

MTEB is a large benchmark for measuring the performance of text embedding models on diverse embedding tasks.
The 🥇 leaderboard provides a holistic view of one of the best text embedding models on the market on quite a lot of tasks.
The 📝 paper gives background on the tasks and datasets in MTEB and analyzes leaderboard results!
The 💻 Github repo incorporates the code for benchmarking and submitting any model of your alternative to the leaderboard.
Why Text Embeddings?
Text Embeddings are vector representations of text that encode semantic information. As machines require numerical inputs to perform computations, text embeddings are a vital component of many downstream NLP applications. For instance, Google uses text embeddings to power their search engine. Text Embeddings can be used for locating patterns in great amount of text via clustering or as inputs to text classification models, equivalent to in our recent SetFit work. The standard of text embeddings, nonetheless, is very depending on the embedding model used. MTEB is designed to make it easier to find one of the best embedding model on the market for quite a lot of tasks!
MTEB
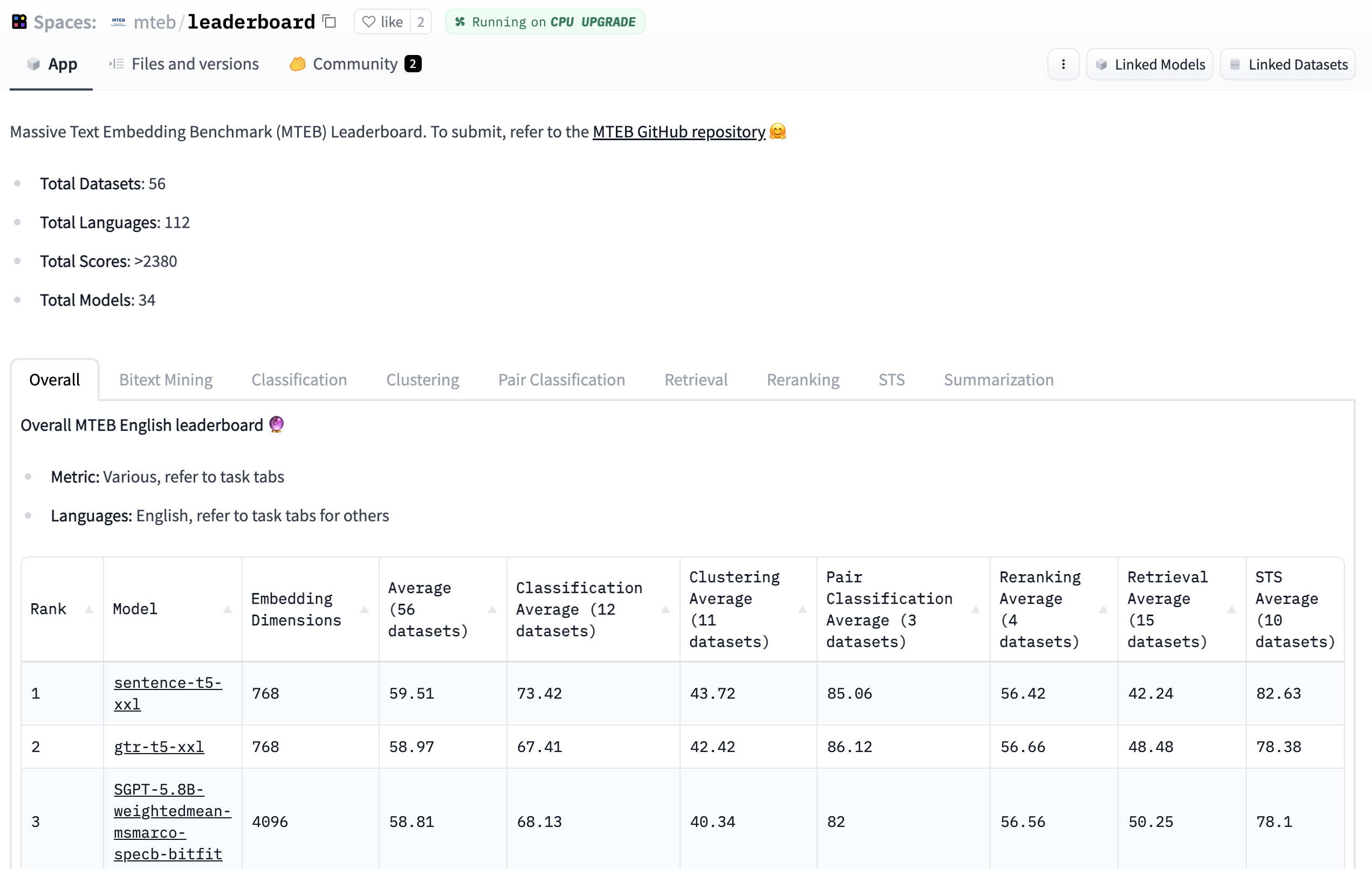
🐋 Massive: MTEB includes 56 datasets across 8 tasks and currently summarizes >2000 results on the leaderboard.
🌎 Multilingual: MTEB incorporates as much as 112 different languages! We’ve benchmarked several multilingual models on Bitext Mining, Classification, and STS.
🦚 Extensible: Be it latest tasks, datasets, metrics, or leaderboard additions, any contribution could be very welcome. Take a look at the GitHub repository to undergo the leaderboard or solve open issues. We hope you join us on the journey of finding one of the best text embedding model!
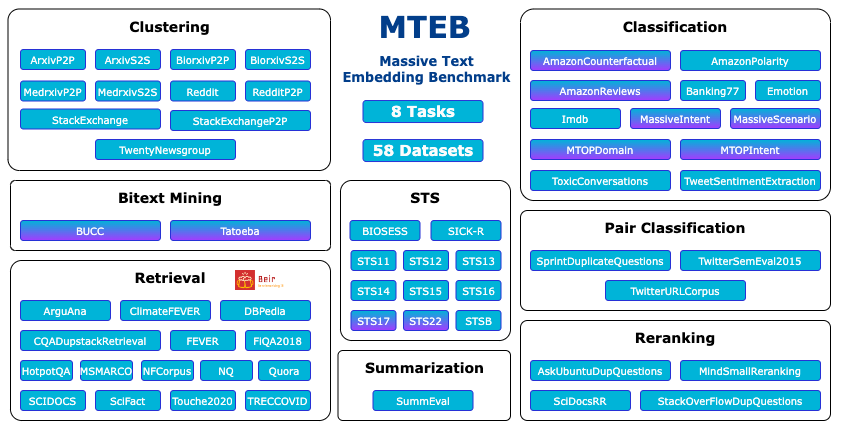
Overview of tasks and datasets in MTEB. Multilingual datasets are marked with a purple shade.
Models
For the initial benchmarking of MTEB, we focused on models claiming state-of-the-art results and popular models on the Hub. This led to a high representation of transformers. 🤖
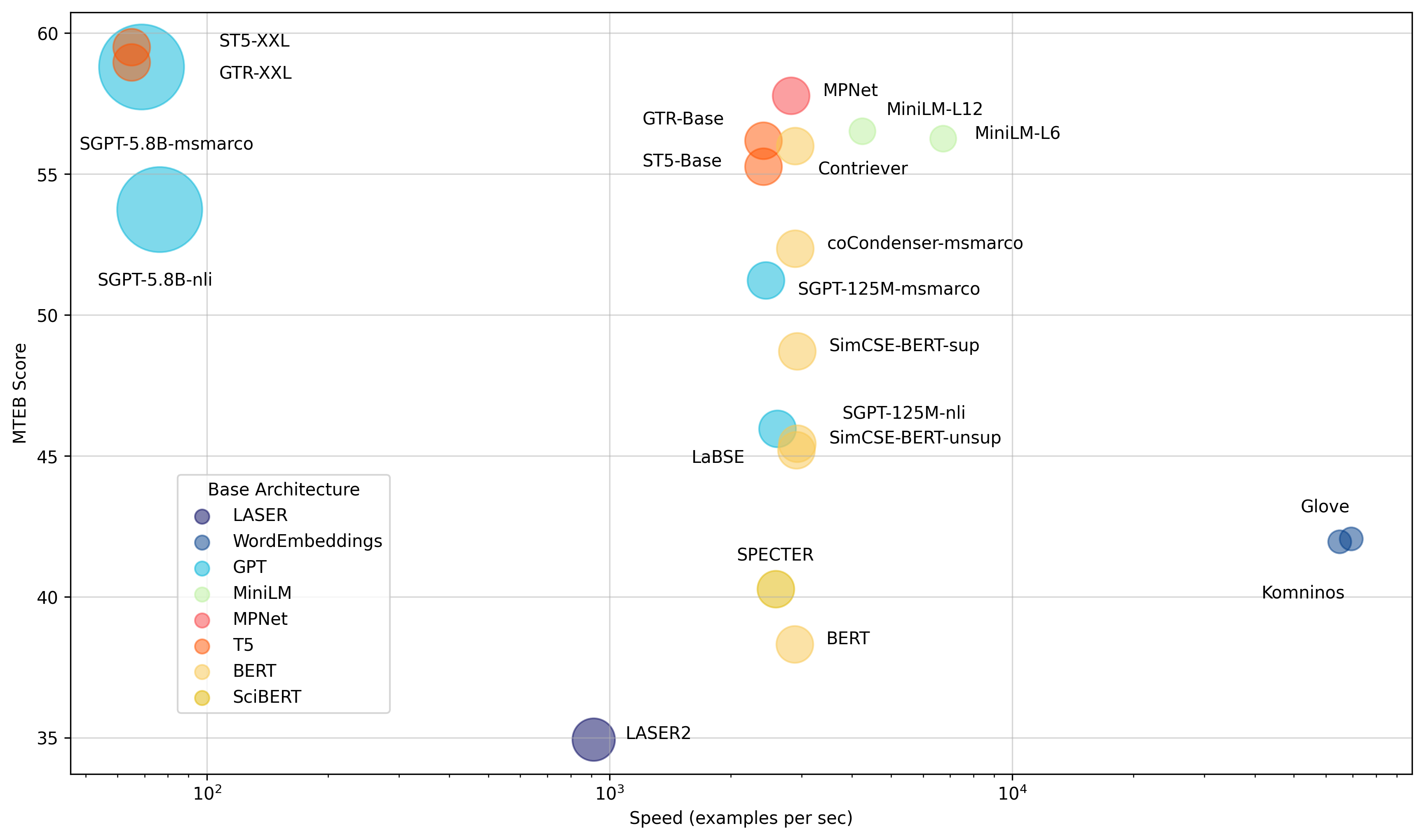
Models by average English MTEB rating (y) vs speed (x) vs embedding size (circle size).
We grouped models into the next three attributes to simplify finding one of the best model on your task:
🏎 Maximum speed Models like Glove offer high speed, but suffer from a scarcity of context awareness leading to low average MTEB scores.
⚖️ Speed and performance Barely slower, but significantly stronger, all-mpnet-base-v2 or all-MiniLM-L6-v2 provide a superb balance between speed and performance.
💪 Maximum performance Multi-billion parameter models like ST5-XXL, GTR-XXL or SGPT-5.8B-msmarco dominate on MTEB. They have a tendency to also produce greater embeddings like SGPT-5.8B-msmarco which produces 4096 dimensional embeddings requiring more storage!
Model performance varies lots depending on the duty and dataset, so we recommend checking the varied tabs of the leaderboard before deciding which model to make use of!
Benchmark your model
Using the MTEB library, you may benchmark any model that produces embeddings and add its results to the general public leaderboard. Let’s run through a fast example!
First, install the library:
pip install mteb
Next, benchmark a model on a dataset, for instance komninos word embeddings on Banking77.
from mteb import MTEB
from sentence_transformers import SentenceTransformer
model_name = "average_word_embeddings_komninos"
model = SentenceTransformer(model_name)
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(model, output_folder=f"results/{model_name}")
This could produce a results/average_word_embeddings_komninos/Banking77Classification.json file!
Now you may submit the outcomes to the leaderboard by adding it to the metadata of the README.md of any model on the Hub.
Run our automatic script to generate the metadata:
python mteb_meta.py results/average_word_embeddings_komninos
The script will produce a mteb_metadata.md file that appears like this:
“`sh
tags:
– mteb
model-index:
– name: average_word_embeddings_komninos
results:
– task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
– type: accuracy
value: 66.76623376623377
– type: f1
value: 66.59096432882667
Now add the metadata to the highest of a `README.md` of any model on the Hub, like this [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit/blob/essential/README.md) model, and it'll show up on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) after refreshing!
## Next steps
Go on the market and benchmark any model you want! Tell us if you've questions or feedback by opening a difficulty on our [GitHub repo](https://github.com/embeddings-benchmark/mteb) or the [leaderboard community tab](https://huggingface.co/spaces/mteb/leaderboard/discussions) 🤗
Blissful embedding!
## Credits
Huge due to the next who contributed to the article or to the MTEB codebase (listed in alphabetical order): Steven Liu, Loïc Magne, Nils Reimers and Nouamane Tazi.