
메타가 ‘커넥트 컨퍼런스’에서 발표한 생성 AI 챗봇 ‘메타 AI’와 별개로 ‘라마 2 롱(Long)’이라는 오픈 소스 대형언어모델(LLM)을 조용히 공개했다. 늘어난 컨텍스트 창으로 인해 전반적으로 ‘GPT-3.5 터보’보다 뛰어난 성능을 보인다는 주장이다.
벤처비트는 29일(현지시간) 메타가 ‘파운데이션 모델의 효과적인 장기 컨텍스트 확장(Effective Long-Context Scaling of Foundation Models)’이라는 제목의 논문을 온라인 논문 사이트(arVix)에 게재, 라마 2 롱을 선보였다고 소개했다.
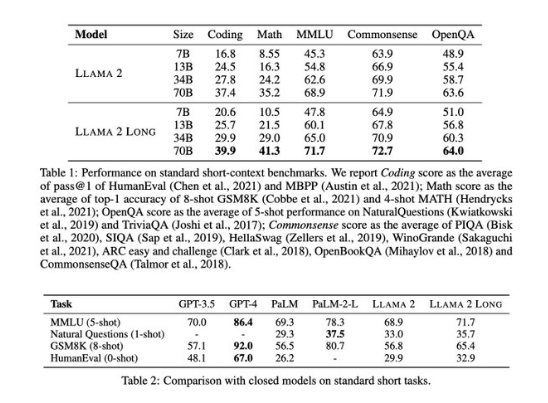
이에 따르면 이 모델을 구축하기 위해 연구진은 더 긴 훈련 시퀀스와 긴 텍스트를 업샘플링하는 데이터셋을 사용해 라마 2를 지속적으로 사전 훈련했다. 그 결과로 구축한 라마 2 롱 70B 모델의 컨텍스트 창은 3만2768 토큰으로 확장, 1만6000개의 토큰을 사용하는 GPT-3.5 터보의 성능을 능가한다고 주장했다.
LLM의 컨텍스트 창은 프롬프트 입력에 사용할 수 있는 토큰의 수를 말한다. 컨텍스트 창이 클수록 프롬프트에서 컨텍스트 내 학습(in-context learning)을 수행하는 기능이 향상, 프롬프트 입력으로 더 많은 예제를 제공해 LLM이 더 나은 답변을 제공할 수 있다.
이 떄문에 컨텍스트 창이 가장 큰 클로드 2가 다른 LLM에 비해 뛰어난 성능을 보이는 것으로 알려졌다. 대부분의 오픈 소스 LLM은 컨텍스트 창이 2000개 토큰 정도에 불과하다.
이번 논문도 오픈 소스인 라마 2의 이런 약점을 개선하기 위해 실시한 연구 내용이다. 메타 연구진은 라마 2 아키텍처를 동일하게 유지하고 토큰 임베딩에 필요한 RoPE(Rotary Positional Embedding) 인코딩 수정을 통해 모델을 개선했다고 설명했다.
또 인간 피드백을 통한 강화 학습(RLHF)과 라마 2 채팅에서 생성한 합성 데이터를 사용해 성능을 더 향상했다고 전했다. RLHF(Reinforcement Learning from Human Feedback)는 챗GPT 훈련에도 사용한 방법으로, 고품질 언어 출력을 가능하도록 해준다.
연구진은 라마 2 롱이 라마 2는 물론 GPT-3.5 터보와 구글의 ‘팜’과 비교해 전반적으로 뛰어난 성능을 보인다는 벤치마크 테스트 결과도 공개했다. GPT-3.5 터보는 매개변수 크기에 비해 성능이 뛰어나, 기업용으로도 인기를 끌던 모델이다.
벤처비트는 이 논문으로 인해 오픈 소스 커뮤니티의 개발자들이 대거 환영하는 분위기라고 전했다. 라마 2 롱은 다음 주 초에 출시할 예정이다.
또 그동안 오픈AI나 구글 등 폐쇄형 모델에 비해 전반적으로 성능이 떨어지던 오픈 소스 모델도 충분한 경쟁력을 가질 수 있다는 것을 보여주는 사례라고 강조했다.
장세민 기자 semim99@aitimes.com
asian type beat