
The sector of artificial intelligence is evolving at a panoramic pace, with large language models (LLMs) leading the charge in natural language processing and understanding. As we navigate this, a brand new generation of LLMs has emerged, each pushing the boundaries of what is possible in AI.
On this overview of the very best LLMs, we’ll explore the important thing features, benchmark performances, and potential applications of those cutting-edge language models, offering insights into how they’re shaping the long run of AI technology.
Anthropic’s Claude 3 models, released in March 2024, represented a big step forward in artificial intelligence capabilities. This family of LLMs offers enhanced performance across a big selection of tasks, from natural language processing to complex problem-solving.
Claude 3 is available in three distinct versions, each tailored for specific use cases:
- Claude 3 Opus: The flagship model, offering the very best level of intelligence and capability.
- Claude 3.5 Sonnet: A balanced option, providing a combination of speed and advanced functionality.
- Claude 3 Haiku: The fastest and most compact model, optimized for quick responses and efficiency.
Key Capabilites of Claude 3:
- Enhanced Contextual Understanding: Claude 3 demonstrates improved ability to understand nuanced contexts, reducing unnecessary refusals and higher distinguishing between potentially harmful and benign requests.
- Multilingual Proficiency: The models show significant improvements in non-English languages, including Spanish, Japanese, and French, enhancing their global applicability.
- Visual Interpretation: Claude 3 can analyze and interpret various forms of visual data, including charts, diagrams, photos, and technical drawings.
- Advanced Code Generation and Evaluation: The models excel at coding tasks, making them priceless tools for software development and data science.
- Large Context Window: Claude 3 includes a 200,000 token context window, with potential for inputs over 1 million tokens for select high-demand applications.
Benchmark Performance:
Claude 3 Opus has demonstrated impressive results across various industry-standard benchmarks:
- MMLU (Massive Multitask Language Understanding): 86.7%
- GSM8K (Grade School Math 8K): 94.9%
- HumanEval (coding benchmark): 90.6%
- GPQA (Graduate-level Skilled Quality Assurance): 66.1%
- MATH (advanced mathematical reasoning): 53.9%
These scores often surpass those of other leading models, including GPT-4 and Google’s Gemini Ultra, positioning Claude 3 as a top contender within the AI landscape.
Claude 3 Benchmarks (Anthropic)
Claude 3 Ethical Considerations and Safety
Anthropic has placed a powerful emphasis on AI safety and ethics in the event of Claude 3:
- Reduced Bias: The models show improved performance on bias-related benchmarks.
- Transparency: Efforts have been made to reinforce the general transparency of the AI system.
- Continuous Monitoring: Anthropic maintains ongoing safety monitoring, with Claude 3 achieving an AI Safety Level 2 rating.
- Responsible Development: The corporate stays committed to advancing safety and neutrality in AI development.
Claude 3 represents a big advancement in LLM technology, offering improved performance across various tasks, enhanced multilingual capabilities, and complicated visual interpretation. Its strong benchmark results and versatile applications make it a compelling alternative for an LLM.
OpenAI’s GPT-4o (“o” for “omni”) offers improved performance across various tasks and modalities, representing a brand new frontier in human-computer interaction.
Key Capabilities:
- Multimodal Processing: GPT-4o can accept inputs and generate outputs in multiple formats, including text, audio, images, and video, allowing for more natural and versatile interactions.
- Enhanced Language Understanding: The model matches GPT-4 Turbo’s performance on English text and code tasks while offering superior performance in non-English languages.
- Real-time Interaction: GPT-4o can reply to audio inputs in as little as 232 milliseconds, with a mean of 320 milliseconds, comparable to human conversation response times.
- Improved Vision Processing: The model demonstrates enhanced capabilities in understanding and analyzing visual inputs in comparison with previous versions.
- Large Context Window: GPT-4o includes a 128,000 token context window, allowing for processing of longer inputs and more complex tasks.
Performance and Efficiency:
- Speed: GPT-4o is twice as fast as GPT-4 Turbo.
- Cost-efficiency: It’s 50% cheaper in API usage in comparison with GPT-4 Turbo.
- Rate limits: GPT-4o has five times higher rate limits in comparison with GPT-4 Turbo.
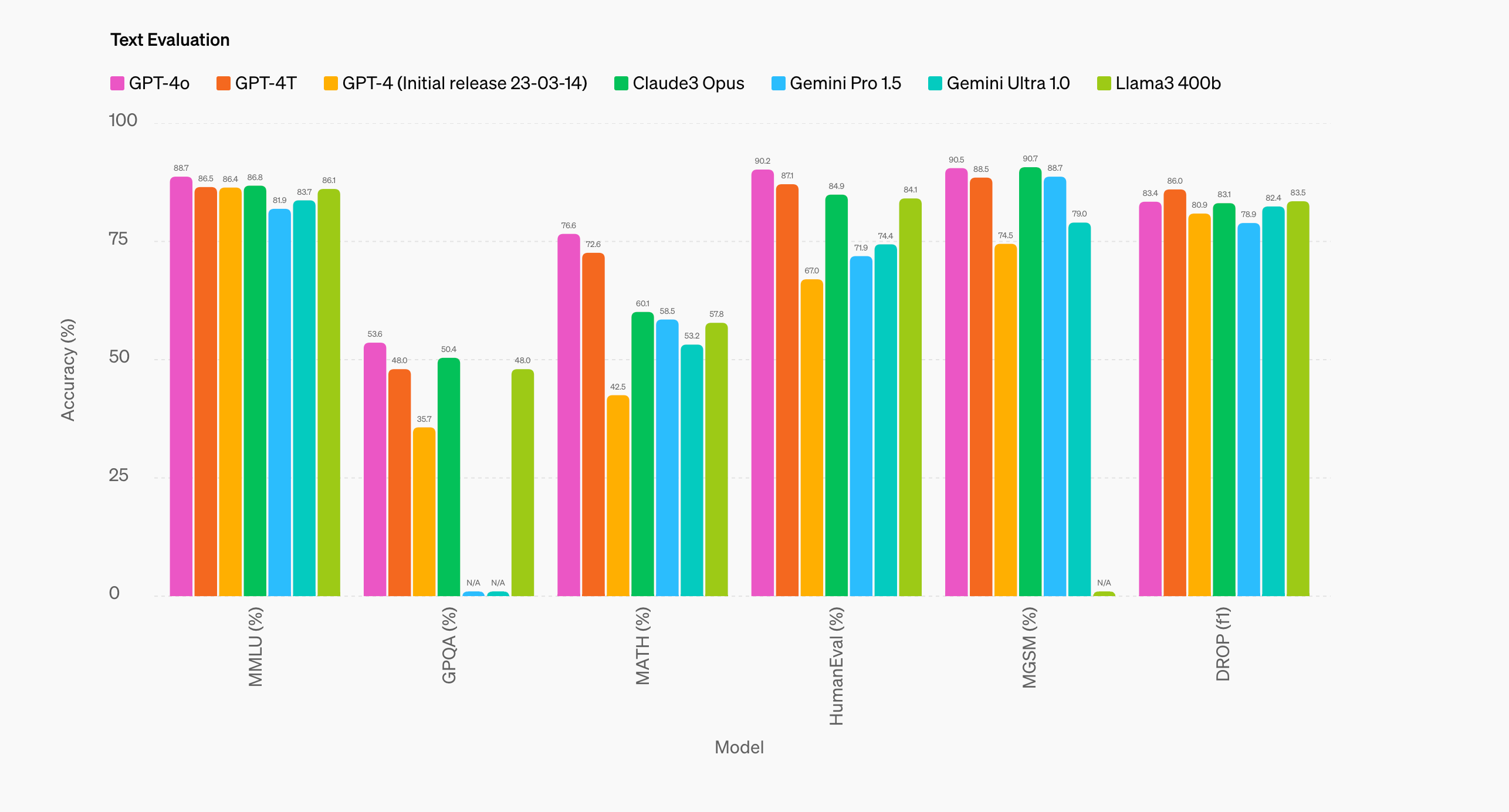
GPT-4o benchmarks (OpenAI)
GPT-4o’s versatile capabilities make it suitable for a big selection of applications, including:
- Natural language processing and generation
- Multilingual communication and translation
- Image and video evaluation
- Voice-based interactions and assistants
- Code generation and evaluation
- Multimodal content creation
Availability:
- ChatGPT: Available to each free and paid users, with higher usage limits for Plus subscribers.
- API Access: Available through OpenAI’s API for developers.
- Azure Integration: Microsoft offers GPT-4o through Azure OpenAI Service.
GPT-4o Safety and Ethical Considerations
OpenAI has implemented various safety measures for GPT-4o:
- Built-in safety features across modalities
- Filtering of coaching data and refinement of model behavior
- Recent safety systems for voice outputs
- Evaluation in response to OpenAI’s Preparedness Framework
- Compliance with voluntary commitments to responsible AI development
GPT-4o offers enhanced capabilities across various modalities while maintaining a deal with safety and responsible deployment. Its improved performance, efficiency, and flexibility make it a strong tool for a big selection of applications, from natural language processing to complex multimodal tasks.
Llama 3.1 is the newest family of enormous language models by Meta and offers improved performance across various tasks and modalities, difficult the dominance of closed-source alternatives.
Llama 3.1 is obtainable in three sizes, catering to different performance needs and computational resources:
- Llama 3.1 405B: Essentially the most powerful model with 405 billion parameters
- Llama 3.1 70B: A balanced model offering strong performance
- Llama 3.1 8B: The smallest and fastest model within the family
Key Capabilities:
- Enhanced Language Understanding: Llama 3.1 demonstrates improved performance usually knowledge, reasoning, and multilingual tasks.
- Prolonged Context Window: All variants feature a 128,000 token context window, allowing for processing of longer inputs and more complex tasks.
- Multimodal Processing: The models can handle inputs and generate outputs in multiple formats, including text, audio, images, and video.
- Advanced Tool Use: Llama 3.1 excels at tasks involving tool use, including API interactions and performance calling.
- Improved Coding Abilities: The models show enhanced performance in coding tasks, making them priceless for developers and data scientists.
- Multilingual Support: Llama 3.1 offers improved capabilities across eight languages, enhancing its utility for global applications.
Llama 3.1 Benchmark Performance
Llama 3.1 405B has shown impressive results across various benchmarks:
- MMLU (Massive Multitask Language Understanding): 88.6%
- HumanEval (coding benchmark): 89.0%
- GSM8K (Grade School Math 8K): 96.8%
- MATH (advanced mathematical reasoning): 73.8%
- ARC Challenge: 96.9%
- GPQA (Graduate-level Skilled Quality Assurance): 51.1%
These scores reveal Llama 3.1 405B’s competitive performance against top closed-source models in various domains.
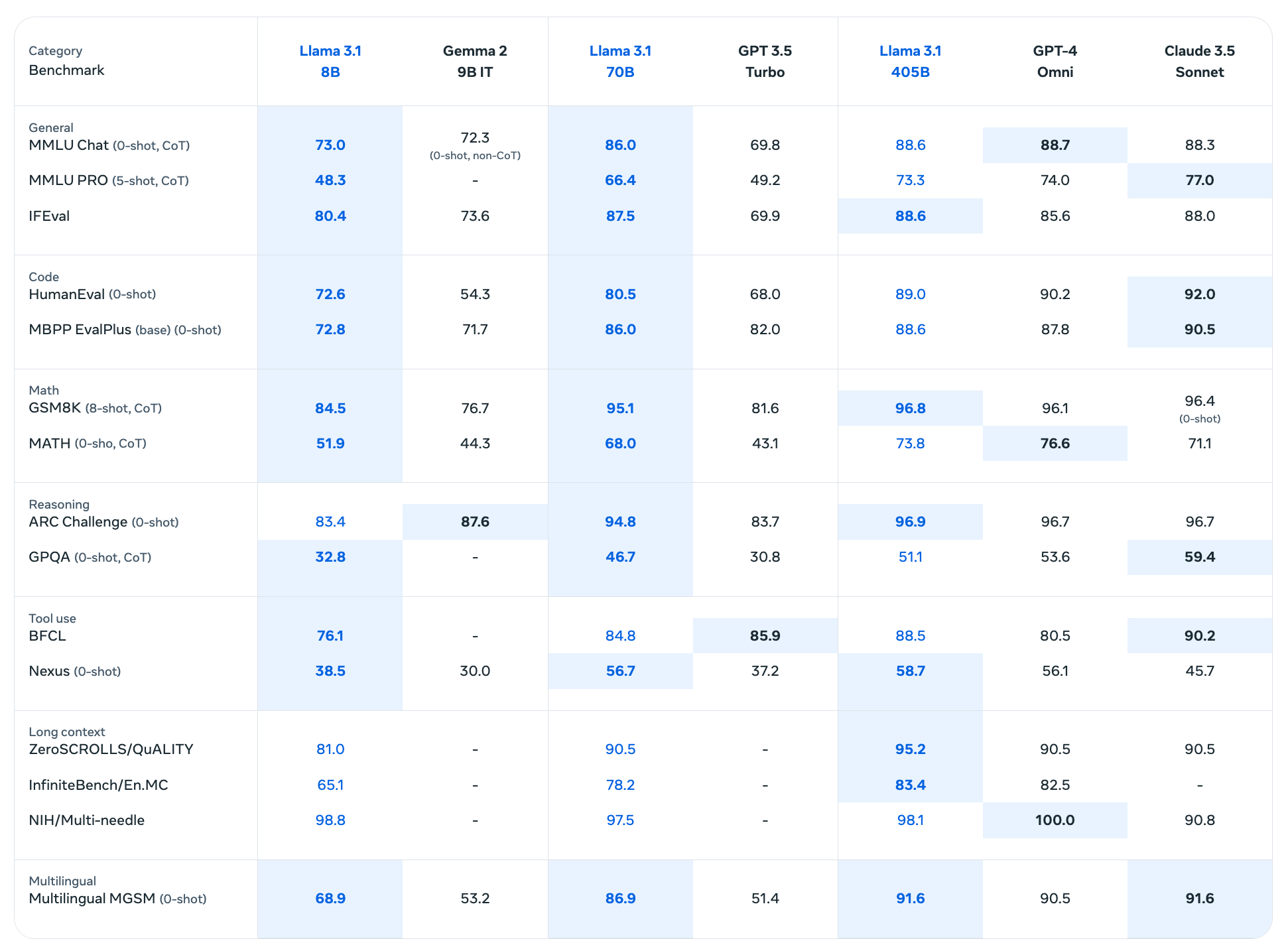
Llama 3.1 benchmarks (Meta)
Availability and Deployment:
- Open Source: Llama 3.1 models can be found for download on Meta’s platform and Hugging Face.
- API Access: Available through various cloud platforms and partner ecosystems.
- On-Premises Deployment: Could be run locally or on-premises without sharing data with Meta.
Llama 3.1 Ethical Considerations and Safety Features
Meta has implemented various safety measures for Llama 3.1:
- Llama Guard 3: A high-performance input and output moderation model.
- Prompt Guard: A tool for safeguarding LLM-powered applications from malicious prompts.
- Code Shield: Provides inference-time filtering of insecure code produced by LLMs.
- Responsible Use Guide: Offers guidelines for ethical deployment and use of the models.
Llama 3.1 marks a big milestone in open-source AI development, offering state-of-the-art performance while maintaining a deal with accessibility and responsible deployment. Its improved capabilities position it as a powerful competitor to leading closed-source models, transforming the landscape of AI research and application development.
Announced in February 2024 and made available for public preview in May 2024, Google’s Gemini 1.5 Pro also represented a big advancement in AI capabilities, offering improved performance across various tasks and modalities.
Key Capabilities:
- Multimodal Processing: Gemini 1.5 Pro can process and generate content across multiple modalities, including text, images, audio, and video.
- Prolonged Context Window: The model includes a massive context window of as much as 1 million tokens, expandable to 2 million tokens for select users. This enables for processing of in depth data, including 11 hours of audio, 1 hour of video, 30,000 lines of code, or entire books.
- Advanced Architecture: Gemini 1.5 Pro uses a Mixture-of-Experts (MoE) architecture, selectively activating essentially the most relevant expert pathways inside its neural network based on input types.
- Improved Performance: Google claims that Gemini 1.5 Pro outperforms its predecessor (Gemini 1.0 Pro) in 87% of the benchmarks used to judge large language models.
- Enhanced Safety Features: The model underwent rigorous safety testing before launch, with robust technologies implemented to mitigate potential AI risks.
Gemini 1.5 Pro Benchmarks and Performance
Gemini 1.5 Pro has demonstrated impressive results across various benchmarks:
- MMLU (Massive Multitask Language Understanding): 85.9% (5-shot setup), 91.7% (majority vote setup)
- GSM8K (Grade School Math): 91.7%
- MATH (Advanced mathematical reasoning): 58.5%
- HumanEval (Coding benchmark): 71.9%
- VQAv2 (Visual Query Answering): 73.2%
- MMMU (Multi-discipline reasoning): 58.5%
Google reports that Gemini 1.5 Pro outperforms its predecessor (Gemini 1.0 Ultra) in 16 out of 19 text benchmarks and 18 out of 21 vision benchmarks.
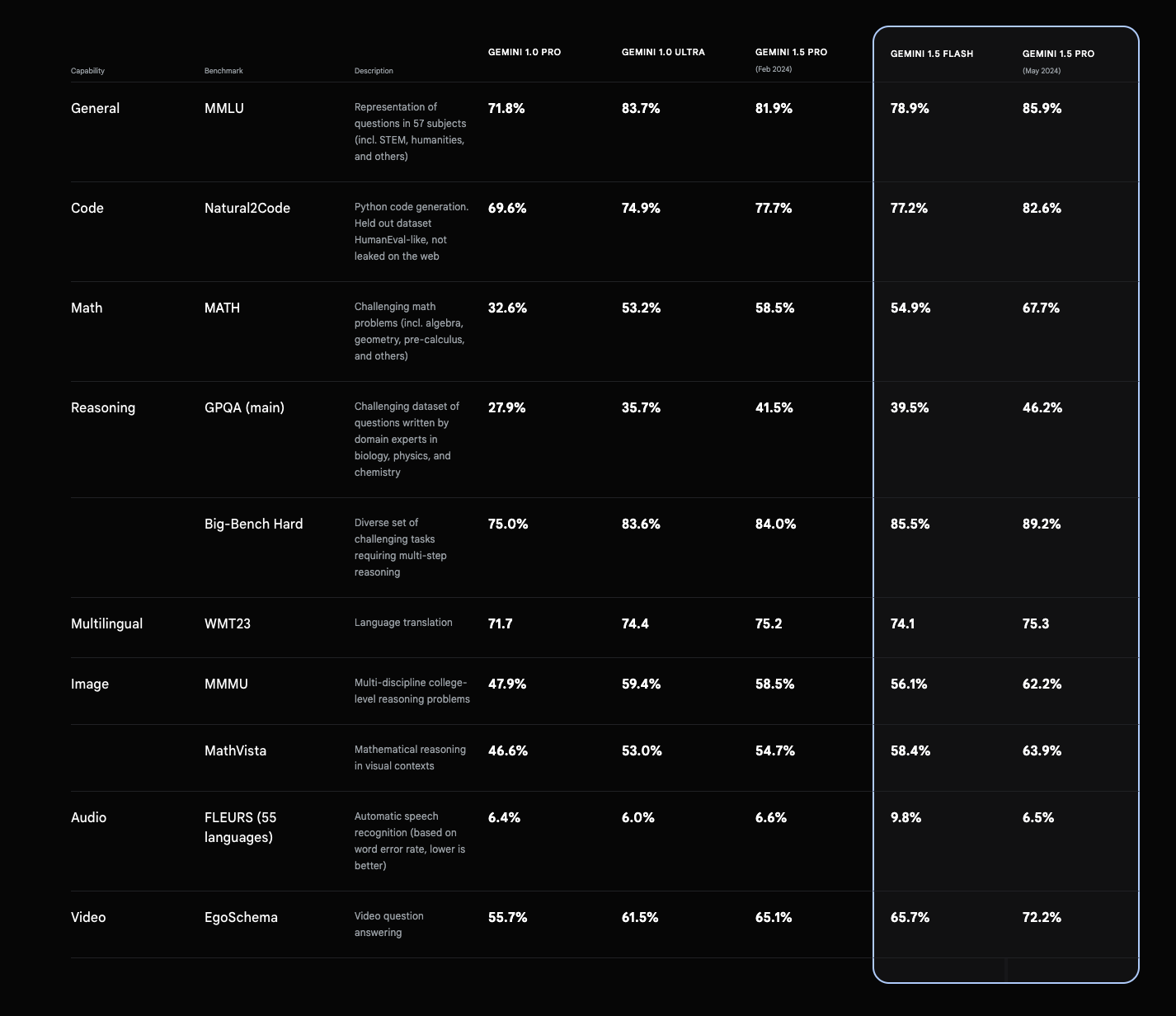
Gemini 1.5 Pro benchmarks (Google)
Key Features and Capabilities:
- Audio Comprehension: Evaluation of spoken words, tone, mood, and specific sounds.
- Video Evaluation: Processing of uploaded videos or videos from external links.
- System Instructions: Users can guide the model’s response style through system instructions.
- JSON Mode and Function Calling: Enhanced structured output capabilities.
- Long-context Learning: Ability to learn recent skills from information inside its prolonged context window.
Availability and Deployment:
- Google AI Studio for developers
- Vertex AI for enterprise customers
- Public API access
Released in August 2024 by xAI, Elon Musk’s artificial intelligence company, Grok-2 represents a big advancement over its predecessor, offering improved performance across various tasks and introducing recent capabilities.

Model Variants:
- Grok-2: The complete-sized, more powerful model
- Grok-2 mini: A smaller, more efficient version
Key Capabilities:
- Enhanced Language Understanding: Improved performance usually knowledge, reasoning, and language tasks.
- Real-Time Information Processing: Access to and processing of real-time information from X (formerly Twitter).
- Image Generation: Powered by Black Forest Labs’ FLUX.1 model, allowing creation of images based on text prompts.
- Advanced Reasoning: Enhanced abilities in logical reasoning, problem-solving, and sophisticated task completion.
- Coding Assistance: Improved performance in coding tasks.
- Multimodal Processing: Handling and generation of content across multiple modalities, including text, images, and potentially audio.
Grok-2 Benchmark Performance
Grok-2 has shown impressive results across various benchmarks:
- GPQA (Graduate-level Skilled Quality Assurance): 56.0%
- MMLU (Massive Multitask Language Understanding): 87.5%
- MMLU-Pro: 75.5%
- MATH: 76.1%
- HumanEval (coding benchmark): 88.4%
- MMMU (Multi-Modal Multi-Task): 66.1%
- MathVista: 69.0%
- DocVQA: 93.6%
These scores reveal significant improvements over Grok-1.5 and position Grok-2 as a powerful competitor to other leading AI models.
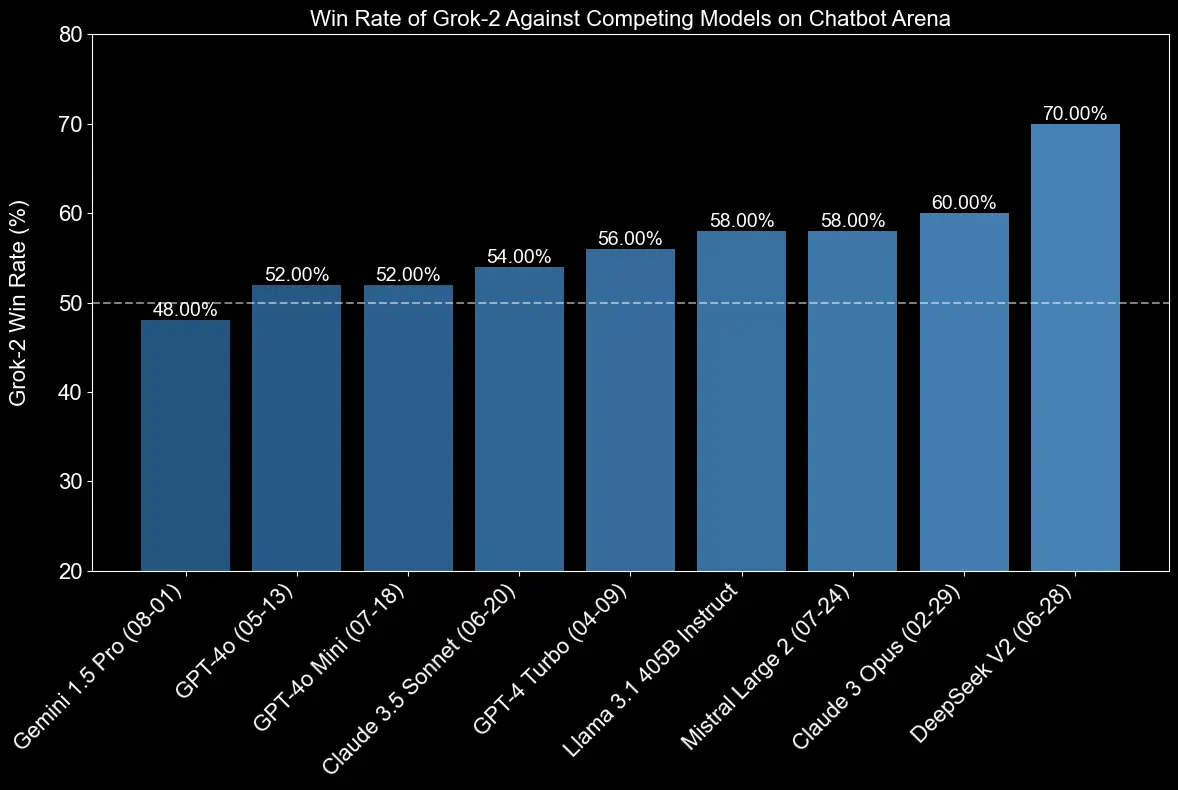
Grok-2 benchmarks (xAI)
Availability and Deployment:
- X Platform: Grok-2 mini is obtainable to X Premium and Premium+ subscribers.
- Enterprise API: Each Grok-2 and Grok-2 mini might be available through xAI’s enterprise API.
- Integration: Plans to integrate Grok-2 into various X features, including search and reply functions.
Unique Features:
- “Fun Mode”: A toggle for more playful and humorous responses.
- Real-Time Data Access: Unlike many other LLMs, Grok-2 can access current information from X.
- Minimal Restrictions: Designed with fewer content restrictions in comparison with some competitors.
Grok-2 Ethical Considerations and Safety Concerns
Grok-2’s release has raised concerns regarding content moderation, misinformation risks, and copyright issues. xAI has not publicly detailed specific safety measures implemented in Grok-2, resulting in discussions about responsible AI development and deployment.
Grok-2 represents a big advancement in AI technology, offering improved performance across various tasks and introducing recent capabilities like image generation. Nevertheless, its release has also sparked vital discussions about AI safety, ethics, and responsible development.
The Bottom Line on LLMs
As we have seen, the newest advancements in large language models have significantly elevated the sector of natural language processing. These LLMs, including Claude 3, GPT-4o, Llama 3.1, Gemini 1.5 Pro, and Grok-2, represent the head of AI language understanding and generation. Each model brings unique strengths to the table, from enhanced multilingual capabilities and prolonged context windows to multimodal processing and real-time information access. These innovations aren’t just incremental improvements but transformative leaps which might be reshaping how we approach complex language tasks and AI-driven solutions.
The benchmark performances of those models underscore their exceptional capabilities, often surpassing human-level performance in various language understanding and reasoning tasks. This progress is a testament to the ability of advanced training techniques, sophisticated neural architectures, and vast amounts of diverse training data. As these LLMs proceed to evolve, we will expect much more groundbreaking applications in fields similar to content creation, code generation, data evaluation, and automatic reasoning.
Nevertheless, as these language models develop into increasingly powerful and accessible, it’s crucial to deal with the moral considerations and potential risks related to their deployment. Responsible AI development, robust safety measures, and transparent practices might be key to harnessing the total potential of those LLMs while mitigating potential harm. As we glance to the long run, the continuing refinement and responsible implementation of those large language models will play a pivotal role in shaping the landscape of artificial intelligence and its impact on society.

