
오픈AI가 인공지능(AI)이 초래할 수 있는 위험을 완화하기 위해 내부 안전 프로세스를 대폭 강화했다. 특히 이사회가 안전 문제를 이유로 새 모델 출시를 거부할 경우 이를 받아들일 예정이다.
블룸버그는 18일(현지시간) 오픈AI가 AI 모델을 안전하게 개발하고 배포하기 위한 접근 방식을 다룬 ‘대비 프레임워크(Preparedness Framework)’를 발표하고, 개발 중인 프론티어 모델을 지속적으로 평가하고 위험을 모니터링하는 ‘대비(Preparedness)’ 팀을 조직했다고 보도했다.
이에 따르면 프레임워크는 오픈AI가 사이버 공격과 자율 무기 등에 사용될 수 있는 모델로 인해 발생하는 치명적인 위험을 추적, 평가, 예측 및 보호하는 방법을 설명한다.
프레임워크의 주요 구성 요소 중 하나는 모델의 기능, 취약성 및 영향과 같은 잠재적 피해에 대한 다양한 지표를 측정하고 추적하는 AI 모델에 대한 위험 ‘스코어카드’를 사용하는 것이다. 스코어카드는 정기적으로 업데이트되며 특정 위험 임계값에 도달하면 검토 및 개입이 시작된다.
이를 위해 오픈AI는 대비 팀을 구성, 사이버 공격과 화학, 핵, 생물학적 위협 등 수천억달러의 경제적 피해나 다수의 인명 피해를 초래할 수 있는 AI 내재 위험 가능성을 모니터링할 계획이다.
알렉산더 마드리 MIT 교수가 이끄는 이 팀은 AI 연구원과 컴퓨터 과학자, 국가 보안 전문가 및 정책 전문가 등으로 구성될 예정이다.
팀은 아직 출시되지 않은 프론티어 모델을 반복적으로 평가, 위험 등급을 ‘낮음’ ‘중간’ ‘높음’ 또는 ‘중요’ 순으로 매긴다. 프레임워크에 따르면 오픈AI는 ‘중간’ 또는 ‘낮음’ 등급의 모델만 출시할 수 있다.
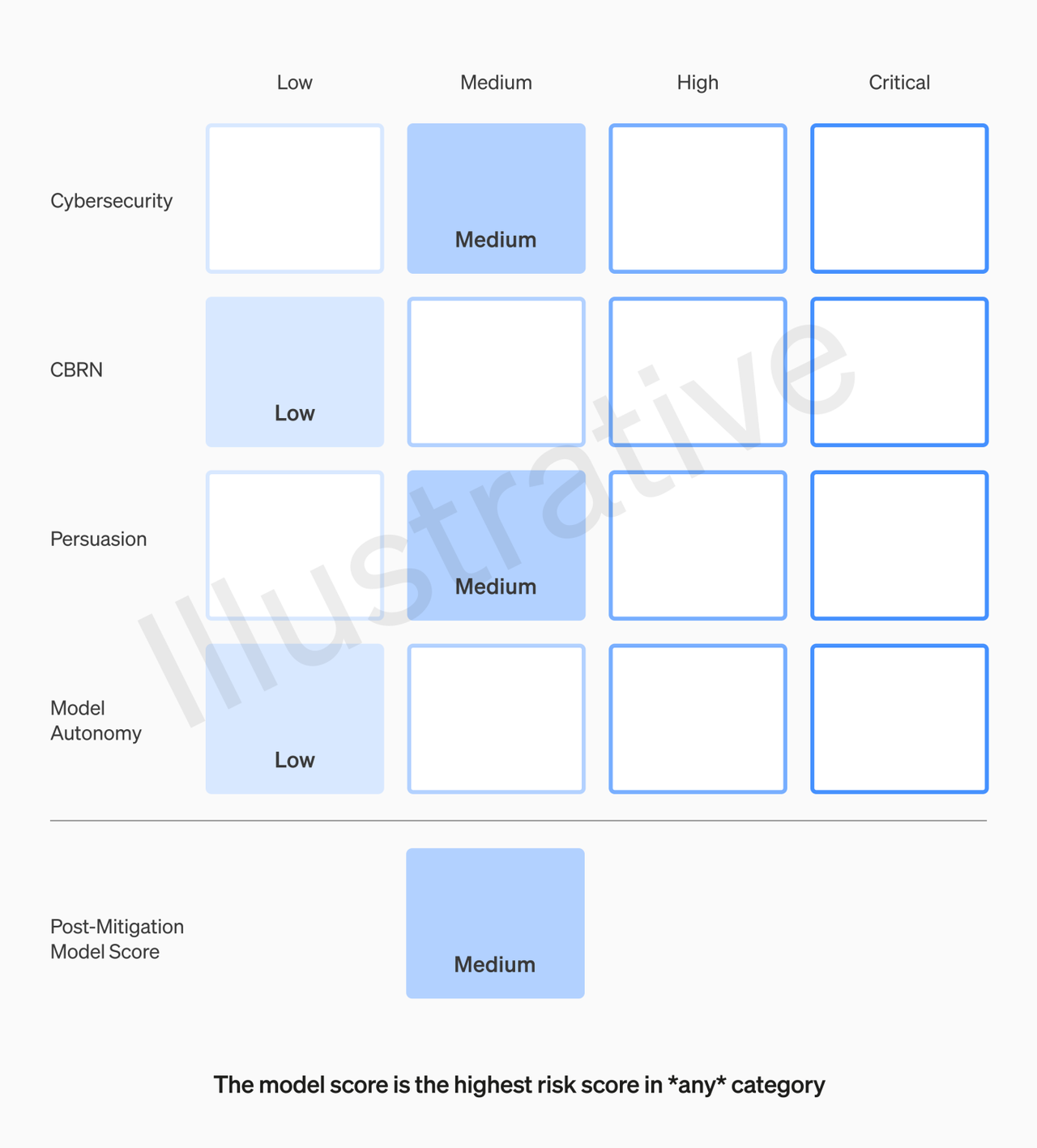
또 대비 팀은 AI 기술을 모니터링하고 지속적으로 테스트해, AI 능력이 위험치에 달했다고 판단하면 회사에 경고하게 된다.
오픈AI는 향후 오픈AI 경영진이 대비 팀의 보고서를 바탕으로 새로운 AI 모델을 출시할지 여부를 결정하게 된다고 밝혔다. 특히 경영진이 안전하다고 판단해 출시를 결정한다고 해도 이사회가 이를 거부할 수 있다고 설명했다.
이번 발표는 샘 알트만 CEO 퇴출 사태 이후 오픈AI의 이사회와 경영진 간 권력 균형에 관심이 모인 가운데 나왔다. 알트먼 CEO는 지난달 AI 안전에 대한 일부 이사진과의 의견차로 인해 퇴출됐다가 복귀에 성공했다.
한편 오픈AI에는 ‘대비’ 팀 외에도 최신 대규모언어모델(LLM) GPT-4와 같은 현재 제품의 안전을 검토하는 ‘안전 시스템(Safty Systems)’ 팀, 미래에 존재할 수 있는 강력하고 가상의 AI 시스템에 초점을 맞춘 ‘초정렬(Superalignment)’ 팀이 있다.
초정렬 팀은 지난주 인간 지능을 뛰어넘는 초지능(Superintelligence)을 제어하기 위한 첫번째 연구 결과를 발표해 화제가 됐다.
박찬 기자 cpark@aitimes.com