
A brand new benchmark proposal for artificial intelligence (AI) agents has emerged. The researchers claim that it’s difficult to measure agent performance using existing AI model benchmarks, and that a crucial variable called ‘cost’ should be taken under consideration.
MarkTechPost and VentureBeat reported on the sixth (local time) that Princeton University researchers identified problems with the AI agent benchmark currently in use and proposed a brand new evaluation method. Present a paperIt was reported that.
“AI agents are an exciting latest research direction, and agent development is driven by benchmarks,” the researchers wrote. “Current agent benchmarking and evaluation practices exhibit several shortcomings that pose challenges when deploying real-world applications.”
That’s, agent benchmarking has its own unique challenges and can’t be evaluated using existing model benchmarking methods.
First, he identified that overlooking the price issue is an issue. Since AI agents handle complex tasks, the running cost will be far more expensive than a single LLM for a similar query.
Nonetheless, agents currently under development are focused on increasing accuracy fairly than these points, so some systems are adopting methods akin to running multiple models concurrently and choosing one of the best answer through voting or comparison tools.
The researchers found that comparing a whole lot or 1000’s of responses can increase accuracy, nevertheless it comes with significant computational costs. While this may increasingly not be an enormous problem in a research setting where accuracy is maximized, it’s problematic in real-world application settings.
Otherwise, developers could find yourself creating useless, expensive artifacts simply to get high rankings on the leaderboard, he stressed.
Accordingly, it was suggested that it is crucial to graph the correlation between the evaluation results and the inference cost and find an appropriate balance point. Specifically, he stated that “in some cases, even when we try to extend the accuracy by a bit of bit, the price increases by dozens of times,” and “that doesn’t mean that it shows the optimal performance.”
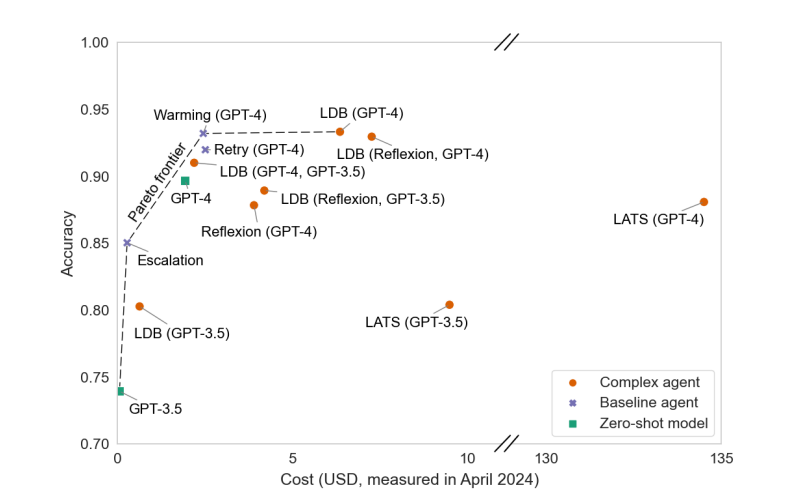
For instance, we tested cost-performance optimization in the favored benchmark ‘HotpotQA’ and presented a way to realize the optimal balance.
The researchers also identified the difference between evaluating models for research purposes and developing real-world applications, as inference costs play a big role in choosing a model when developing real-world applications.
It is just not easy to guage the inference cost of AI agents. Even for a similar model, the billing amount can vary depending on the operator, and the price of API calls can change repeatedly.
So to unravel this problem Website that adjusts model comparisons based on token pricewas created.

To guage this, we conducted a study on ‘NovelQA’, a benchmark for very long texts. Because of this, we found that there have been cases where there was a big difference between the benchmark results and actual applications.
For instance, the unique NobleQA benchmark found that Augmented Search Generation (RAG) performed much worse than the long-context model. Nonetheless, while RAG and the long-context model showed no significant difference in accuracy, the long-context model turned out to be 20 times dearer.
The final thing identified is the issue of ‘overfitting’.
Which means the benchmark data has been trained for too long, and the model memorizes and answers the answers from the dataset as an alternative of creating inferences. This happens since the benchmark data is old, and it is usually the essential reason why models that perform well on benchmarks don’t perform well in point of fact.
To deal with this issue, the researchers say benchmark developers should construct a “holdout test set” that separates training data from test data. After analyzing 17 benchmarks, the researchers found that a lot of them lacked holdout data sets.
This is claimed to end in overfitting and exploitation of benchmarks, and the emergence of vulnerable agents. The truth is, the WebArena test, which evaluates the power to work on various web sites, found several cases where agents can easily overfit. Which means even when an agent performs well on a benchmark, it might not work well on other sites.
The researchers warned that this problem could lead on to over-optimism in AI agent accuracy estimates.
We also concluded that because AI agents are a brand new field, there continues to be much to study testing methods.
“Benchmarking AI agents is latest and best practices are usually not yet established, making it difficult to differentiate real progress from hype,” the authors wrote. “This study suggests that benchmarking practices needs to be rethought because agents differ from existing AI models.”
Reporter Park Chan cpark@aitimes.com