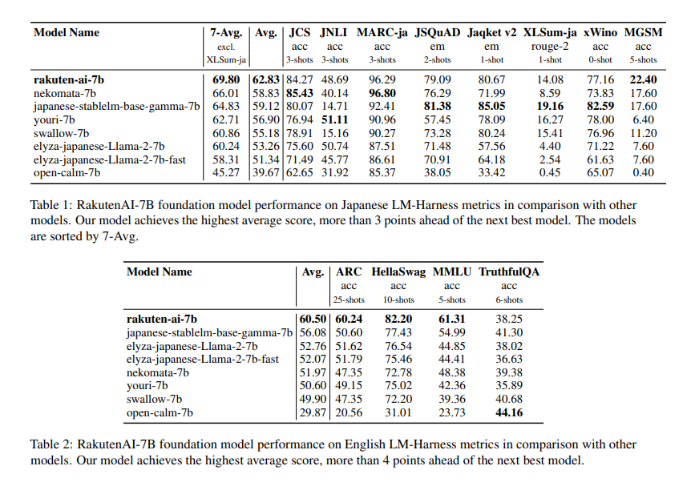
“With this model, we’ve reached vital performance milestones, and we’re excited to share what we’ve learned with the open source community and speed up the event of Japanese LLM,” said Ting Kai, Rakuten Group Chief Data Officer. “We now have the perfect tools available.” “I would like to make use of it to unravel corporate problems,” he said.
Meanwhile, in Japan, along with Rakuten, rapid progress is being made within the AI field led by large corporations resembling NTT, Fujitsu, NEC, and Mitsui.
NTT plans to launch an enterprise generative AI platform called 'Tsuzumi' this spring, specializing in Japanese language skills, while Fujitsu plans to make use of the Japanese supercomputer 'Fugaku' with Tokyo Institute of Technology, RIKEN, Tokyo Institute of Technology, etc. We’re developing an open source LLM with 30 billion parameters using '.
NEC also developed a Japanese LLM with 13 billion parameters, specializing in Japanese language efficiency. Mitsui collaborated with NVIDIA to launch 'Tokyo-1', a supercomputer that supports recent drug development through AI models.
Also, last week, Sakana AI, the creator of Google Transformer, unveiled the Japanese model 'EvoLLM-JP', which improved performance through model merge.
Reporter Park Chan cpark@aitimes.com