
, context really is every thing. The standard of an LLM’s output is tightly linked to the standard and amount of knowledge you provide. In practice, many real-world use cases include massive contexts: code generation over large codebases, querying complex knowledge systems, and even long, meandering chats while researching the right holiday destination (we’ve all been there).
Unfortunately, LLMs can only work efficiently with a limited amount of context. And this isn’t just in regards to the hard limits of the context window, especially now that frontier models support a whole lot of hundreds, and even tens of millions, of tokens. And people limits are continuing to grow. The larger challenge is a phenomenon referred to as context rot, where model performance degrades because the context length increases.
This effect is clearly demonstrated within the paper “RULER: What’s the Real Context Size of Your Long-Context Language Models?” by Hsieh et al. The authors introduce RULER, a brand new benchmark for evaluating long-context performance, and test a variety of models. The outcomes show a consistent pattern: as context length grows, performance drops significantly across all models. In lots of cases, the effective context length (where performance stays comparable to Llama 2–7B) is just around 50% of the advertised context window, and even less.
Of their recent paper “Recursive Language Models”, Zhang et al. propose a promising approach to tackling the context rot problem. In this text, I’d prefer to take a more in-depth take a look at this concept and explore how it really works in practice, leveraging DSPy’s recently added support for this inference strategy.
Recursive Language Models
Recursive Language Models (RLMs) were introduced to handle performance degradation as context length grows, and to enable LLMs to work with very large contexts (as much as two orders of magnitude beyond the model’s native context window). That is becoming increasingly vital as we adopt LLMs for tasks that involve processing a whole lot of tens of millions of tokens.
There are already several approaches for handling long-horizon tasks. Essentially the most common one (something you’ve probably encountered when using code agents like Cursor) is context summarisation. On this setup, the conversation or working context is repeatedly summarised once it approaches the model’s context limit. In practice, nonetheless, this often falls short: vital details and subtle nuances from earlier steps are inclined to wander away because the model “forgets” old information to make room for brand spanking new tokens.
Recursive Language Models take a special, and surprisingly elegant, approach. As an alternative of passing your entire prompt to the LLM every time, the prompt is treated as a set of variables available in a Python REPL (Read–Eval–Print Loop) environment. The model is provided with tools that allow it to examine these variables or recursively invoke itself on programmatically chosen fragments.

In other words, RLMs encourage the LLM to jot down code that constructs its own sub-tasks, after which solve those sub-tasks by recursively calling itself. This shifts the burden from squeezing every thing right into a single prompt to structuring the issue in a way that the model can navigate large contexts more reliably.
The authors evaluated their approach across several long-horizon tasks, where RLMs delivered strong results on each GPT-5 and Qwen-3 models.
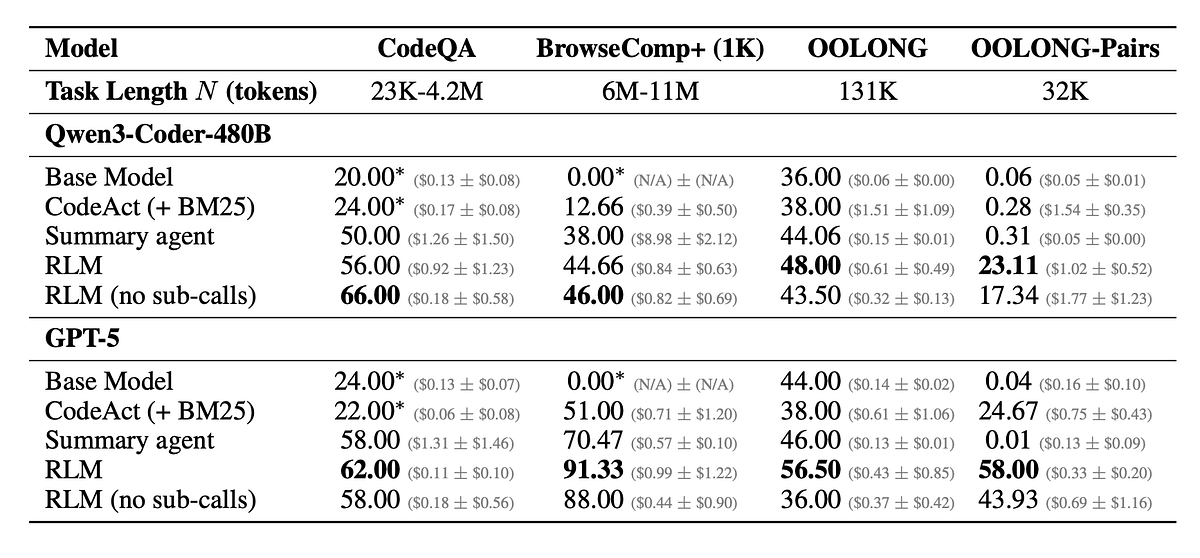
The outcomes look extremely promising. RLMs (with or without subcalls) consistently outperform other approaches across all tasks. Let’s see how this works in practice.
Using RLM in practice
One common scenario where long context really shines is answering questions over a big knowledge base. In order that’s exactly what we’ll try here. I took all of the articles I’ve published on Towards Data Science and loaded them right into a single Markdown file. Somewhat surprisingly, that adds as much as almost 1.5 MB of text. Hopefully, that’s enough for the model to dig through.
Fortunately, DSPy has recently introduced an implementation of the Recursive Language Models inference approach. This implies we don’t need to construct anything ourselves; we just need DSPy version 3.1.2 or newer.
pip install dspy --upgradeLet’s start by loading the dataset.
with open('articles.md', 'r') as f:
articles = f.read()Next, let’s check what number of tokens it comprises.
import anthropic
client = anthropic.Anthropic(api_key=config['ANTHROPIC_API_KEY'])
# Count tokens for messages
token_count = client.messages.count_tokens(
model="claude-sonnet-4-5",
messages=[
{"role": "user", "content": articles}
]
)
print(f"Input tokens: {token_count.input_tokens}")
# Input tokens: 386768There are almost 400K tokens in our context. Claude Sonnet 4.5 supports a 200K context window, so processing your entire dataset in a single prompt isn’t feasible. This is precisely where RLM becomes useful.
To make use of DSPy, we first have to configure the language model. As discussed earlier, RLM relies on code to interact with the prompt, so it really works best with models which have strong coding capabilities. Because of this, I’ll use Claude in this instance, because it’s known to perform well on code-related tasks.
lm = dspy.LM('anthropic/claude-sonnet-4-5', api_key=config['ANTHROPIC_API_KEY'])
dspy.configure(lm=lm)Next, we initialise the RLM by specifying its signature. On this use case, I pass the complete set of articles together with an issue, and expect the model to extract key trends and return them as an inventory of strings.
rlm = dspy.RLM('articles, query -> trends: list[str]')Now we will execute the RLM and access the trends field within the output.
output = rlm(
articles = articles,
query = '''What were the major AI trends of 2025 based on provided
articles? Listen to the content not only the titles.'''
)
print('n'.join(output.trends))
# Agentic AI and Autonomous Systems: Self-reflection patterns, iterative improvement through feedback loops (Self-Refine, Reflexion, CRITIC), and LLMs as reasoning engines that may autonomously plan and execute tasks
# Multi-Agent AI Systems: Evolution from single agents to collaborative teams of specialised agents with distinct roles, using frameworks like LangGraph, CrewAI, and AutoGen for orchestration
# Context Engineering and RAG: Moving beyond static prompting to dynamic retrieval-augmented generation (RAG), adaptive memory systems, and self-improving contexts that learn from experience without retraining
# Standardization Protocols: Emergence of Model Context Protocol (MCP) for standardizing LLM-tool integrations and Agent Communication Protocol (ACP) for inter-agent communication, reducing integration complexity
# Tool-Using LLMs and Function Calling: LLMs equipped with ability to invoke external tools, execute SQL queries, browse web, and interact with APIs through structured function calling mechanisms
# Production-Ready AI Frameworks: Mature ecosystem including LangGraph, DSPy, LangChain, NeMo Agent Toolkit, CrewAI, and AutoGen, focused on moving from prototype to production with built-in observability
# LLM Evaluation and Observability: LLM-as-judge evaluation patterns, comprehensive metrics frameworks (Ragas, DeepEval, Evidently), trajectory evaluation, and continuous monitoring as essential production infrastructure
# Programming Over Prompting: Shift toward declarative, code-based AI development with frameworks like DSPy and configuration-driven approaches (YAML-based) replacing prompt engineering
# Framework Interoperability: Tools designed to integrate across multiple frameworks fairly than create silos, enabling composable AI architectures that leverage best features from different ecosystems
# Local and Cost-Effective LLM Deployment: Running smaller efficient models locally (Llama, Ollama) to scale back API costs and enable experimentation, with deal with cost-quality-latency tradeoffs
# SQL Agents and Data Evaluation Automation: LLM agents specialized in data evaluation tasks, generating and executing SQL queries, with applications in replacing or augmenting traditional data analyst workflows
# Production Quality and Accuracy Enhancement: Techniques for improving LLM accuracy including chain-of-thought reasoning, structured outputs through function calling, and iterative refinement for business-critical applicationsThe execution took around three minutes, and the result was a surprisingly plausible summary of the major themes across my articles. Nonetheless, we’re not here to learn in regards to the trends themselves. The more interesting query is how RLM managed to do that in the primary place. So let’s dig deeper.
RLM under the hood
Naturally, probably the most fascinating part is knowing what’s actually happening under the hood.
RLM implementation
As discussed earlier, the important thing idea behind Recursive Language Models is that long contexts are treated as a part of an external environment, fairly than being fed directly into the model as a single prompt. As an alternative, the LLM writes Python code to programmatically inspect, decompose, and recursively invoke sub-LLMs over smaller snippets of the information.
At a high level, the implementation has a couple of core characteristics:
- It uses a sandboxed Python REPL (Read–Eval–Print Loop) that permits the LLM to explore large contexts through code execution.
- The LLM operates in a well-recognized agentic loop: it writes Python code, observes the output, after which decides what to do next.
- It might probably perform recursive sub-calls (effectively calling itself) using tools like
llm_query()andllm_query_batched()to analyse smaller chunks semantically. - Once the model is satisfied with the result, it finalises the method by calling
SUBMIT()with the output.
Prompts
To essentially understand how this works, I find it helpful to examine the actual messages sent to and from the LLM. DSPy makes this easy with the next command.
# Inspect the raw LLM calls - shows the actual prompts sent to the model
dspy.inspect_history(n=39)This provides us full visibility into what was shared with the model at each step.
Let’s start with the system message. It defines the input variables available to the model (as laid out in the RLM signature) and lists the functions the model can call, reminiscent of print, recursive LLM calls, and standard library utilities.
Your input fields are:
1. `variables_info` (str): Metadata in regards to the variables available within the REPL
2. `repl_history` (REPLHistory): Previous REPL code executions and their outputs
3. `iteration` (str): Current iteration number (1-indexed) out of max_iterations
Your output fields are:
1. `reasoning` (str): Think step-by-step: what do you understand? What stays? Plan your next motion.
2. `code` (str): Python code to execute.
All interactions shall be structured in the next way, with the suitable values filled in.
[[ ## variables_info ## ]]
{variables_info}
[[ ## repl_history ## ]]
{repl_history}
[[ ## iteration ## ]]
{iteration}
[[ ## reasoning ## ]]
{reasoning}
[[ ## code ## ]]
{code}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Given the fields `articles`, `query`, produce the fields `trends`.
You might be tasked with producing the next outputs given the inputs `articles`, `query`:
- {trends} # note: the worth you produce must adhere to the JSON schema: {"type": "array", "items": {"type": "string"}}
You've gotten access to a Python REPL environment. Write Python code and it'll be executed. You will notice the output, then write more code based on what you learned. That is an iterative process.
Available:
- Variables: `articles`, `query` (your input data)
- `llm_query(prompt)` - query a sub-LLM (~500K char capability) for semantic evaluation
- `llm_query_batched(prompts)` - query multiple prompts concurrently (much faster for multiple queries)
- `print()` - ALWAYS print to see results
- `SUBMIT(trends)` - submit final output when done
- Standard libraries: re, json, collections, math, etc.
IMPORTANT: That is ITERATIVE. Each code block you write will execute, you will see the output, then you definitely resolve what to do next. Do NOT try to unravel every thing in a single step.
1. EXPLORE FIRST - Have a look at your data before processing it. Print samples, check types/lengths, understand the structure.
2. ITERATE - Write small code snippets, observe outputs, then resolve next steps. State persists between iterations.
3. VERIFY BEFORE SUBMITTING - If results seem fallacious (zeros, empty, unexpected), reconsider your approach.
4. USE llm_query FOR SEMANTICS - String matching finds WHERE things are; llm_query understands WHAT things mean.
5. MINIMIZE RETYPING (INPUTS & OUTPUTS) - When values are long, precise, or error-prone (IDs, numbers, code, quotes), re-access them via variables and parse/compute in code as a substitute of retyping. Use small, targeted prints to sanity-check, but avoid manual copying when variables can carry the precise value.
6. SUBMIT ONLY AFTER SEEING OUTPUTS - SUBMIT ends the present run immediately. If you'll want to inspect printed output, run it in a single step, review the result, then call SUBMIT in a later step.
You've gotten max 50 sub-LLM calls. When done, call SUBMIT() together with your output.Let’s also take a take a look at the primary user message sent to the LLM. This provides the model an summary of the input variables: their types, lengths (so the model knows how much it will possibly read without delay), and a preview of the content to grasp the structure.
[[ ## variables_info ## ]]
[1] «««
Variable: `articles` (access it in your code)
Type: str
Total length: 1,392,921 characters
Preview:
```
---
title: "Agentic AI from First Principles: Reflection"
date: "2025-10-24T12:00:00-05:00"
category: "Agentic AI"
read_time: "21 min read"
url: "https://towardsdatascience.com/agentic-ai-from-first-principles-reflection/"
---
Arthur C. Clarke's Third Law says that "*any sufficiently advanced technology is indistinguishable from magic*". That is exactly how lots of today's AI frameworks feel. Tools like GitHub Copilot, Claude Desktop, OpenAI Operator, and Perplexity Comet are automating everyda...
```
»»»
[2] «««
Variable: `query` (access it in your code)
Type: str
Total length: 114 characters
Preview:
```
What were the major AI trends of 2025 based on provided articles? Listen to the content not only the titles.
```
»»»
[3] «««
Variable: `verbose` (access it in your code)
Type: bool
Total length: 4 characters
Preview:
```
True
```
»»»
[[ ## repl_history ## ]]
You've gotten not interacted with the REPL environment yet.
[[ ## iteration ## ]]
1/20
Respond with the corresponding output fields, starting with the sphere `[[ ## reasoning ## ]]`, then `[[ ## code ## ]]`, after which ending with the marker for `[[ ## completed ## ]]`.Here’s the model’s initial response according to the format laid out in the user message.
[[ ## reasoning ## ]]
I want to investigate articles to discover major AI trends of 2025. Let me start by exploring the information:
1. First, I'll examine the structure and content of the `articles` variable to grasp what I'm working with
2. I'll need to have a look at multiple articles, not only titles, to grasp the actual content
3. Then I'll use semantic evaluation (llm_query) to extract and discover trends
4. Finally, I'll compile the trends into an inventory
Let me start by exploring the articles data to see its structure and get a way of what is available.
[[ ## code ## ]]
# First, let's understand the structure of the articles
print("Kind of articles:", type(articles))
print("nLength of articles:", len(articles))
print("n" + "="*80)
print("First 2000 characters:")
print(articles[:2000])
print("n" + "="*80)
# Let's have a look at if we will discover the structure - looks like articles are separated
# Let's try to separate and count them
article_separator = "---ntitle:"
article_parts = articles.split(article_separator)
print(f"nNumber of article parts found: {len(article_parts)}")
print(f"First part length: {len(article_parts[0])} (likely empty or header)")
print(f"Second part length: {len(article_parts[1]) if len(article_parts) > 1 else 0}")
[[ ## completed ## ]]The raw logs gave us a solid understanding of how the LLM interacts with the environment under the hood. Next, let’s examine the trajectory the LLM followed to succeed in its final output.
Trajectory
For a structured view of the trajectory, we will inspect output.trajectory. This provides access to every step of the model’s reasoning, the code it generates, and the resulting outputs. Essentially, it provides a comprehensive view of all REPL interactions.
# Examine the complete trajectory - this shows all REPL interactions
for i, step in enumerate(output.trajectory):
print(f"n{'='*60}")
print(f"STEP {i+1}")
print(f"{'='*60}")
print(f"n📝 REASONING:n{step['reasoning']}")
print(f"n💻 CODE:n{step['code']}")
print(f"n📤 OUTPUT:n{step['output'][:1000]}{'...' if len(step['output']) > 1000 else ''}")Reviewing the trajectory helps us understand the major patterns the LLM uses to unravel the issue. On this case, it took 13 steps to succeed in the ultimate answer.
Step one, as expected, was exploring the articles variable: examining its structure and getting a way of the available data. This initial exploration sets the stage for all subsequent reasoning and sub-calls.
# First, let's understand the structure of the articles
print("Kind of articles:", type(articles))
print("nLength of articles:", len(articles))
print("n" + "="*80)
print("First 2000 characters:")
print(articles[:2000])
print("n" + "="*80)
# Let's have a look at if we will discover the structure - looks like articles are separated
# Let's try to separate and count them
article_separator = "---ntitle:"
article_parts = articles.split(article_separator)
print(f"nNumber of article parts found: {len(article_parts)}")
print(f"First part length: {len(article_parts[0])} (likely empty or header)")
print(f"Second part length: {len(article_parts[1]) if len(article_parts) > 1 else 0}")Next, the LLM realised that there have been 40 articles in total, each separated by ---ntitle:, and that each article contained metadata fields like title, date, category, read_time, and url, followed by the major content. Just identifying this structure from a 1.5 MB text file is already a major achievement.
Constructing on this understanding, the LLM then parsed the articles and generated a summary of the article titles and major themes.
# Parse articles into structured format
import re
# Split by the article separator
raw_articles = articles.split("---ntitle:")
# Process each article (skip the primary empty element)
parsed_articles = []
for i, raw_article in enumerate(raw_articles[1:], 1): # Skip first empty element
# Add back the "title:" that was removed by split
raw_article = "title:" + raw_article
# Extract metadata using
title_match = re.search(r'title:s*"([^"]*)"', raw_article)
date_match = re.search(r'date:s*"([^"]*)"', raw_article)
category_match = re.search(r'category:s*"([^"]*)"', raw_article)
# Find where content starts (after the second "---")
content_start = raw_article.find("---", 10) # Skip the primary part
content = raw_article[content_start+3:].strip() if content_start != -1 else ""
parsed_articles.append({
'index': i,
'title': title_match.group(1) if title_match else "Unknown",
'date': date_match.group(1) if date_match else "Unknown",
'category': category_match.group(1) if category_match else "Unknown",
'content': content,
'content_length': len(content)
})
print(f"Successfully parsed {len(parsed_articles)} articlesn")
print("="*80)
print("Sample of articles (titles and categories):")
print("="*80)
for i, article in enumerate(parsed_articles[:10], 1):
print(f"{i}. [{article['category']}] {article['title']}")
print(f" Content length: {article['content_length']} chars")
print()After parsing the articles, the LLM decided to focus exclusively on AI-related content, for the reason that query specifically asked about AI trends.
# Let's deal with AI-related articles (AI, Agentic AI, LLM Applications, ChatGPT categories)
# and sample strategically to grasp content-based trends
ai_related = [a for a in parsed_articles if a['category'] in [
'Artificial Intelligence', 'Agentic AI', 'LLM Applications', 'ChatGPT', 'Deep Learning'
]]Next, the LLM identified the important thing articles it desired to deal with. It was a subjective selection based on relevance and content. To analyse these intimately, it used recursive sub-calls, processing each article programmatically.
To administer the workload efficiently, the LLM split the articles into two batches and processed them sequentially. For every article, it also truncated the content to the primary 15K characters. This strategy allowed the model to handle a big volume of text without exceeding its context window, while still capturing crucial insights from each article.
# Create prompts to extract AI trends from article content
# I'll include a considerable portion of every article's content for evaluation
prompts_batch1 = []
for i, article in enumerate(selected_for_analysis[:8]): # First batch of 8
# Take first ~15K chars of content to remain inside LLM limits while getting substance
content_sample = article['content'][:15000]
prompt = f"""Analyze this text about AI from 2025 and discover the major AI trends, technologies, methodologies, or concepts it discusses.
Article Title: {article['title']}
Article Content (excerpt):
{content_sample}
Based on the content above, list the important thing AI trends, technologies, or concepts discussed in this text. Concentrate on:
- Recent frameworks, tools, or methodologies mentioned
- Emerging patterns in AI development (e.g., agentic AI, multi-agent systems)
- Necessary techniques or approaches
- Production/deployment considerations
Provide a concise list of 3-5 major trends/concepts from this text."""
prompts_batch1.append(prompt)
print(f"Created {len(prompts_batch1)} prompts for first batch")
print("nProcessing first batch of articles...")
# Query the primary batch
results_batch1 = llm_query_batched(prompts_batch1)
print(f"nReceived {len(results_batch1)} results")
print("nResults from first batch:")
print("="*80)
for i, (article, result) in enumerate(zip(selected_for_analysis[:8], results_batch1), 1):
print(f"n{i}. {article['title']}")
print("-"*80)
print(result)
print()Finally, the LLM reviewed the complete list of articles over again, identified additional relevant topics, and processed them using recursive sub-calls in the identical way. Once all the data had been retrieved, it synthesised the outcomes into the trends_2025 variable (an inventory of strings representing the major AI trends) and submitted it as the ultimate answer.
##### STEP 12 #####
# Now let me synthesize all findings into comprehensive AI trends
# I'll review all the outcomes and create a structured summary
print("SYNTHESIZING ALL FINDINGS FROM 20 ANALYZED ARTICLES")
print("="*80)
print("nBased on deep content evaluation of 20 AI-focused articles from 2025,")
print("listed below are the major AI trends identified:n")
# Compile the great list of trends
trends_2025 = [
"Agentic AI and Autonomous Systems: Self-reflection patterns, iterative improvement through feedback loops (Self-Refine, Reflexion, CRITIC), and LLMs as reasoning engines that can autonomously plan and execute tasks",
"Multi-Agent AI Systems: Evolution from single agents to collaborative teams of specialized agents with distinct roles, using frameworks like LangGraph, CrewAI, and AutoGen for orchestration",
"Context Engineering and RAG: Moving beyond static prompting to dynamic retrieval-augmented generation (RAG), adaptive memory systems, and self-improving contexts that learn from experience without retraining",
"Standardization Protocols: Emergence of Model Context Protocol (MCP) for standardizing LLM-tool integrations and Agent Communication Protocol (ACP) for inter-agent communication, reducing integration complexity",
"Tool-Using LLMs and Function Calling: LLMs equipped with ability to invoke external tools, execute SQL queries, browse web, and interact with APIs through structured function calling mechanisms",
"Production-Ready AI Frameworks: Mature ecosystem including LangGraph, DSPy, LangChain, NeMo Agent Toolkit, CrewAI, and AutoGen, focused on moving from prototype to production with built-in observability",
"LLM Evaluation and Observability: LLM-as-judge evaluation patterns, comprehensive metrics frameworks (Ragas, DeepEval, Evidently), trajectory evaluation, and continuous monitoring as essential production infrastructure",
"Programming Over Prompting: Shift toward declarative, code-based AI development with frameworks like DSPy and configuration-driven approaches (YAML-based) replacing prompt engineering",
"Framework Interoperability: Tools designed to integrate across multiple frameworks rather than create silos, enabling composable AI architectures that leverage best features from different ecosystems",
"Local and Cost-Effective LLM Deployment: Running smaller efficient models locally (Llama, Ollama) to reduce API costs and enable experimentation, with focus on cost-quality-latency tradeoffs",
"SQL Agents and Data Analysis Automation: LLM agents specialized in data analysis tasks, generating and executing SQL queries, with applications in replacing or augmenting traditional data analyst workflows",
"Production Quality and Accuracy Enhancement: Techniques for improving LLM accuracy including chain-of-thought reasoning, structured outputs through function calling, and iterative refinement for business-critical applications"
]
print("MAIN AI TRENDS OF 2025:")
print("="*80)
for i, trend in enumerate(trends_2025, 1):
print(f"n{i}. {trend}")
print("n" + "="*80)
print(f"nTotal trends identified: {len(trends_2025)}")
print("nThese trends are based on content evaluation of articles covering:")
print("- Agentic AI systems and design patterns")
print("- Multi-agent architectures and frameworks")
print("- Production deployment and evaluation")
print("- Emerging protocols and standardization")
print("- Tool use and external system integration")
print("- Cost-effective and accurate LLM applications")
##### STEP 13 #####
# Submit the ultimate list of AI trends from 2025
SUBMIT(trends_2025)We will see that the model was quite creative: it understood the structure of our content, parsed the articles, and used recursive calls to process each individually. Nonetheless, there was one significant gap on this evaluation. It completely missed filtering by 12 months, despite the fact that the metadata for every article clearly contained the publication date.
To handle this, I repeated the request, this time emphasising the importance of filtering for 2025, to make sure the model focused only on articles from that 12 months.
output2 = rlm(
articles = articles,
query = '''What were the major AI trends of 2025 based on provided
articles? Listen to the content not only the titles.
Remember to filter by 12 months, this information is present in
metadata for every article.'''
)This time, the model considered the 12 months and performed more sophisticated parsing, using regular expressions to extract the publication date for every article.
import re
from datetime import datetime
# Split articles by the separator "---" in the beginning of metadata blocks
# The pattern is: --- followed by metadata, followed by --- followed by content
article_blocks = re.split(r'n---n', articles)
print(f"Total article blocks found: {len(article_blocks)}")
print("n" + "="*80)
# Let's examine the structure - articles seem to start out with "---ntitle:"
# Let me try a special approach - find all articles by their metadata pattern
article_pattern = r'---ntitle: "(.*?)"ndate: "(.*?)"ncategory: "(.*?)"nread_time: "(.*?)"nurl: "(.*?)"n---n(.*?)(?=n---ntitle:|$)'
matches = re.findall(article_pattern, articles, re.DOTALL)
print(f"Articles found with : {len(matches)}")
if len(matches) > 0:
print("nFirst article metadata:")
print(f" Title: {matches[0][0]}")
print(f" Date: {matches[0][1]}")
print(f" Category: {matches[0][2]}")
print(f" Content preview (first 200 chars): {matches[0][5][:200]}")Next, it filtered the articles by 12 months and identified 13 articles from 2025.
# Parse articles and filter for 2025
articles_2025 = []
for match in matches:
title, date_str, category, read_time, url, content = match
# Extract 12 months from date string (format: "2025-10-24T12:00:00-05:00")
12 months = date_str.split('-')[0]
if 12 months == "2025":
articles_2025.append({
'title': title,
'date': date_str,
'category': category,
'content': content.strip()
})
print(f"Total articles: {len(matches)}")
print(f"Articles from 2025: {len(articles_2025)}")
print("n" + "="*80)
print("2025 Articles:")
print("="*80)
for i, article in enumerate(articles_2025, 1):
print(f"n{i}. {article['title']}")
print(f" Date: {article['date']}")
print(f" Category: {article['category']}")
print(f" Content length: {len(article['content'])} chars")Then, it analysed these 13 articles using recursive sub-calls and produced an updated list of trends. This time, the duty was accomplished accurately. As with many other examples, it highlights the importance of asking clear, explicit questions and specifying the factors and actions we wish the model to follow.
Agentic AI and Multi-Agent Systems: Constructing autonomous AI agents able to multi-step reasoning, tool use, planning, and reflection, often with multiple specialized agents collaborating on complex tasks
Code Agents: AI agents that execute tool calls using actual code (Python) as a substitute of JSON-based tool calling, enabling dynamic function creation and achieving higher success rates with fewer steps
Model Context Protocol (MCP): Anthropic's standardization protocol for connecting AI applications to external tools and data sources, reducing integration complexity from M*N to M+N and enabling reusable, framework-agnostic components
Agent Communication Protocol (ACP): Emerging open protocol under the Linux Foundation for standardizing communication between AI agents via RESTful APIs, enabling interoperability across different frameworks
Reflection and Self-Refinement Patterns: LLMs reviewing and improving their very own outputs through iterative feedback loops, including self-feedback, verbal reinforcement learning, and tool-interactive critiquing, achieving 10-30% accuracy improvements
Framework Ecosystem Proliferation: Multiple competing frameworks including LangGraph, smolagents, CrewAI, DSPy, and NeMo Agent Toolkit, with growing emphasis on interoperability and declarative configuration approaches
Production-Ready LLM Infrastructure: Moving beyond prototypes to handle 'day 2' problems like API exposure, observability, monitoring, evaluation frameworks, and deployment at scale
Parameter-Efficient Nice-Tuning (PEFT) and LoRA: Techniques for customizing LLMs by updating only small subsets of parameters, enabling task-specific optimization while reducing computational costs and enabling on-premises deployment
Advanced Nice-Tuning with Memory Experts: Lamini's Mixture of Memory Experts (MoME) using ~1 million LoRA adapters for near-perfect factual accuracy (95%) with zero loss on specific information
Shift from Prompting to Programming Paradigm: Frameworks like DSPy treating LLM tasks as modular programming fairly than manual prompt crafting, with structured signatures and reusable components
LLM Evaluation and Quality Assurance: Comprehensive evaluation frameworks (Evidently, DeepEval, MLFlow, LangSmith) for testing, monitoring, and ensuring reliability in production, especially for regulated industries
RAG (Retrieval-Augmented Generation): Providing relevant context and knowledge bases to reinforce LLM precision and enable specialized capabilities in agents
Tool Use and Orchestration: AI systems dynamically choosing and executing tools from multiple sources, with standardized tool definitions and safety controls
YAML-Based Declarative Configuration: Defining LLM workflows, models, and agent behavior through configuration files fairly than purely code-based implementations
Interpretable AI and Rule-Based Systems: Using decision trees, extracted rules, and transparent models as alternatives to black-box approaches for compliance, explainability, and rapid deployment in regulated industriesSummary
It’s time to wrap things up and reflect on what we’ve learned. In this text, we explored RLM (Recursive Language Models) — a brand new inference strategy that permits LLMs to handle contexts as much as two orders of magnitude larger than their standard context window, while mitigating the context rot problem.
I’m genuinely fascinated by this approach. The paper proposes an easy yet elegant approach to treating prompts as variables in a Python environment, which jogs my memory of my favourite agentic framework, smolagents by HuggingFace. I imagine this method is very efficient because LLMs have been trained on a lot code that programming looks like a native language to them. Using code because the interface for reasoning and recursion is each practical and powerful.
Overall, Recursive Language Models offer a practical and chic solution to push the bounds of context length, making LLMs more able to handling complex, large-scale tasks. Nonetheless, clear instructions and thoughtful guidance are still key to getting one of the best results.
Reference
This text relies on the paper by Zhang et al., “Recursive Language Models”, published on December 31, 2025.