
A robot control model has emerged that follows instructions from hand-drawn sketches as a substitute of text or images. The reason is that sketches are effective in depicting instructions which might be ambiguous or inaccurate when expressed in text or images.
Enterprise Beat reported on the eleventh (local time) that Google DeepMind and Stanford University researchers developed 'RT-Sketch,' a model that controls robots using sketches.
Language is an intuitive strategy to specify goals, but it might probably be inconvenient for detailed or precise manipulation instructions. Subsequently, images are efficient in depicting the specified goal for the robot intimately.
Nonetheless, images are sometimes difficult to create, and even when images can be found, they may be confusing if an excessive amount of detail is included.
Subsequently, it’s identified that models trained with goal images may overfit the training data and should experience difficulties in other environments. Overfitting implies that the model provides accurate predictions on training data, but fails to perform well on latest data.
“The thought for Sketch began with finding a strategy to enable robots to interpret furniture assembly manuals like those from IKEA and perform the needed manipulations,” the researchers said. “In these sorts of spatial tasks, language is commonly very ambiguous and the specified “The goal image can’t be used prematurely,” he said.
Sketching has the advantage of having the ability to simply explain the goal and contain a wealth of data. As well as, it might probably provide spatial information that’s difficult to specific with natural language commands, and may easily provide features of the specified spatial arrangement. At the identical time, it shows how the model determines which objects are related to the duty, making it easy to generalize the situation.
RT-Sketch modified the architecture of DeepMind's 'RT-1' model, which receives natural language commands as input and generates commands for a robot, to interchange natural language input with sketches and pictures.
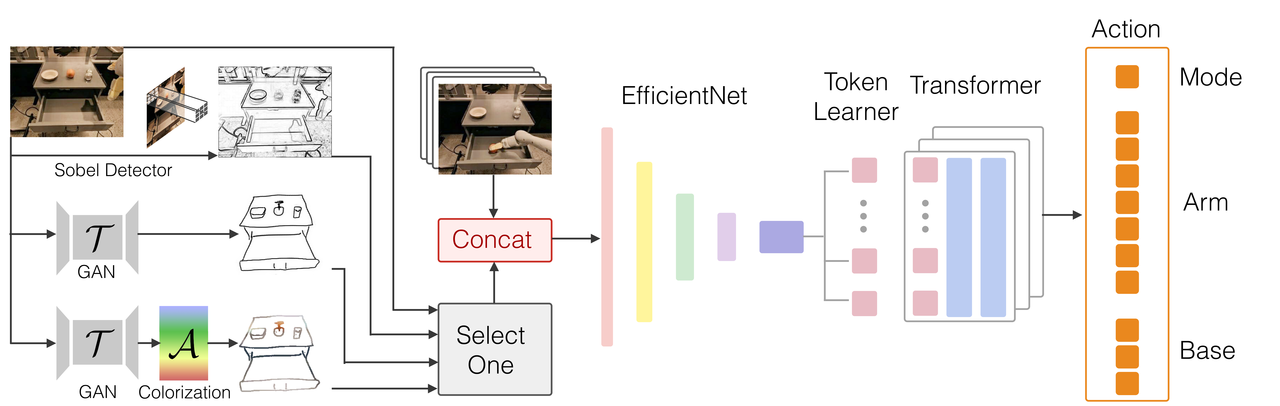
The researchers chosen training examples from videos of tasks corresponding to moving and manipulating objects, opening and shutting cabinets, and created hand-drawn sketches from goal video frames for every example. They then used the goal video frames along with the hand sketch to coach an image-sketch generation adversarial network (GAN) that robotically converts the image right into a sketch. Using this GAN, we created a goal sketch to coach the RT-Sketch model, and moreover supplemented the generated sketch with color enhancement and affine transformation.
RT-Sketch was trained using the goal sketch and original records created in this manner. The model generates robot commands to attain the goal through the specified goal image and rough sketch.
“RT-Sketch could also be useful for spatial tasks where describing the intended goal takes more time to explain verbally than to sketch, or when images will not be available,” the researchers said.
For instance, a verbal command corresponding to “Put the utensils next to the plate” may be ambiguous because of the different sorts of forks and knives and their various placements. RT-Sketch allows for precise instructions.
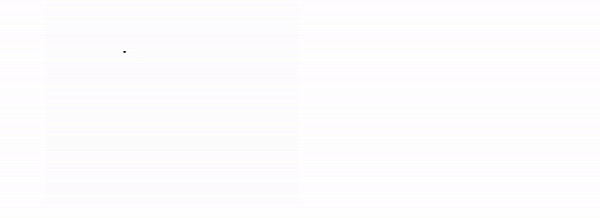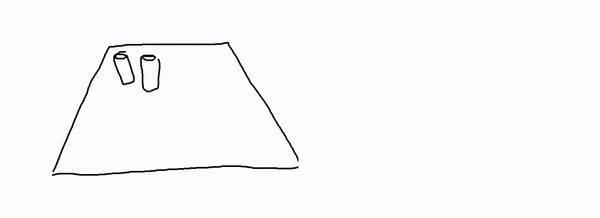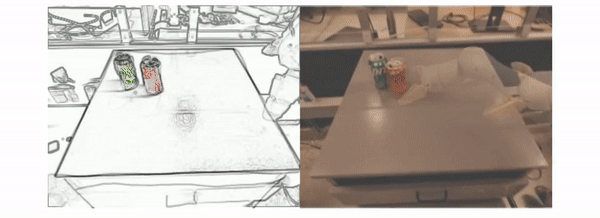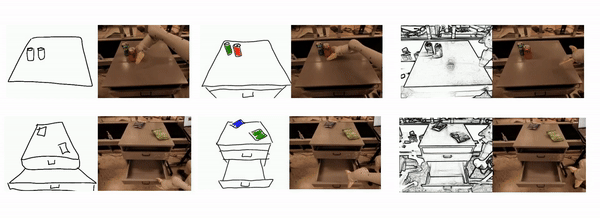
The researchers evaluated RT-Sketch through six different manipulations, including moving objects closer together, tapping a can on its side or upright, and shutting and opening a drawer.
Because of this, RT-Sketch showed similar performance to image or verbal commands on the whole and straightforward tasks.
Nonetheless, it performed a lot better in scenarios where the goal couldn’t be clearly expressed through verbal instructions. Moreover, even when the environment was cluttered and sophisticated, the model outperformed a picture condition model that followed image-based instructions.
In the longer term, the researchers plan to explore a wider range of applications for Sketch. It also said it could have a look at ways to mix it with other modes, corresponding to language, images and human motion.
The researchers explained, “Sketching has many benefits, corresponding to having the ability to convey actions through arrows, sub-goals through partial sketches, constraints through scribbling, and even semantic labels through scribbled text.”
Reporter Park Chan cpark@aitimes.com