
목적에 맞게 미세조정한 수천개의 대형언어모델(LLM)을 단일 GPU에서 실행할 수 있는 기술이 나왔다. 이를 통해 LLM 미세조정 및 미세조정 모델 실행 비용을 획기적으로 줄일 수 있을 전망이다.
벤처비트는 최근 스탠포드 대학교와 UC 버클리 대학교 연구진이 미세조정한 LLM 배포와 관련된 비용을 대폭 줄여 단일 GPU에서 기업이 수백 또는 수천개의 모델을 실행할 수 있도록 해주는 기술 ‘S–로라(S-LoRA)’를 공개했다고 소개했다.
LLM 미세조정은 대량 데이터셋에 대해 초기 학습을 실행한 다음 맞춤형 데이터셋으로 다시 LLM을 훈련하는 것이다. 그러나 이 방식은 비용이 많이 들 수 있다. 이를 통해 미세조정 하려면 전체 모델뿐만 아니라 전체 모델의 모든 매개변수에 대한 그래디언트 도 저장할 수 있는 충분한 메모리가 필요하다. 그래디언트는 모델이 매개변수를 조정할 방향을 알려주는 것이다. 매개변수와 그래디언트 모두 GPU에 있어야 하기 때문에 LLM 훈련에 매우 많은 GPU 메모리가 필요하다.
그래디언트 저장 문제 외에도 훈련 프로세스 전반에 걸쳐 특정 상태의 모델 복사본인 ‘체크포인트’를 저장하는 것이 일반적이다. 이는 미세조정 프로세스의 여러 단계에서 모델의 전체 크기 복사본을 많이 저장해야 함을 의미한다.
예를 들어 최신 LLM인 ‘팰컨 180B’에는 약 360기가바이트(GB)의 저장 공간이 필요하다. 미세조정 프로세스 전체에 걸쳐 모델의 체크포인트를 10번 저장하려면 3.6테라바이트(TB)의 저장 공간을 소비하게 된다. 더 중요한 것은 이렇게 많은 양의 데이터를 저장하는 데 시간이 걸린다는 점이다. 데이터는 일반적으로 GPU에서 RAM으로, 그다음 스토리지로 이동해야 한다. 잠재적으로 미세조정 프로세스에 상당한 지연이 생길 수 있다.
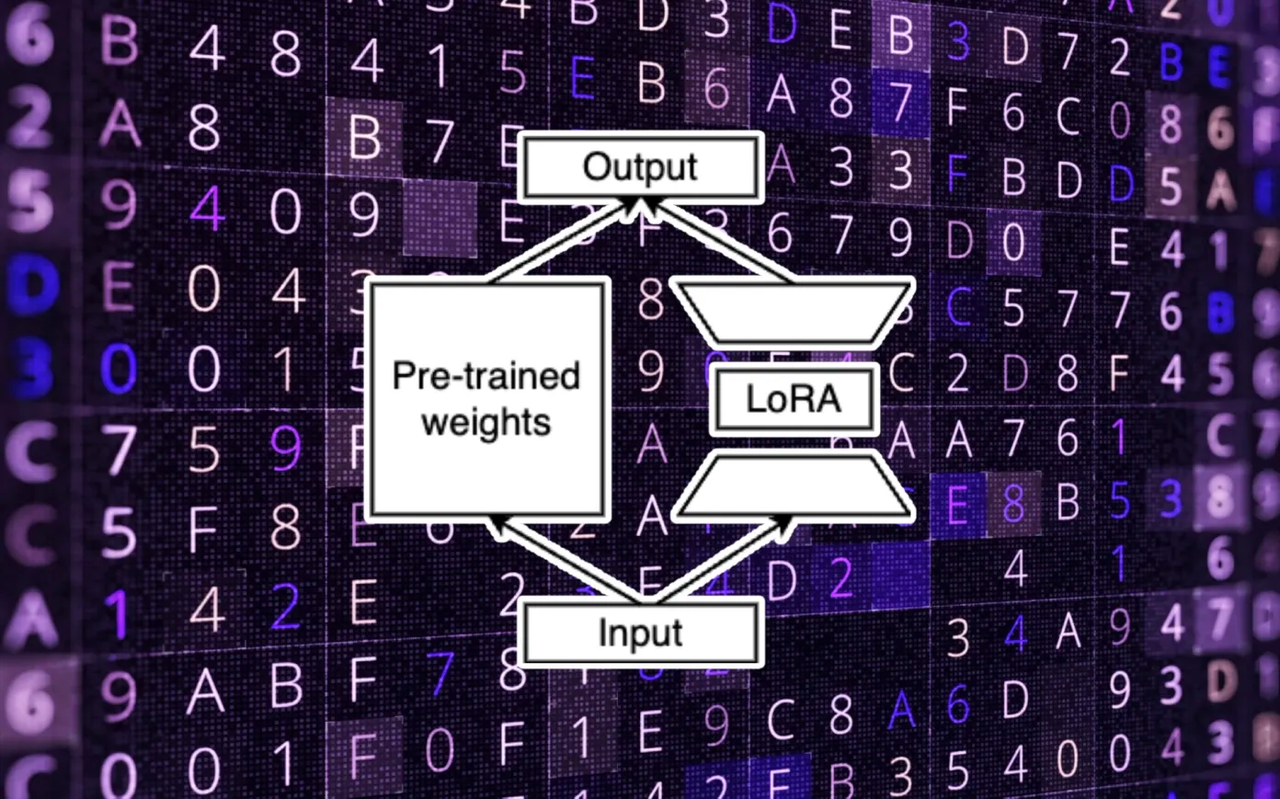
‘매개변수 효율적 미세조정(PEFT)’ 기술은 미세조정 중에 전체 가중치 대신 일부 가중치만을 조정해 이런 비용을 줄이는 방법이다. 특히 마이크로소프트(MS)에서 개발한 PEFT 기술 ‘로라(LoRA)’는 모델 매개변수를 고정한 상태에서 미세조정 작업에서 모델의 성능 향상에 필요한 매개변수의 변경 사항을 학습할 수 있다. 즉 모델 매개변수 전체를 업데이트하는 대신 모델 매개변수의 변경 사항만을 업데이트한다는 설명이다.
로라는 전체 매개변수 미세조정을 통해 달성한 것과 같은 수준의 정확도를 유지하면서 훈련 가능한 매개변수의 수를 몇배로 줄일 수 있다. 이는 필요한 메모리와 계산을 획기적으로 줄여준다.
일반적으로는 미세조정 후 로라 가중치를 기본 LLM과 병합하지만, 로라 가중치를 추론 중에 기본 모델에 연결하는 별도의 ‘모듈식 접근 방식’으로 대체할 수 있다. 이를 통해 미세조정한 모델 변형을 나타내는 여러 ‘로라 어댑터(Adapter)’를 유지하면서도 전반적으로 모델 메모리 공간의 일부만 차지할 수 있다.
이 방법을 통해 막대한 비용을 들이지 않고도 맞춤형 LLM 기반 서비스를 제공할 수 있다. 예를 들어, 블로그 플랫폼은 이 기술을 활용해 최소한의 비용으로 각 작성자의 글쓰기 스타일로 콘텐츠를 만들 수 있는 미세조정 LLM을 제공할 수 있다.
단일 전체 매개변수 LLM 위에 여러 로라 모델을 배포하기 위해서는 메모리 관리가 필요하다. GPU 메모리는 유한하기 때문에 일정 수의 어댑터만 기본 모델과 함께 로드할 수 있다. 여기에는 원활한 작동을 보장하기 위한 효율적인 메모리 관리 시스템이 필요하다.
또 다른 장애물은 여러 요청을 동시에 처리하기 위해 LLM 서버에서 사용하는 일괄 처리 프로세스다. 로라 어댑터의 다양한 크기와 기본 모델과의 별도 계산으로 인해 복잡성이 발생하고 추론 속도를 방해하는 메모리 및 계산 병목 현상이 발생할 수 있다.
다중 GPU 병렬 처리가 필요한 더 큰 LLM으로 인해 복잡성이 배가된다는 것도 문제다. 로라 어댑터의 추가 가중치 및 계산 통합은 병렬 처리 프레임워크를 복잡하게 만들기 때문에 효율성을 유지하기 위한 혁신적인 솔루션이 필요하다.
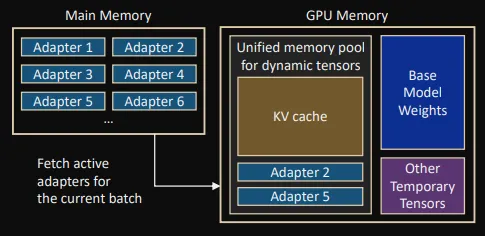
하지만 새로운 S-로라 기술은 모든 로라 어댑터를 메인 메모리에 유지하고 요청을 선택적으로 GPU로 전송함으로써 이런 문제를 해결한다.
S-로라에는 로라 가중치를 메인 메모리에 로드하고 요청을 수신하고 일괄 처리할 때 GPU와 RAM 메모리 간에 자동으로 전송하는 동적 메모리 관리 시스템이 있다.
또 시스템에는 요청 쿼리 모델 캐시와 어댑터 가중치를 원활하게 처리하는 ‘통합 페이징(Unified Paging)’ 메커니즘을 도입했다. 이를 통해 서버는 응답 시간을 지연시킬 수 있는 메모리 조각화(fragmentation) 문제를 일으키지 않고 수백 또는 수천 개의 일괄 요청을 처리할 수 있다.
S-로라에는 로라 어댑터가 여러 GPU에서 실행되는 대형 트랜스포머 모델과 호환되도록 맞춤화된 최첨단 ‘텐서 병렬성(tensor parallelism)’ 시스템이 통합, 단일 GPU 또는 여러 GPU에서 많은 로라 어댑터를 제공할 수 있다.
연구진은 S-로라를 다른 PEFT 시스템과 벤치마크했다. 그 결과 허깅페이스의 PEFT보다 처리량이 최대 30배까지 늘어났다. 로라 서비스를 기본적으로 지원하는 vLLM과 비교하면, S-로라는 처리량을 4배로 늘렸을 뿐만 아니라 병렬로 서비스할 수 있는 어댑터의 수를 몇배나 늘렸다.
가장 주목할 만한 성과 중 하나는 추가 로라 처리를 위한 계산 오버헤드가 거의 증가하지 않으면서도 2000개의 어댑터를 동시에 제공할 수 있는 능력이다.
연구진은 “서비스 제공업체는 기본 모델은 동일하지만 각각 다른 어댑터를 사용하여 사용자에게 서비스를 제공하기를 원할 수 있다. 예를 들어 어댑터는 사용자의 자체 데이터에 맞춰 조정할 수 있다”라고 말했다.
S-로라 코드는 깃허브에서 액세스할 수 있다. 연구진은 기업이 S-로라를 애플리케이션에 쉽게 통합할 수 있도록 이를 인기 있는 LLM 제공 프레임워크에 통합할 계획이다.
박찬 기자 cpark@aitimes.com