
With a bonus tip
Jupyter Notebook is one of the sought-after IDEs for just about all Python-oriented programming tasks corresponding to data science, machine learning, scientific computing, and plenty of more.
Its interactive coding capabilities make it the go-to tool not just for beginners but experts as well.
Yet, despite its widespread usage, a lot of its users don’t use it to its full potential.
Because of this, they have a tendency to make use of Jupyter using its default interface/capabilities, which, for my part, will be significantly improved to supply a richer experience.
Due to this fact, in this text, I’ll present 5 cool Jupyter hacks that you almost certainly never knew even existed.
These will help you unlock latest levels of productivity and creativity with this powerful tool.
Let’s begin 🚀!
Often once we load a DataFrame in Jupyter, we preview it by printing. That is shown below:

Nevertheless, it hardly tells anything about what’s inside this data.
Because of this, one has to dig deeper by analyzing it, which involves easy yet repetitive code.
As an alternative, use Jupyter-DataTables. You may install it as follows:
To make use of it, run the next code in Jupyter:
It supercharges the default preview of a DataFrame with many useful features.
Because of this, every time you print a DataFrame, it’s going to appear far more elegant as shown below.
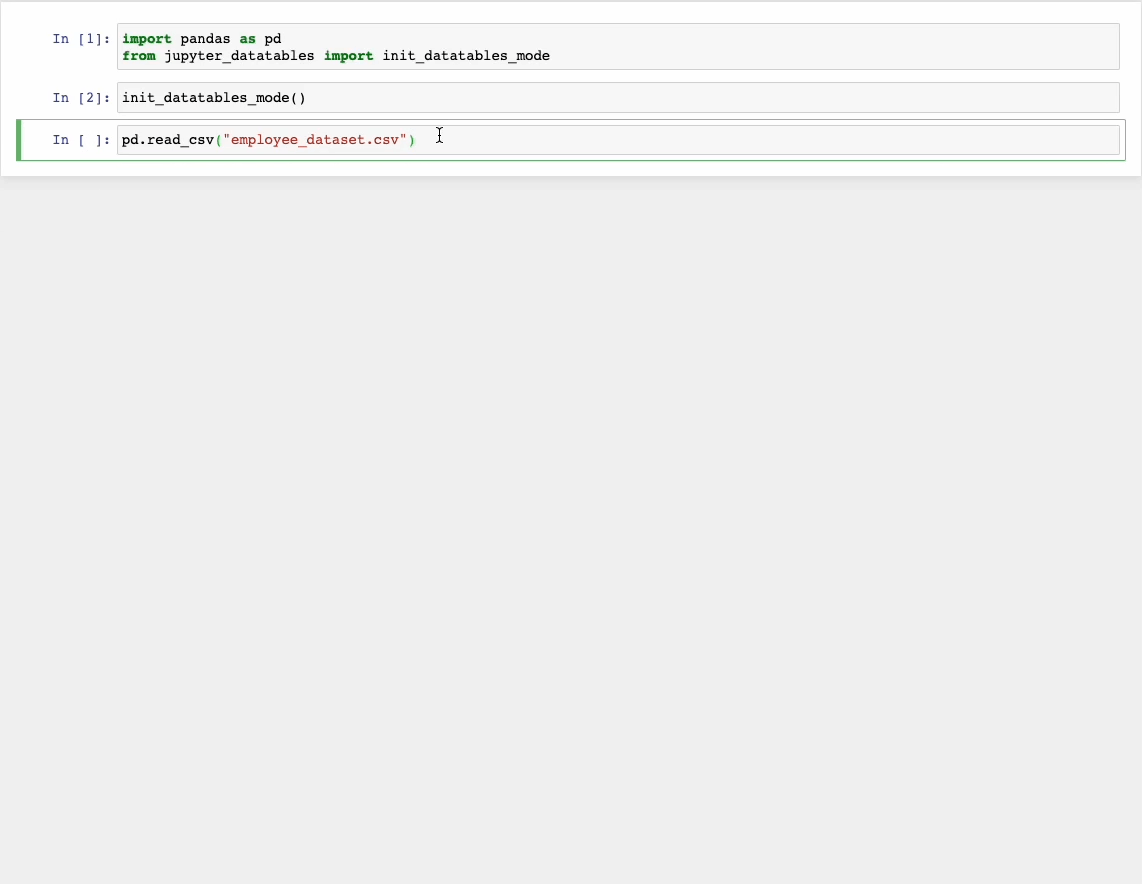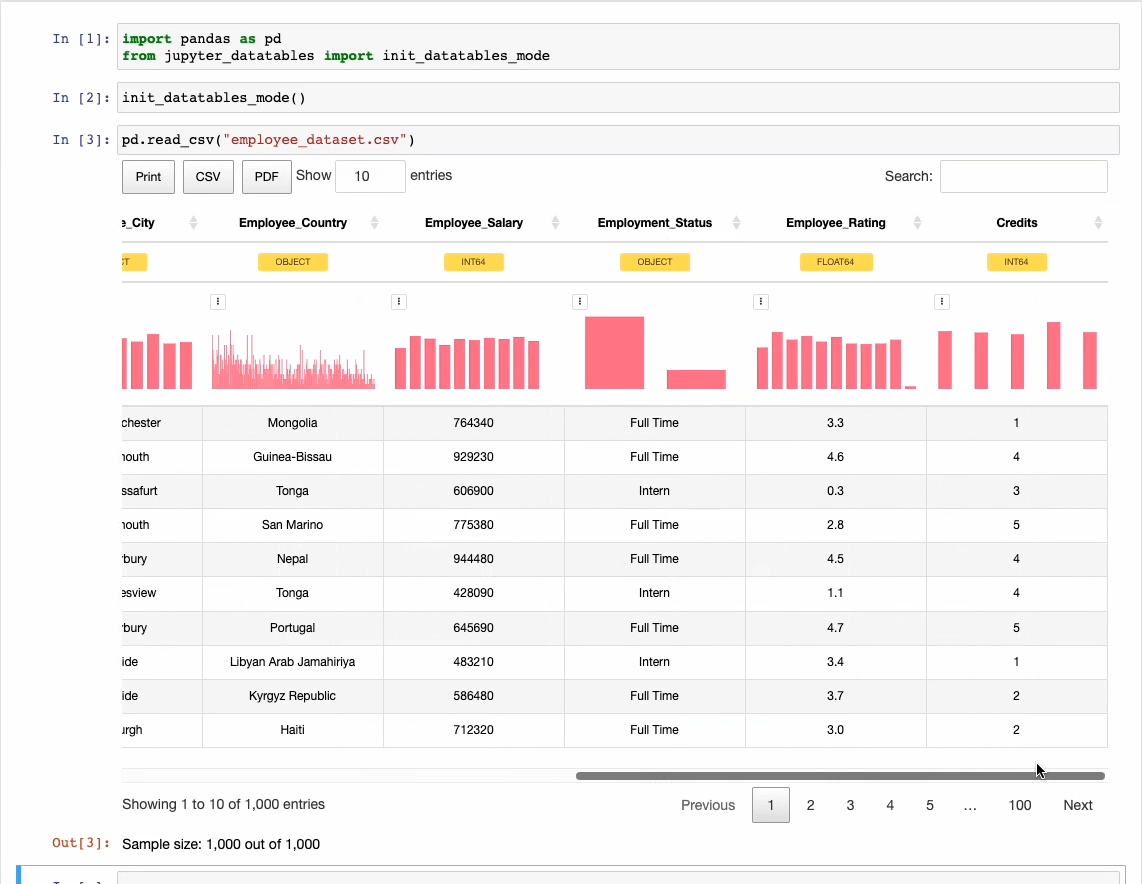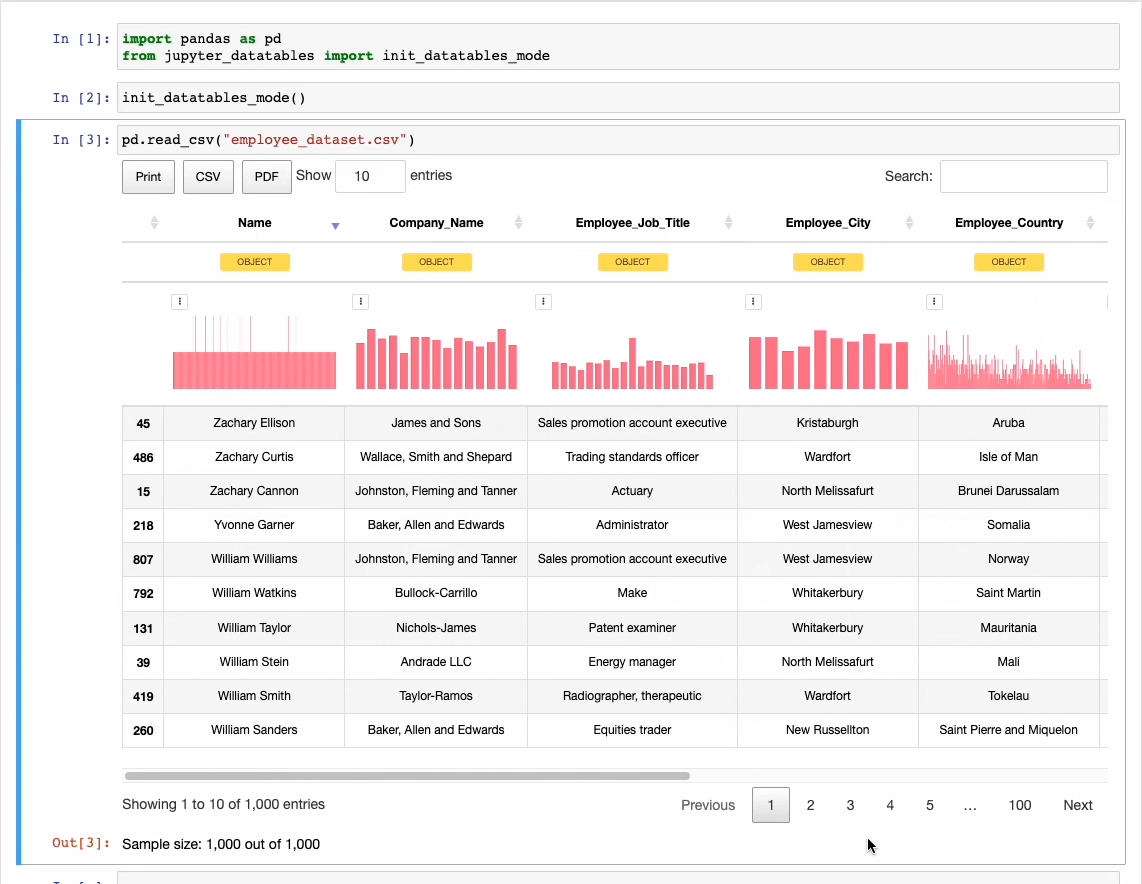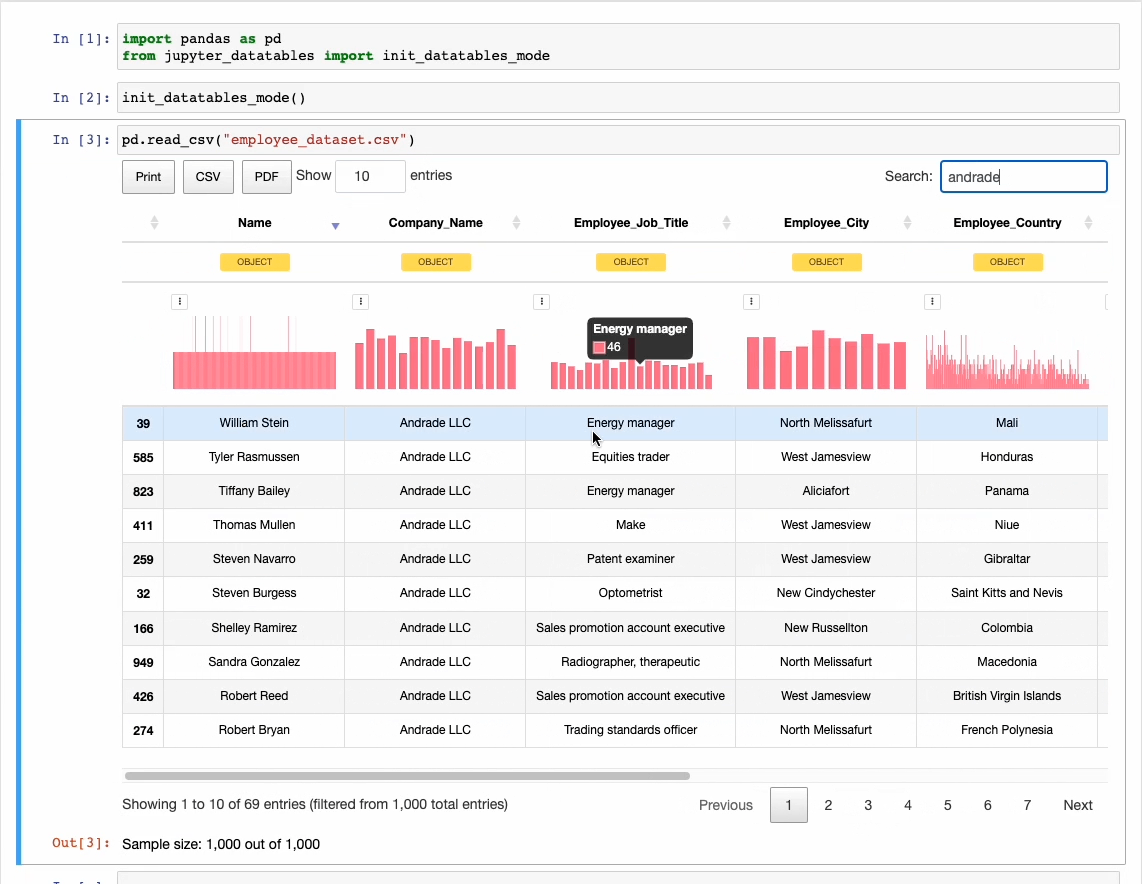
This richer preview provides sorting, filtering, exporting, and pagination operations together with column distribution and data types
Not all data you get is labeled beforehand.
Thus, typically with unlabeled data, one could have to spend a while annotating/labeling it.
Slightly than previewing the files externally and labeling them or constructing a fancy annotation pipeline, you’ll be able to annotate in only a couple of lines of code using 𝐢𝐩𝐲𝐚𝐧𝐧𝐨𝐭𝐚𝐭𝐞.
It provides a Jupyter widget specifically for data annotation.
Run the next commands to put in it:
Data annotation becomes easier by clicking buttons. Thus, ipyannotate lets you attach data labels to buttons.
Consider now we have some images of cats and dogs (unlabeled). We will create an annotation pipeline as follows:
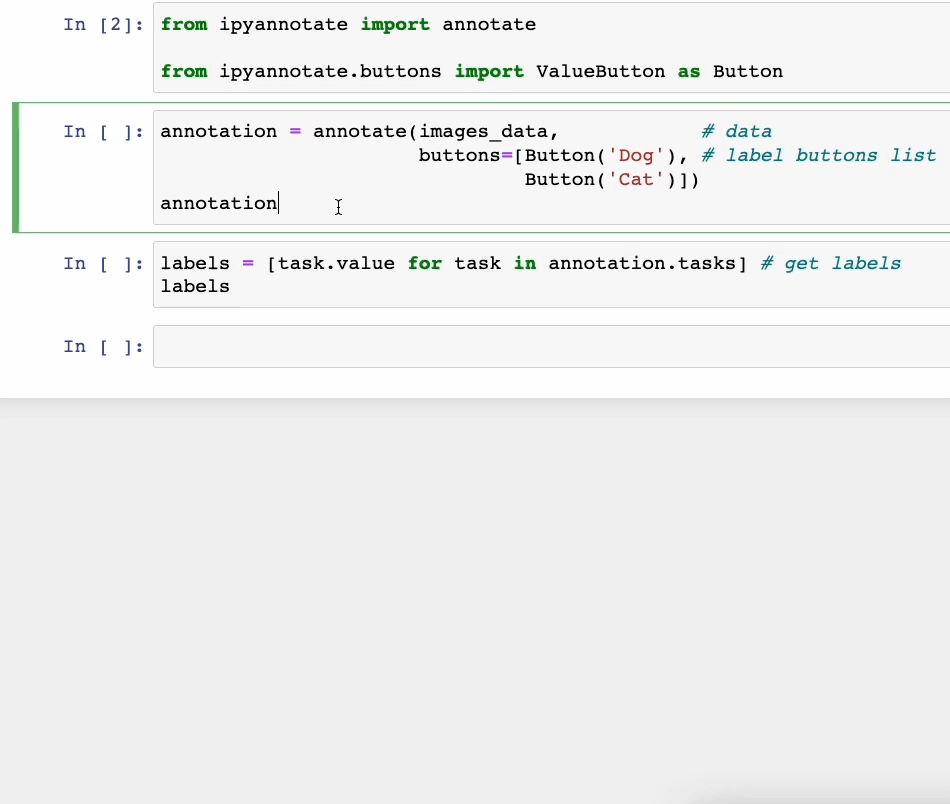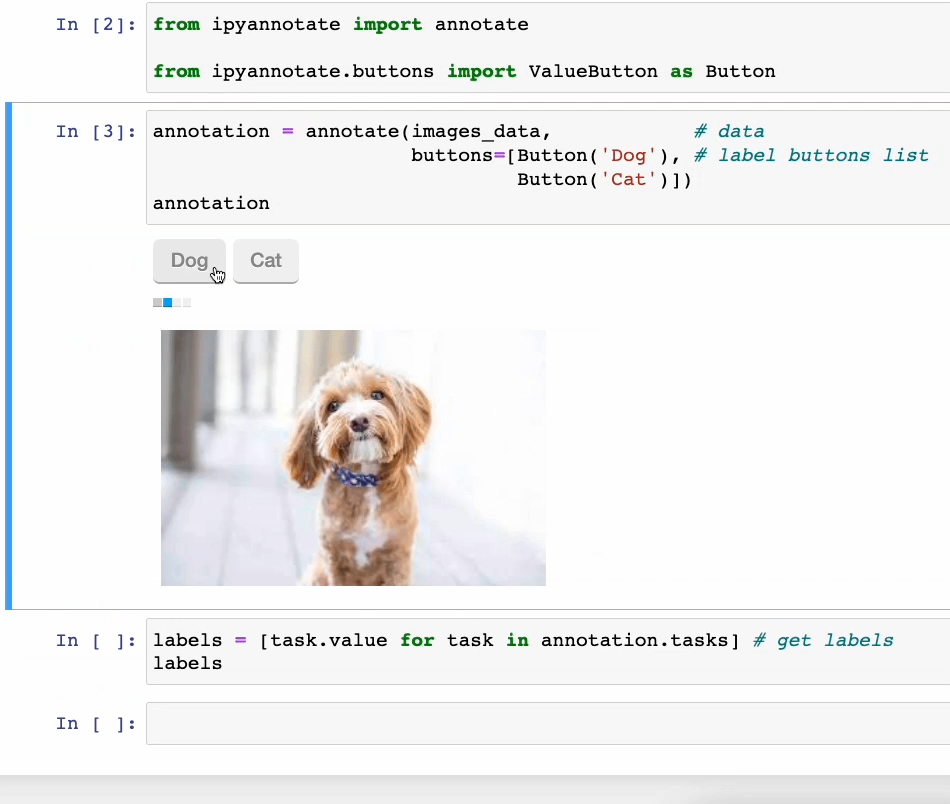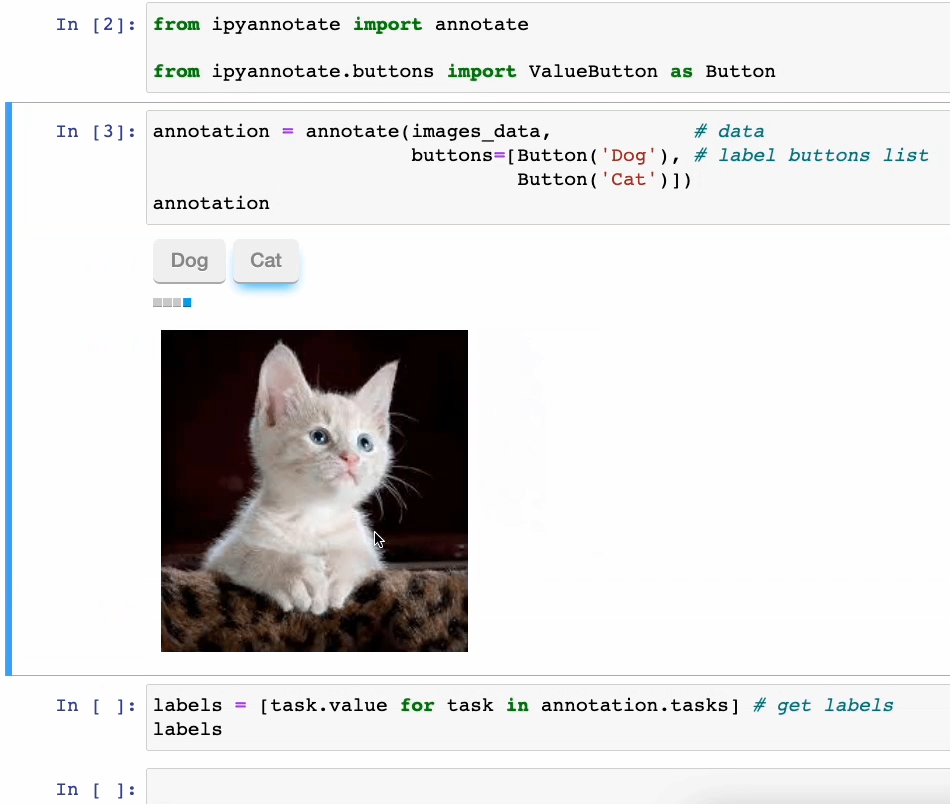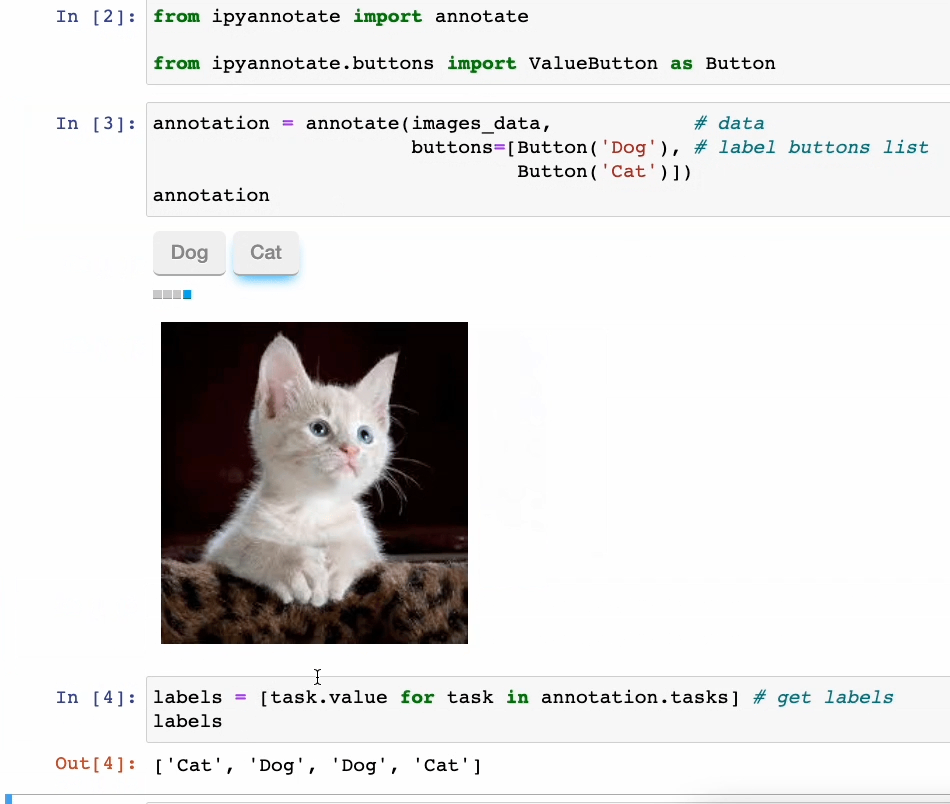
As shown above, you’ll be able to annotate your data by simply clicking the corresponding button.
What’s more, you may as well retrieve the labels and use them on your data pipeline as required.
While working in Jupyter, it’s common to forget the parameters of a function and visit the official docs (or StackOverflow).
Nevertheless, you’ll be able to view the documentation within the notebook itself.
Pressing 𝐒𝐡𝐢𝐟𝐭-𝐓𝐚𝐛 opens the documentation panel. This is incredibly useful and saves time as one doesn’t should open the official docs each time.
A demo is shown below:
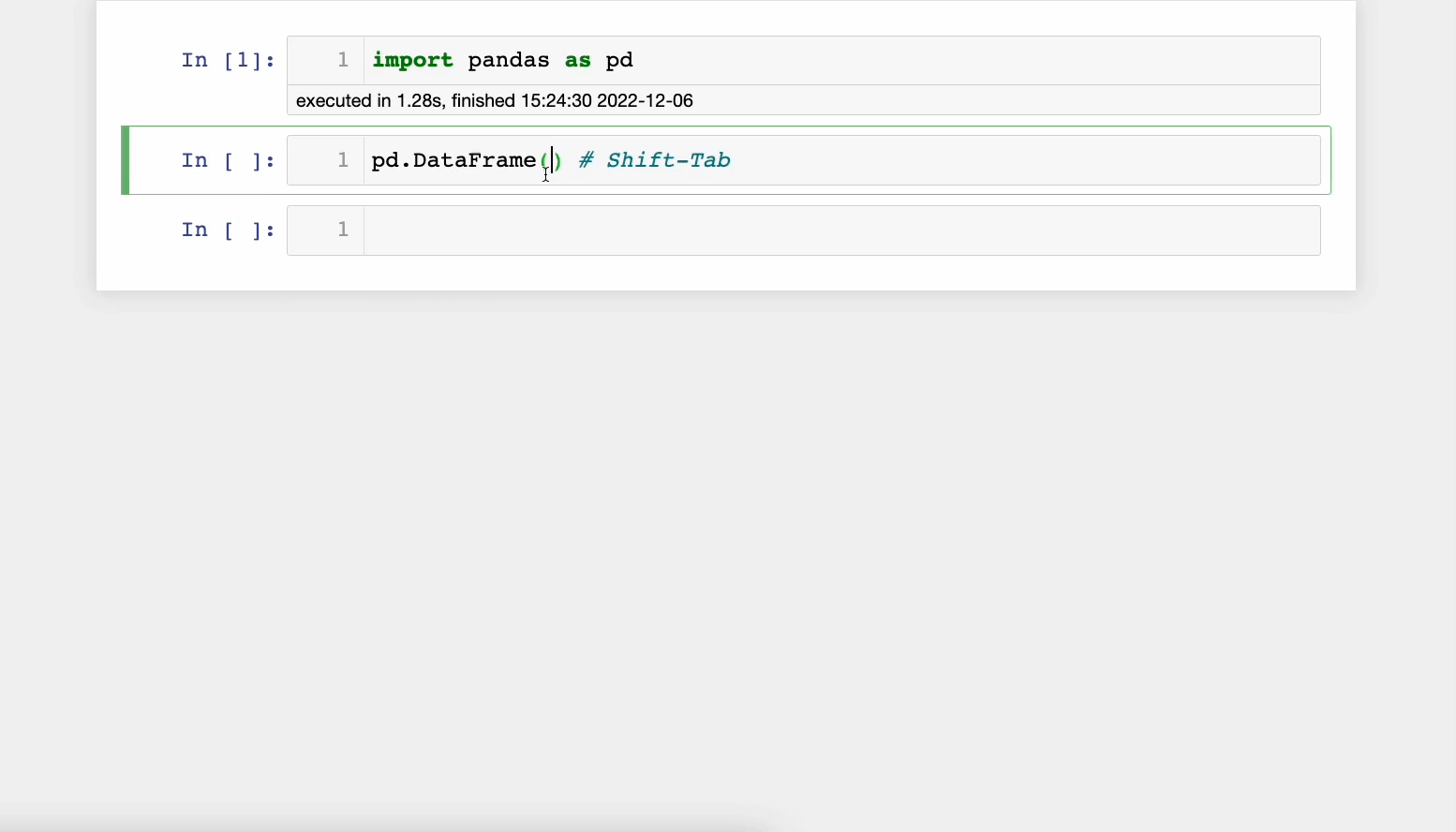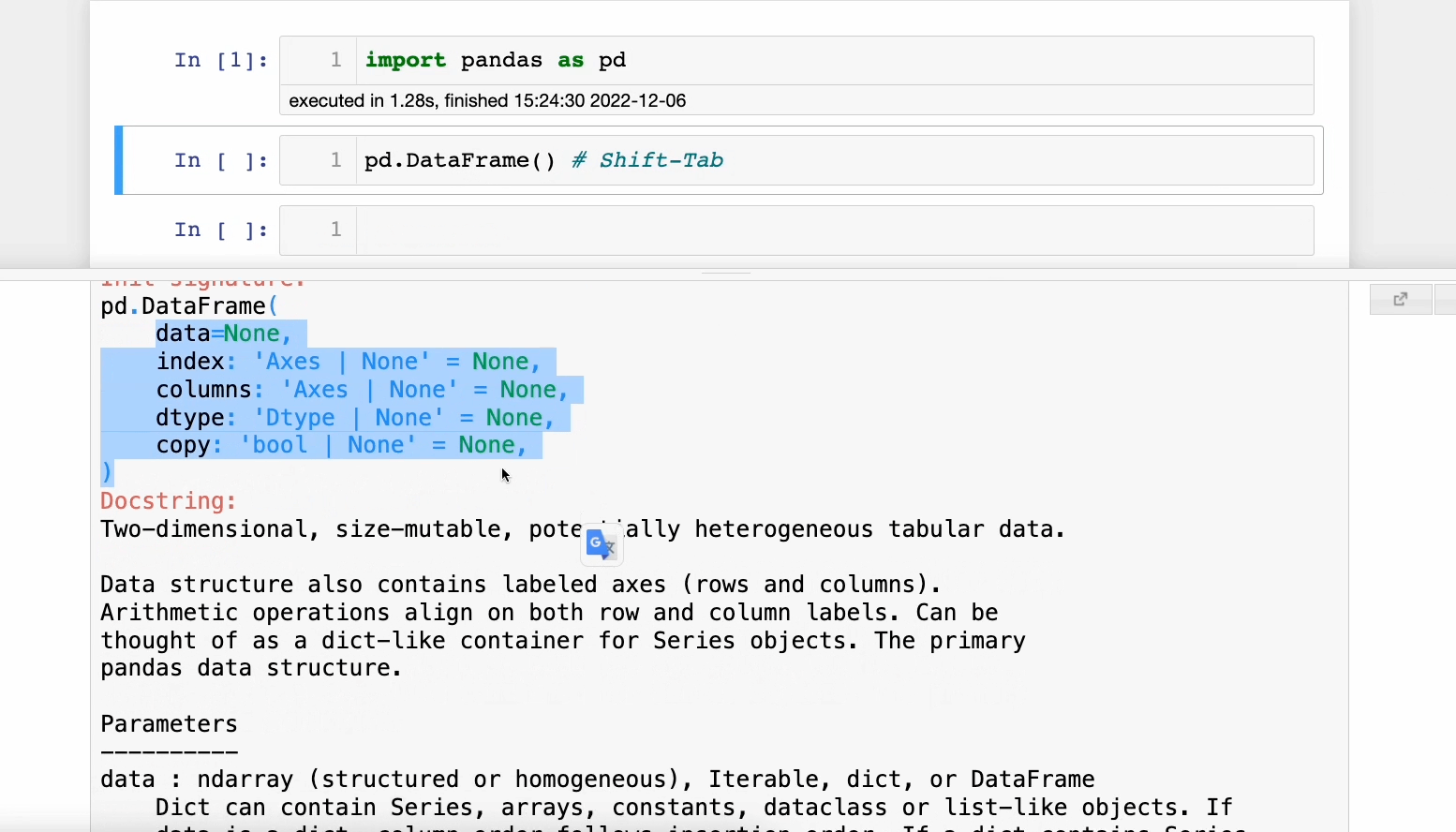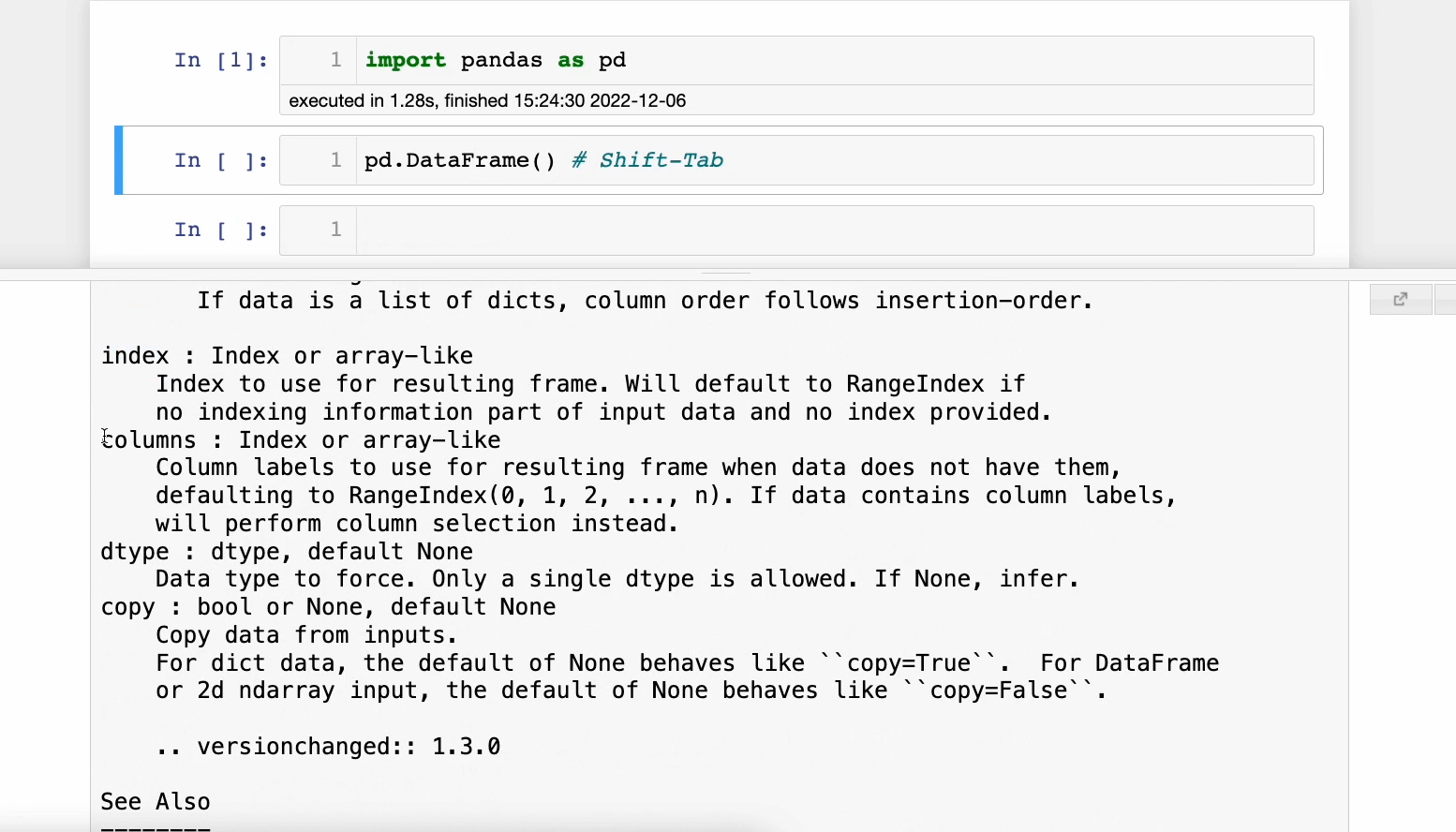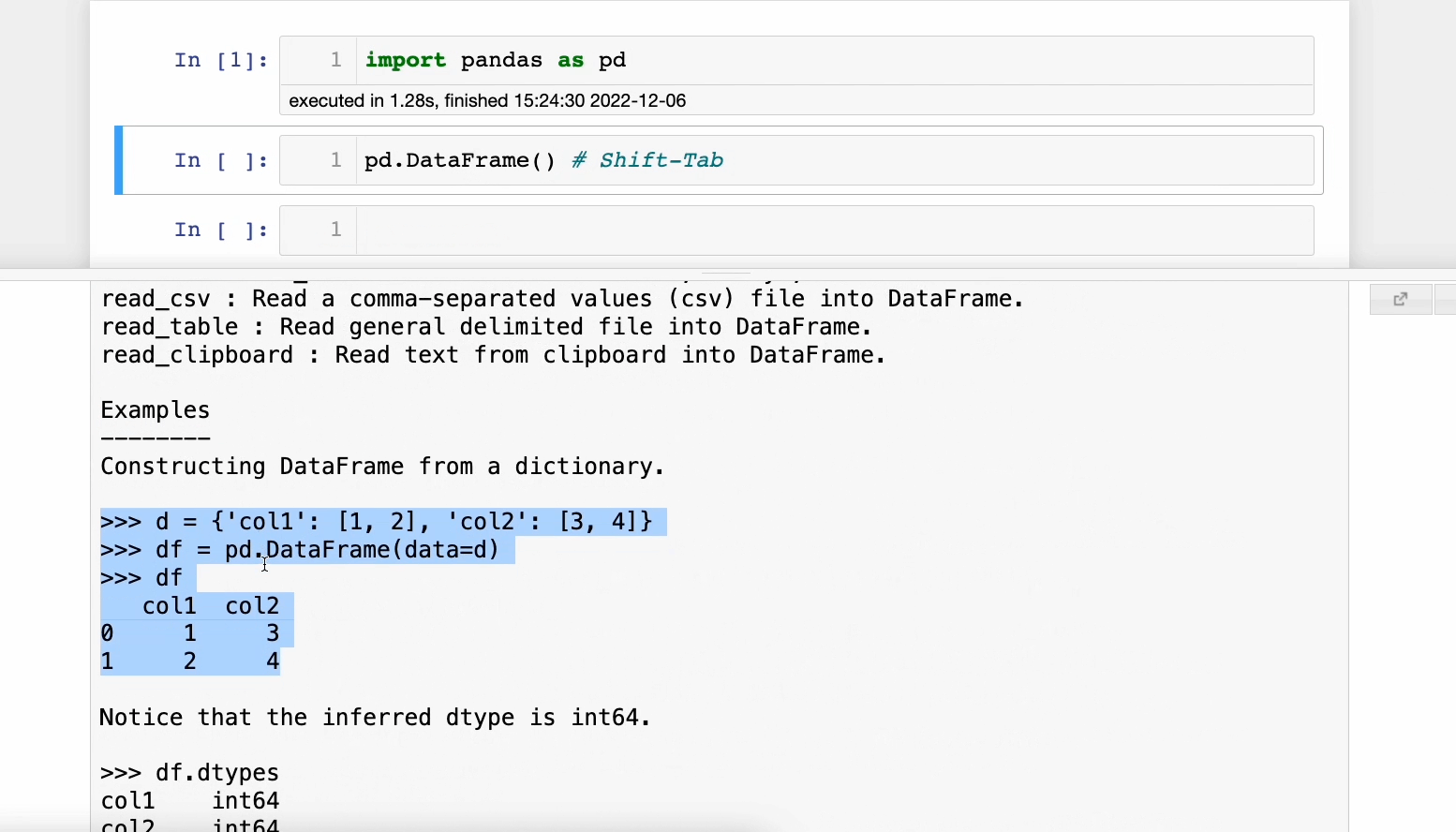
This feature also works on your custom functions.
After running some code in a Jupyter cell, we regularly navigate away to do another work within the meantime.
Here, one has to repeatedly get back to the Jupyter tab to examine whether the cell has been executed or not.
To avoid this, you need to use the %%𝐧𝐨𝐭𝐢𝐟𝐲 magic command from the 𝐣𝐮𝐩𝐲𝐭𝐞𝐫𝐧𝐨𝐭𝐢𝐟𝐲 extension.
Because the name suggests, it notifies the user upon completion (each successful and unsuccessful) of a Jupyter cell via a browser notification.
To put in it, run the next command:
Next, load the extension:
And done!
Now, every time you ought to get notified, enter the next magic command at the highest of the cell:
Every time the cell will finish its execution, you’ll receive the next notification:

Clicking on the notification will take you back to the Jupyter tab.
While using Jupyter, we typically print many details to trace the code’s progress.
Nevertheless, it gets frustrating when the output panel has gathered a bunch of details, but we’re only concerned about essentially the most recent output.
Furthermore, scrolling to the underside of the output every time will be annoying too.
To clear the output of the cell, you need to use the 𝗰𝗹𝗲𝗮𝗿_𝗼𝘂𝘁𝗽𝘂𝘁 method from the 𝗜𝗣𝘆𝘁𝗵𝗼𝗻 package.
IPython comes pre-installed with Python, so no installation is required.
You may import the tactic as follows:
When invoked, it’s going to remove the present output of the cell, after which you’ll be able to print the most recent details.
A demo is shown below:
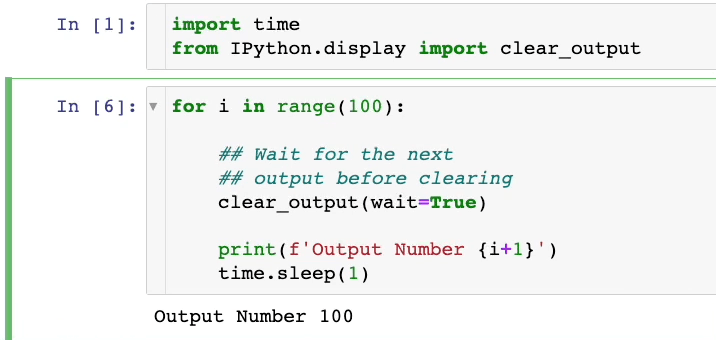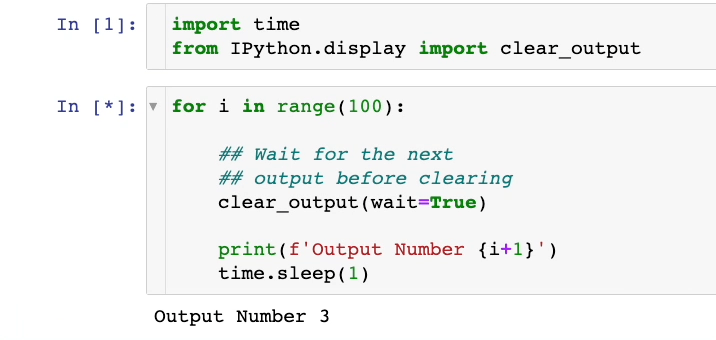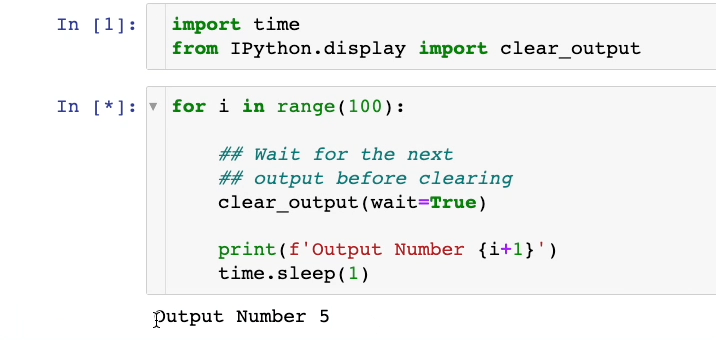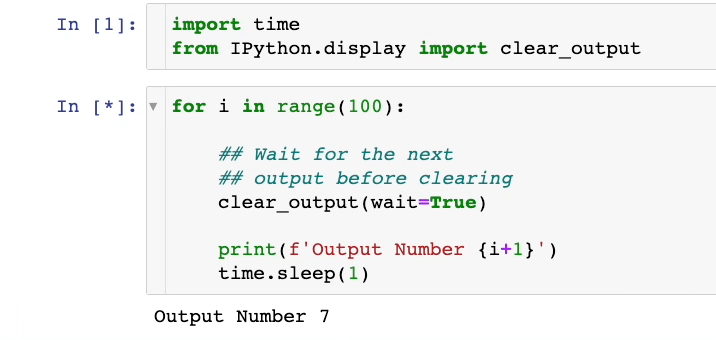
As demonstrated above, we only see the most recent output within the cell. The previous outputs are being erased.
Although the above-mentioned suggestions will significantly enrich your Jupyter experience, there are still many things that I struggle to do with Jupyter.
For example, Jupyter sucks in the case of collaboration. Because it runs locally, there is no such thing as a strategy to embed real-time collaboration capabilities in Jupyter where teams can work together, add comments, track progress, etc.
What’s more, sharing is equally painful. If I ever should share my notebook with someone, the one strategy to try this is by emailing them or hosting it online, on GitHub, as an example, and sharing the link.
Lastly, many data science tasks will not be just limited to Python. They equally involve SQL, which is essentially used to interact with organizational databases.
Nevertheless, integrating SQL in Jupyter is possible but a tedious process.
Solution
Frustrated with these limitations, I began in search of alternatives, and I’m glad I discovered Deepnote.
Without having to learn anything latest about methods to use it, it took away all the constraints of Jupyter in a snap and has consistently offered me an enriching Jupyter-like experience.
Sharing, collaborating, using SQL, creating charts with none code, connecting to a database, etc., all the things is seamlessly integrated into Deepnote.
While I understand that Jupyter tends to supply a generalized experience for all Python users, it miserably fails to handle all of the pain points of knowledge scientists, especially those working in teams.
Deepnote, for my part, is a supercharged version of Jupyter for all data-driven projects, and it is best to definitely test it out.
With this, we come to the tip of this blog.
Congratulations on learning a couple of incredible hacks for Jupyter notebook. I’m sure the following tips will level up your python programming productivity.
Also, I’d like to know what are your favorite hacks while using Jupyter notebook.
As all the time, thanks for reading!