

In July this 12 months, Hugging Face organized a Flax/JAX Community Week, and invited the community to submit projects to coach Hugging Face transformers models within the areas of Natural Language Processing (NLP) and Computer Vision (CV).
Participants used Tensor Processing Units (TPUs) with Flax and JAX. JAX is a linear algebra library (like numpy) that may do automatic differentiation (Autograd) and compile all the way down to XLA, and Flax is a neural network library and ecosystem for JAX. TPU compute time was provided free by Google Cloud, who co-sponsored the event.
Over the following two weeks, teams participated in lectures from Hugging Face and Google, trained a number of models using JAX/Flax, shared them with the community, and provided a Hugging Face Spaces demo showcasing the capabilities of their model. Roughly 100 teams participated within the event, and it resulted in 170 models and 36 demos.
Our team, like probably many others, is a distributed one, spanning 12 time zones. Our common thread is that all of us belong to the TWIML Slack Channel, where we got here together based on a shared interest in Artificial Intelligence (AI) and Machine Learning (ML) topics.
We fine-tuned the CLIP Network from OpenAI with satellite images and captions from the RSICD dataset. The CLIP network learns visual concepts by being trained with image and caption pairs in a self-supervised manner, by utilizing text paired with images found across the Web. During inference, the model can predict probably the most relevant image given a text description or probably the most relevant text description given a picture. CLIP is powerful enough to be utilized in zero-shot manner on on a regular basis images. Nevertheless, we felt that satellite images were sufficiently different from on a regular basis images that it could be useful to fine-tune CLIP with them. Our intuition turned out to be correct, because the evaluation results (described below) shows. On this post, we describe details of our training and evaluation process, and our plans for future work on this project.
The goal of our project was to supply a useful service and reveal methods to use CLIP for practical use cases. Our model might be utilized by applications to look through large collections of satellite images using textual queries. Such queries could describe the image in totality (for instance, beach, mountain, airport, baseball field, etc) or search or mention specific geographic or man-made features inside these images. CLIP can similarly be fine-tuned for other domains as well, as shown by the medclip-demo team for medical images.
The flexibility to look through large collections of images using text queries is an immensely powerful feature, and might be used as much for social good as for malign purposes. Possible applications include national defense and anti-terrorism activities, the power to identify and address effects of climate change before they turn out to be unmanageable, etc. Unfortunately, this power will also be misused, comparable to for military and police surveillance by authoritarian nation-states, so it does raise some ethical questions as well.
You possibly can read in regards to the project on our project page, download our trained model to make use of for inference on your personal data, or see it in motion on our demo.
Training
Dataset
We fine-tuned the CLIP model primarily with the RSICD dataset. This dataset consists of about 10,000 images collected from Google Earth, Baidu Map, MapABC, and Tianditu. It’s provided freely to the research community to advance distant sensing captioning via Exploring Models and Data for Distant Sensing Image Caption Generation (Lu et al, 2017). The pictures are (224, 224) RGB images at various resolutions, and every image has as much as 5 captions related to it.

As well as, we used the UCM Dataset and the Sydney dataset for training, The UCM dataset relies on the UC Merced Land Use dataset. It consists of 2100 images belonging to 21 classes (100 images per class), and every image has 5 captions. The Sydney dataset comprises images of Sydney, Australia from Google Earth. It comprises 613 images belonging to 7 classes. Images are (500, 500) RGB and provides 5 captions for every image. We used these additional datasets because we were undecided if the RSICD dataset could be large enough to fine-tune CLIP.
Model
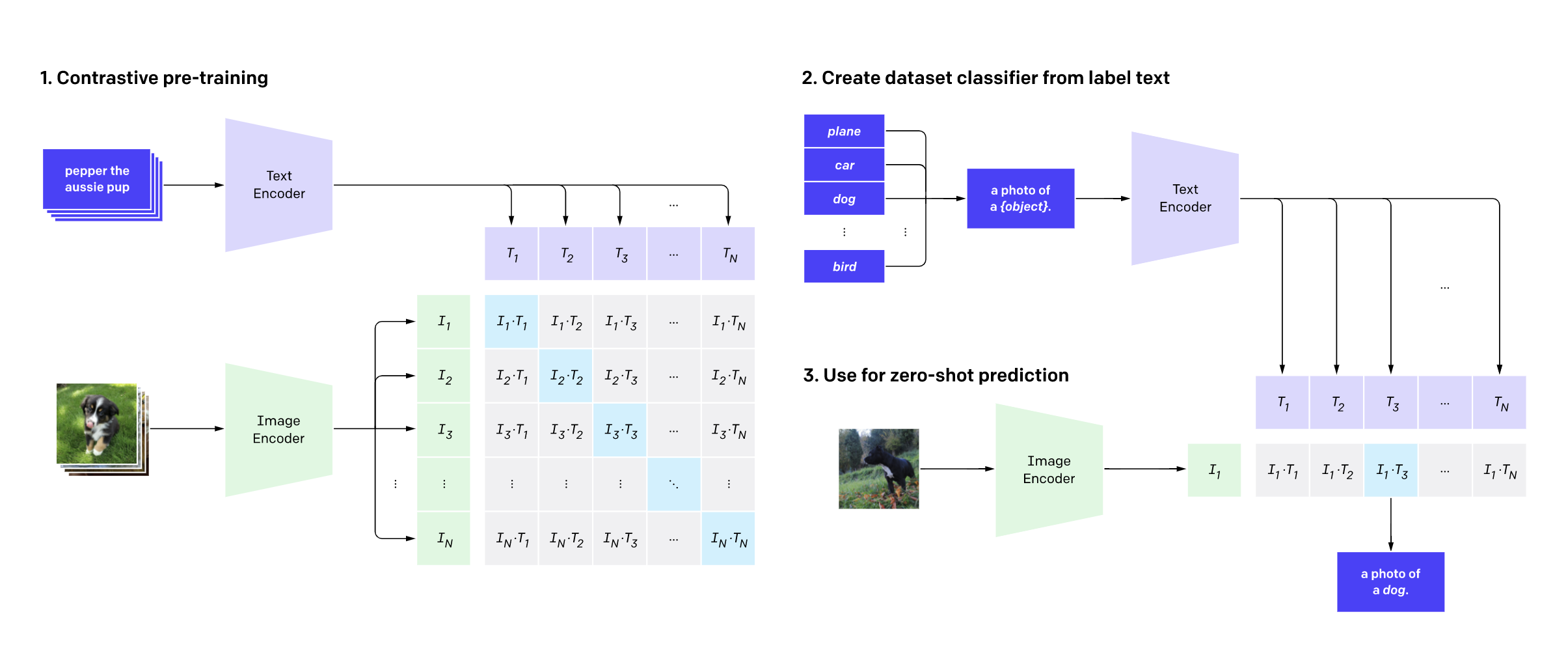
Our model is just the fine-tuned version of the unique CLIP model shown below. Inputs to the model are a batch of captions and a batch of images passed through the CLIP text encoder and image encoder respectively. The training process uses contrastive learning to learn a joint embedding representation of image and captions. On this embedding space, images and their respective captions are pushed close together, as are similar images and similar captions. Conversely, images and captions for various images, or dissimilar images and captions, are prone to be pushed further apart.
Data Augmentation
In an effort to regularize our dataset and stop overfitting resulting from the dimensions of the dataset, we used each image and text augmentation.
Image augmentation was done inline using built-in transforms from Pytorch’s Torchvision package. The transformations used were Random Cropping, Random Resizing and Cropping, Color Jitter, and Random Horizontal and Vertical flipping.
We augmented the text with backtranslation to generate captions for images with lower than 5 unique captions per image. The Marian MT family of models from Hugging Face was used to translate the prevailing captions into French, Spanish, Italian, and Portuguese and back to English to fill out the captions for these images.
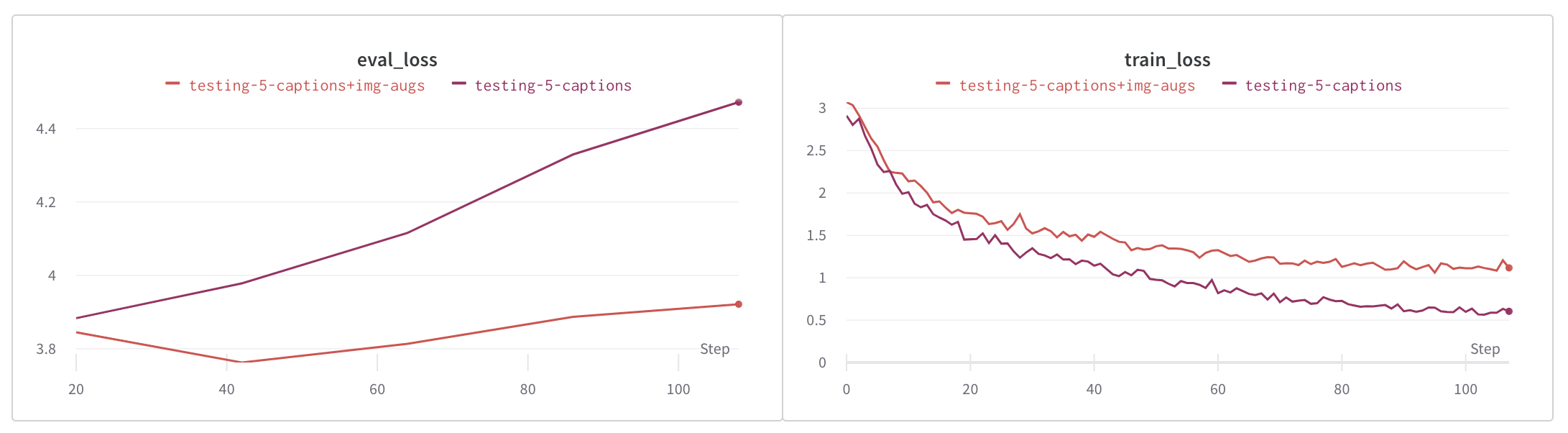
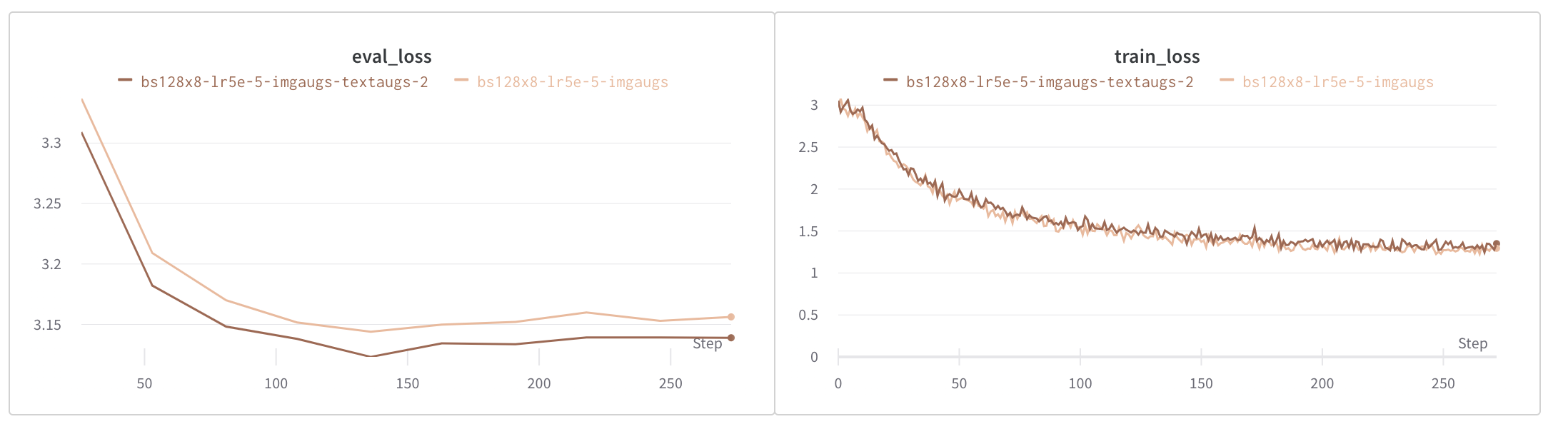
As shown in these loss plots below, image augmentation reduced overfitting significantly, and text and image augmentation reduced overfitting even further.
Evaluation
Metrics
A subset of the RSICD test set was used for evaluation. We found 30 categories of images on this subset. The evaluation was done by comparing each image with a set of 30 caption sentences of the shape "An aerial photograph of {category}". The model produced a ranked list of the 30 captions, from most relevant to least relevant. Categories corresponding to captions with the highest k scores (for k=1, 3, 5, and 10) were compared with the category provided via the image file name. The scores are averaged over the whole set of images used for evaluation and reported for various values of k, as shown below.
The baseline model represents the pre-trained openai/clip-vit-base-path32 CLIP model. This model was fine-tuned with captions and pictures from the RSICD dataset, which resulted in a big performance boost, as shown below.
Our greatest model was trained with image and text augmentation, with batch size 1024 (128 on each of the 8 TPU cores), and the Adam optimizer with learning rate 5e-6. We trained our second base model with the identical hyperparameters, except that we used the Adafactor optimizer with learning rate 1e-4. You possibly can download either model from their model repos linked to within the table below.
| Model-name | k=1 | k=3 | k=5 | k=10 |
|---|---|---|---|---|
| baseline | 0.572 | 0.745 | 0.837 | 0.939 |
| bs128x8-lr1e-4-augs/ckpt-2 | 0.819 | 0.950 | 0.974 | 0.994 |
| bs128x8-lr1e-4-imgaugs/ckpt-2 | 0.812 | 0.942 | 0.970 | 0.991 |
| bs128x8-lr1e-4-imgaugs-textaugs/ckpt-42 | 0.843 | 0.958 | 0.977 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs/ckpt-8 | 0.831 | 0.959 | 0.977 | 0.994 |
| bs128x8-lr5e-5-imgaugs/ckpt-4 | 0.746 | 0.906 | 0.956 | 0.989 |
| bs128x8-lr5e-5-imgaugs-textaugs-2/ckpt-4 | 0.811 | 0.945 | 0.972 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs-3/ckpt-5 | 0.823 | 0.946 | 0.971 | 0.992 |
| bs128x8-lr5e-5-wd02/ckpt-4 | 0.820 | 0.946 | 0.965 | 0.990 |
| bs128x8-lr5e-6-adam/ckpt-11 | 0.883 | 0.968 | 0.982 | 0.998 |
1 – our greatest model, 2 – our second best model
Demo
You possibly can access the CLIP-RSICD Demo here. It uses our fine-tuned CLIP model to supply the next functionality:
- Text to Image search
- Image to Image search
- Find text feature in image
The primary two functionalities use the RSICD test set as its image corpus. They’re encoded using our greatest fine-tuned CLIP model and stored in a NMSLib index which allows Approximate Nearest Neighbor based retrieval. For text-to-image and image-to-image search respectively, the query text or image are encoded with our model and matched against the image vectors within the corpus. For the third functionality, we divide the incoming image into patches and encode them, encode the queried text feature, match the text vector with each image patch vector, and return the probability of finding the feature in each patch.
Future Work
We’re grateful that we’ve been given a possibility to further refine our model. Some ideas we’ve for future work are as follows:
- Construct a sequence to sequence model using a CLIP encoder and a GPT-3 decoder and train it for image captioning.
- High quality-tune the model on more image caption pairs from other datasets and investigate if we are able to improve its performance.
- Investigate how fine-tuning affects the performance of model on non-RSICD image caption pairs.
- Investigate the aptitude of the fine-tuned model to categorise outside the categories it has been fine-tuned on.
- Evaluate the model using other criteria comparable to image classification.