
Five Suggestions for Writing Clean, Efficient and readable Code in PyTorch
Introduction
In the sector of knowledge science and programming on the whole, it is vitally vital to have the opportunity to jot down code that is straightforward to read and maintain. Surely you too have had the experience of writing code that appeared to work superb and that was pretty clear, but then you definately reread it a day or every week later and it looked incomprehensible. Much more obvious is that this difficulty when you’ve got to review code written by other people.
In AI, it’s critically vital to jot down clear and comprehensible code, because we frequently should arrange several experiments, after which try multiple models, multiple data, and a ton of hyperparameters.
In this text, I share with you some suggestions that I exploit when programming with PyTorch which you could apply immediately and I hope they are going to enable you grow to be slightly more efficient in your work as a knowledge scientist.
Create a DataModule class to administer your data
In this instance, I will probably be working with the well-known MNIST dataset. Although the practices I exploit could appear unnecessary on this case, because the various libraries already facilitate using such easy datasets, they will all the time turn out to be useful when working with more complex datasets.
Again and again when working with nonstandard datasets we’ve to undergo different steps, comparable to downloading the info, structuring folders and subfolders to separate the info, making a custom Dataset class, and rather more. So it might be useful to create a DataModule class that takes care of every little thing there’s to do inside it and provides two functions that directly return the info loaders that we are going to use for training.
Having such a category will allow us to have a cleaner and more scalable workflow on a big scale. Let’s have a look at a straightforward example.
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensorclass DataModule:
def __init__(self, bs = 64) -> None:
self.bs = bs
self.training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
self.valid_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
def train_dataloader(self):
return torch.utils.data.DataLoader(self.training_data, batch_size=self.bs, shuffle=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(self.valid_data, batch_size=4 * self.bs, shuffle=False)
On this case, the DataModule class takes care of making datasets and instantiating dataloaders using two functions. In this fashion, within the principal function, I can simply call the train_dataloader() and val_dataloader() functions to access my data. Usually, if you’ve got some data retrieval tasks that you should perform to gather your dataset, it’s an excellent practice so as to add them to the DataModule class, which might then be used to instantiate dataloaders. In this fashion, you may access the info in a simple manner.
Let’s reproduce TensorFlow fit method
I’m not an enormous fan of TensorFlow, the truth is, unless required I almost all the time work with PyTorch. Though, I find that the fit() approach to TensorFlow is kind of handy. In actual fact, after you’ve got created a model you simply must call model.fit(data) to coach it, somewhat such as you do with models in scikit-learn.
So why not recreate something similar in PyTorch as well?
What we’ll do in the following example is to define a fit function that trains the network on the MNIST data by taking as input the DataModule created earlier. After that, we’ll make this function a technique of our class that defines the model.
This manner at any time when we would like to create a special model, we could all the time associate it with the fit() function, which stays unchanged.
class MNISTNet(nn.Module):
def __init__(self) -> None:
super(MNISTLogistic, self).__init__()
self.flatten = nn.Flatten()
self.lin = nn.Linear(784,10)def forward(self, xb):
return self.lin(torch.flatten(xb,1))
def fit(self: nn.Module, datamodule, epochs:int, loss_fn = nn.CrossEntropyLoss()):
train_dataloader = datamodule.train_dataloader()
val_dataloader = datamodule.val_dataloader()
opt = configure_optimizer(self)
train_dataloader = datamodule.train_dataloader()
for epoch in range(epochs):
self.train()
for xb, yb in train_dataloader:
pred = self(xb)
loss = loss_fn(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
self.eval()
with torch.no_grad():
valid_loss = sum(loss_fn(self(xb), yb) for xb, yb in val_dataloader)
MNISTLogistic.fit = fit
Now we are able to use model.fit(datamodule = datamodule, epochs = 3) to run our training.
Progress Bar
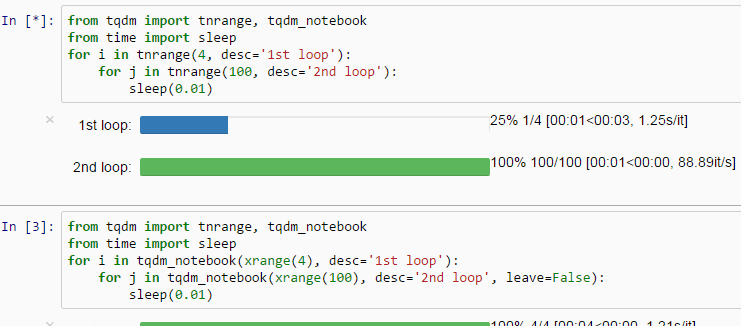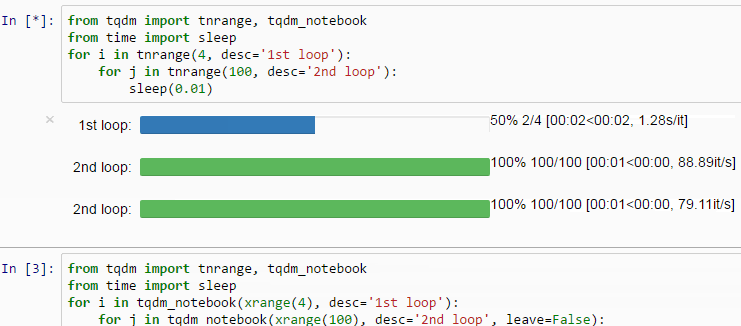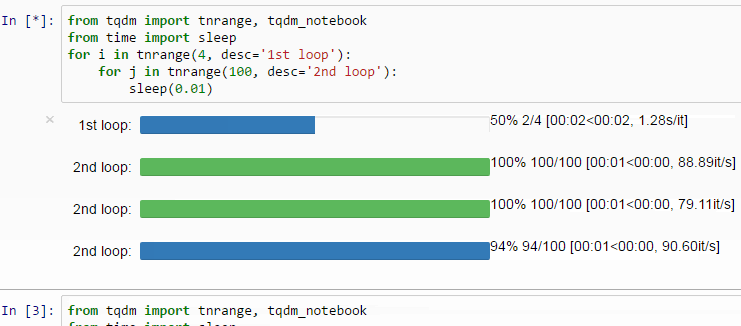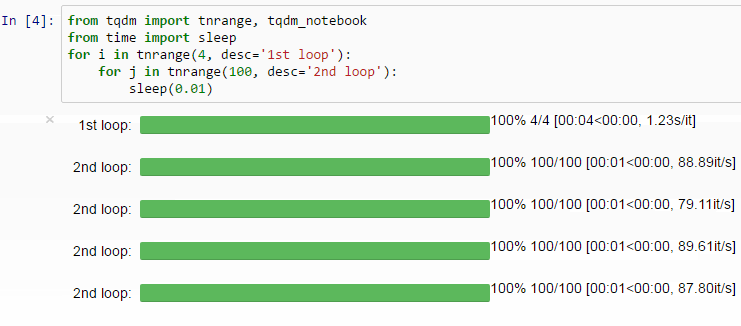
Through the model training, it is actually annoying to not have hints about how long it’s going to take to complete. But fortunately, it is feasible to implement a progress bar in PyTorch in a extremely easy way.
Just use the tqdm function and wrap the dataloader and explicitly state the whole length of the dataloader with len(dataloader).
In this fashion, a progress bar will appear as if by magic, making the output rather more visually appealing.
!pip install tqdm
from tqdm import tqdmfor index, (xb,yb) in tqdm(enumerate(train_loader), total = len(train_loader))
pred = self(xb)
loss = loss_fn(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
Evaluation Metrics
I don’t know why but after I read codes written in PyTorch I very often see people implementing common metrics by hand, comparable to precision, recall, accuracy…
Nonetheless, this will not be the case after they work with other libraries comparable to scikit-learn. Implementing these metrics throughout the training function could make the function difficult to read, and maybe bugs are inserted much more easily.
My suggestion then is to make use of the metrics already present in libraries comparable to scikit-learn when working. This permits us to make use of code that might be more robust but more importantly saves us time!
In fact, the discussion is different if there’s a must implement custom metrics, so when you are doing research on, for instance, latest methods for model evaluation.
Particularly when beginning to develop a project and we would like to make use of standard metrics to see if we’re entering into the precise direction, I find it useful to make use of the classification_report function of scikit-learn. Let’s have a look at an example.
from sklearn.metrics import classification_report
preds = [0, 1, 1, 0, 1, 0, 1, 1, 0, 1]
labels = [1, 0, 0, 1, 1, 1, 0, 0, 1, 1,]
print(classification_report(labels, preds))

As a developer, I all the time attempt to make my code clear and clean (and bug-free!😉). I all the time attempt to consider the proven fact that my code have to be as comprehensible as possible even without using comments. Due to this fact, I like to learn easy-to-use tricks that I can implement immediately in my code.
If this text was helpful to you follow me to read my next articles of this sort! 😊
Marcello Politi