
A synthetic intelligence (AI) model able to recognizing and generating speech in greater than 1,000 languages has emerged.
On the twenty second (local time), meta opened ‘MMS (Massively Multilingual Speech)’, a speech recognition model that identifies greater than 4,000 speech languages and provides speech-to-text and text-to-speech conversion for greater than 1,100 languages through a blog. disclosed as a source.
Speech recognition remains to be one in every of the difficult areas in AI. MMS trained the MMS model on the Recent Testament audio data set in 4000 languages and the Recent Testament audio-text data set in greater than 1100 languages, providing a mean of 32 hours of knowledge per language.
The MMS model is a self-supervised learning called wav2vec 2.0, which is a technique of learning contextualized expressions and individual speech units together.
First, we pre-train a generic data representation on an unlabeled audio data set after which train to fine-tune the model on a labeled audio-text data set. In this manner, a speech recognition model will be trained with much less data.
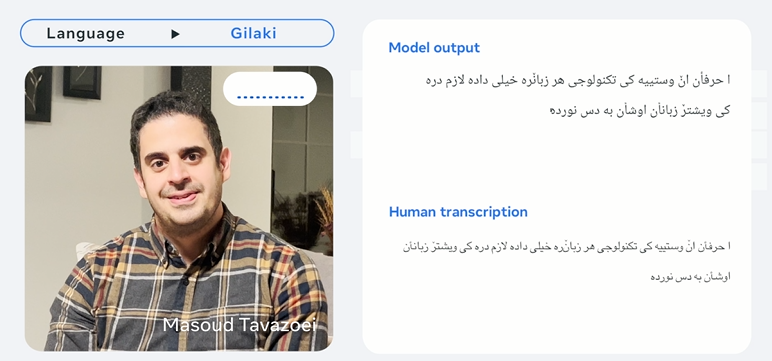
Meta claimed that the resulting models all performed well in comparison with other speech recognition models.
In keeping with the meta, the performance decreases because the variety of languages increases, but it is vitally marginal. Expanding from 61 to 1107 languages only increases the character error rate by about 0.4%, but increases language coverage by greater than 17 times.
In comparison with OpenAI’s ‘Whisper’, which is currently the most effective speech recognition model, the word error rate of the MMS model is half that of Whisper, but it surely processes 11 times more languages.
Meta is open-source sharing the MMS dataset and tools utilized by everyone within the AI research community to enhance and train models based on this work.
“The goal of MMS is to expand coverage to support more languages and improve dialect processing, a significant challenge for existing speech technologies,” Mehta said.
Reporter Park Chan cpark@aitimes.com
lofi
peaceful music