
An open source text embedding model has emerged that is alleged to have higher performance than OpenAI's 'text-embedding-ada-002', the perfect currently available. Through this, it’s evaluated that the open source large language model (LLM) has also found a chance to enhance its performance.
Mark Tech Post reported on the seventeenth (local time) that Nomic AI has launched an open source text embedding model, 'Nomic Embed.'
Embedding is a technique of expressing and storing various sorts of data, resembling images, audio files, and text documents, as numeric vectors. These vectors express semantic meaning and relationships between different data points. Within the context of language models, text embeddings capture the underlying meaning and context of words, sentences, and even entire documents.
Text embedding models play a vital role in Large Language Models (LLM) and Augmented Retrieval Generation (RAG). Semantic details about sentences or documents is encoded into low-dimensional vectors after which utilized in data visualization, information retrieval, sentiment evaluation, document classification, and various other natural language processing tasks. To construct an accurate and efficient language model, it is important to have a reliable and performant text embedding model.
Currently, probably the most widely used context text embedding model is OpenAI's 'Text-Embedding-Ada-002', which supports a context length of 8192 tokens. Nevertheless, the Ada model is closed source and the training data can’t be verified.
As well as, all embedding models released as open source to date haven’t reached the performance of OpenAI. This also contributed to the dearth of accuracy of open source models.
Nevertheless, nomic embed is a text embedding model with the identical context length of 8192 as OpenAI, and was developed using 'multi-level contrastive learning'. It undergoes multiple stages of coaching on a big collection of paired text data.
The model was first pre-trained using resources resembling BooksCorpus and the 2023 Wikipedia dump. It was then contrastively trained using an enormous collection of 470 million pairs, and at last fine-tuned using a smaller, curated dataset of pairwise data.
The nomic embed incorporates rotational position embedding (RPE) to accommodate prolonged sequence lengths, and flash attention functionality to enhance the model's capabilities inside a neural network architecture. As well as, a 16-bit precision binary neural network was used to optimize computational efficiency by reducing memory usage and increasing inference speed.
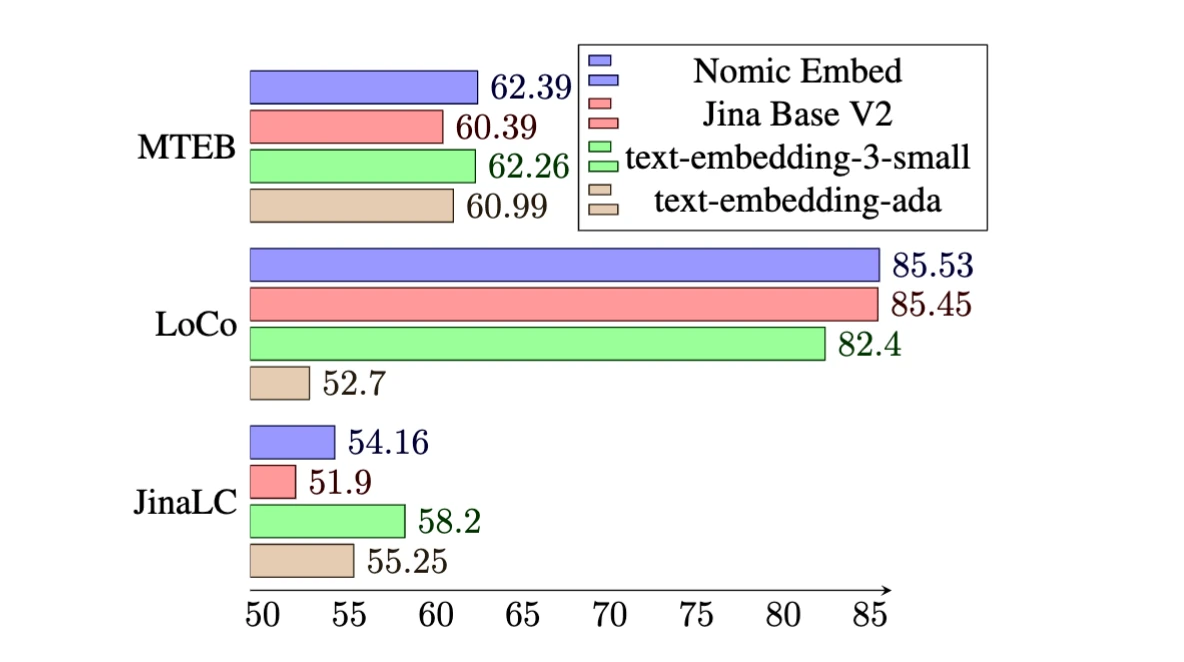
The primary version of nomic embed, 'nomicembed-text-v1', showed the perfect performance in large-scale text embedding benchmark (MTEB), LoCo benchmark, and Gina Long Context benchmark. Open AI's 'text-embedding-ada-002' 'text-embedding-3-small' 'jina-embedding-v2-base-en )' was found to surpass the performance of existing powerhouses resembling '.
Mark Tech Post evaluated, “Nomic Embed has achieved technical achievements in breaking down the entry barrier to open source in the sector of long-context text embedding.”
Reporter Park Chan cpark@aitimes.com