
인간처럼 실수를 통해 배우는 새로운 인공지능(AI) 학습 방법이 나왔다.
벤처비트는 3일(현지시간) 마이크로소프트(MS) 리서치 아시아와 북경대학교, 시안 자오퉁 대학교 등 연구진이 공동으로 인간처럼 실수를 통해 학습함으로써 대형언어모델(LLM)의 능력을 향상하는 기술 ‘르마(LeMa)’를 공개했다고 보도했다.
이에 따르면 연구진은 르마를 통해 AI가 스스로 실수를 바로잡도록 학습, 추론 능력을 향상할 수 있다고 주장했다.
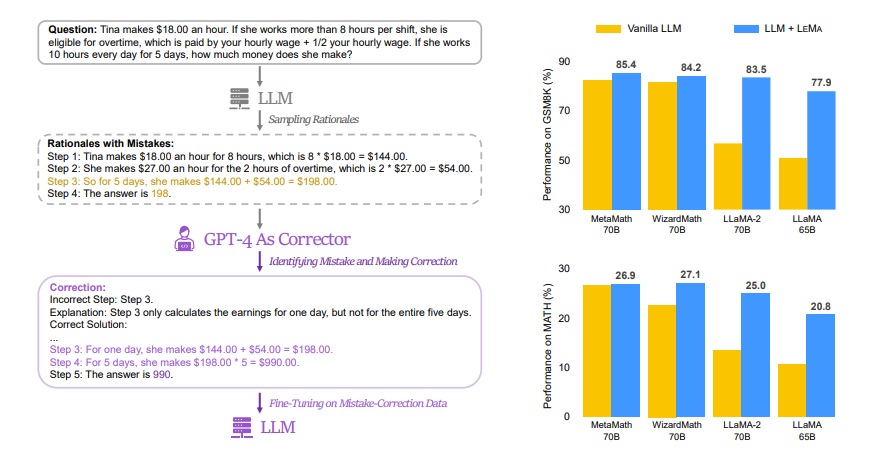
이 방식은 사람이 자신의 실수로부터 배워나가는 인간의 학습 과정을 따라한 것이다. 르마도 LLM을 통해 수식을 풀고, ‘GPT-4’로 생성한 오류 수정 데이터를 이용해 미세조정하는 방식을 적용했다.
연구원들은 먼저 메타의 오픈 소스 LLM인 ‘라마 2’와 같은 모델을 이용해 수학 문제에 대한 결함 있는 추론 경로를 생성하도록 만들고, 이어 GPT-4로 추론의 오류를 식별하고 이를 설명함으로써 올바른 추론 경로를 확인할 수 있도록 학습 과정을 구성했다.
이런 새로운 접근 방식은 5개의 백본 LLM과 2개의 수학적 추론 작업을 수행하는 르마가 단순히 단계별 추론을 위한 ‘연쇄적 사고(CoT)’ 데이터만 미세조정하는 방식에 비해 지속적인 성능 향상을 이룰 수 있었다고 밝혔다.
또 위자드매스(WizardMath)나 메타매스(MetaMath)와 같은 전문 LLM도 르마를 적용할 경우, 초등수학(GSM8K)에서 85.4%의 정확도, 수학에서 27.1%의 정확도를 달성할 수 있었다. 이런 결과는 기존 오픈 소스 모델이 달성한 최고 수준을 능가하는 결과다.
르마는 향후 수학뿐 아니라 오류 수정과 지속적인 학습이 중요한 의료나 금융, 자율주행 등 AI가 적용되는 다양한 분야에 적용될 수 있을 것으로 예상된다. 실수를 통해 학습하는 과정을 통해 복잡한 문제 해결에서도 AI가 인간 능력을 능가할 수 있을지도 모른다는 예상이다.
이번 연구에 사용된 코드와 데이터, 모델을 포함한 팀의 연구 결과는 깃허브(GitHub)에 공개됐다.
박찬 기자 cpark@aitimes.com