
구글이 ‘컨텍스트 창(context Window)’에 수백만 단어를 입력할 수 있는 새로운 방법을 공개했다. 이런 컨텍스트 창의 확장은 대형언어모델(LLM)을 제공하는 대부분 인공지능(AI) 기업들이 지원하는 것으로, 이제는 LLM 모델의 기본 요소로 자리 잡는 모양새다.
비즈니스인사이더는 16일(현지시간) 구글과 데이터브릭스, UC 버클리 연구진이 수백만 단어를 입력할 수 있도록 컨텍스트 창을 확장하는 ‘링 어텐션(Ring Attention)’ 기법에 관한 논문을 온라인 아카이브(arXiv)에 게재했다고 보도했다.
올 들어 LLM이 경쟁적으로 출시되자, 모델의 성능에 높여주는 것으로 알려진 컨텍스트 창의 크기 확장에도 관심이 모이고 있다. 컨텍스트 창이 클수록 프롬프트에서 컨텍스트 내 학습(in-context learning)을 수행하는 기능이 향상된다. 즉 프롬프트 입력으로 더 크고 많은 예제를 제공하면, LLM이 더 나은 답변을 제공할 수 있다.
예를 들어 책 한권을 통째로 프롬프트 입력하면 내용에 관련된 질문에 바로 답을 찾아낼 수 있다. 또 LLM 학습 과정에 사용할 수 없었던 새로운 정보도 제공할 수도 있다.
기존에는 AI 모델을 훈련하고 실행하는 GPU의 메모리 제한으로 대규모 입력을 처리할 수 없기 때문에 대규모 입력을 처리하도록 컨텍스트 창의 크기를 확장하는 데에는 한계가 있었다.
그중 엔트로픽의 챗봇 ‘클로드’는 최대 10만개(약 7만5000단어) 토큰 규모의 컨텍스트 창을 제공, 이제까지 가장 큰 컨텍스트 창을 제공한다. 이는 기본적으로 책 한 권 정도의 분량이다.
오픈AI의 ‘GPT-3.5’의 컨텍스트 길이는 1만6000개 토큰이며, ‘GPT-4’ 모델은 3만2000개 토큰의 컨텍스트 길이를 지원한다. 데이터브릭스가 인수한 스타트업 모자이크ML의 ‘MPT-7B’ 모델은 6만5000개 토큰을 처리할 수 있다. 대부분의 오픈소스 LLM은 2000개 토큰의 컨텍스트 창을 사용한다.
이번에 발표된 논문은 특정 LLM에 한정하지 않고 챗GPT와 GPT-4, 라마 2 및 구글이 곧 출시할 ‘제미니’와 같은 모델의 기반을 형성한 ‘트랜스포머’ 아키텍처를 근간으로 한다. 따라서 언어모델뿐 아니라 이미지나 비디오를 처리하는 다양한 AI 모델에도 적용할 수 있는 것이 특징이다.
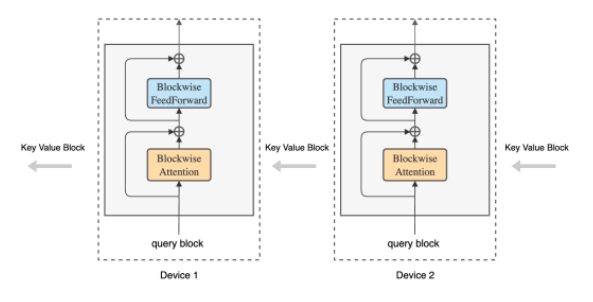
새로운 아이디어의 기본 틀은 최신 AI 모델이 GPU가 다양한 내부 출력을 저장한 후 이를 다음 GPU로 전달하기 전에 다시 계산하는 방식으로 데이터를 처리한다는 것이다. 이를 위해서는 많은 메모리가 필요하며 항상 충분하지는 않다. 이로 인해 AI 모델이 처리할 수 있는 입력의 양이 제한된다. GPU가 아무리 빠르더라도 메모리 병목 현상이 발생하게 된다.
연구진은 “이 연구의 목표는 이러한 병목 현상을 제거하는 것”이라고 강조했다.
새로운 접근 방식은 프로세스의 비트를 다음 GPU로 전달하는 동시에 인접한 다른 GPU로부터 유사한 블록을 수신하는 일종의 ‘GPU 링’을 형성하는 ‘링 어텐션’ 방식이다.
링 어텐션은 매우 큰 컨텍스트를 분할, 링을 구성하는 모든 GPU에서 분산 처리한다. 따라서 전체 링이 하나의 GPU가 전체 컨텍스트를 처리하는 것처럼 동작한다. 이를 통해 각 GPU에 걸린 메모리 제약을 효과적으로 제거할 수 있다.
연구진은 “링 어텐션 기법을 사용하면 AI 모델의 컨텍스트 창에 수만단어가 아닌 수백만 단어를 입력할 수 있게 된다”고 설명했다.

또 256개의 엔비디아 ‘A100’ GPU에서 구동하는 130억개의 매개변수 AI 모델의 경우, 기존 방식으로는 1만6000개의 토큰 컨텍스트 창에서 처리할 수 있는 컨텍스트 길이가 최대 1만6000개의 토큰으로 제한된다고 밝혔다. 하지만 링 어텐션 방식을 사용하면 동일한 조건에서 400만개의 토큰 컨텍스트 창을 처리할 수 있다. 같은 수의 GPU로 250배 많은 작업을 수행할 수 있다는 결론이다.
연구진은 “이론적으로 미래에는 많은 책과 심지어 비디오까지 한번에 컨텍스트 창에 넣을 수 있으며, AI 모델이 이를 분석하고 일관된 응답을 생성할 것”이라며 “AI 모델은 전체 코드베이스를 읽거나 전체 코드베이스를 출력할 수 있고, GPU가 많을수록 컨텍스트 창이 더 길어질 수 있다”고 설명했다.
박찬 기자 cpark@aitimes.com
I appreciate the unique viewpoints you bring to The writing. Very insightful!