
This guide introduces Mask2Former and OneFormer, 2 state-of-the-art neural networks for image segmentation. The models at the moment are available in 🤗 transformers, an open-source library that provides easy-to-use implementations of state-of-the-art models. Along the best way, you will learn in regards to the difference between the assorted types of image segmentation.
Image segmentation
Image segmentation is the duty of identifying different “segments” in a picture, like people or cars. More technically, image segmentation is the duty of grouping pixels with different semantics. Consult with the Hugging Face task page for a transient introduction.
Image segmentation can largely be split into 3 subtasks – instance, semantic and panoptic segmentation – with quite a few methods and model architectures to perform each subtask.
- instance segmentation is the duty of identifying different “instances”, like individual people, in a picture. Instance segmentation may be very just like object detection, except that we would prefer to output a set of binary segmentation masks, relatively than bounding boxes, with corresponding class labels. Instances are oftentimes also called “objects” or “things”. Note that individual instances may overlap.
- semantic segmentation is the duty of identifying different “semantic categories”, like “person” or “sky” of every pixel in a picture. Contrary to instance segmentation, no distinction is made between individual instances of a given semantic category; one just likes to give you a mask for the “person” category, relatively than for the person people for instance. Semantic categories which haven’t got individual instances, like “sky” or “grass”, are oftentimes known as “stuff”, to make the excellence with “things” (great names, huh?). Note that no overlap between semantic categories is feasible, as each pixel belongs to 1 category.
- panoptic segmentation, introduced in 2018 by Kirillov et al., goals to unify instance and semantic segmentation, by making models simply discover a set of “segments”, each with a corresponding binary mask and sophistication label. Segments could be each “things” or “stuff”. Unlike in instance segmentation, no overlap between different segments is feasible.
The figure below illustrates the difference between the three subtasks (taken from this blog post).

During the last years, researchers have give you several architectures that were typically very tailored to either instance, semantic or panoptic segmentation. Instance and panoptic segmentation were typically solved by outputting a set of binary masks + corresponding labels per object instance (very just like object detection, except that one outputs a binary mask as a substitute of a bounding box per instance). That is oftentimes called “binary mask classification”. Semantic segmentation alternatively was typically solved by making models output a single “segmentation map” with one label per pixel. Hence, semantic segmentation was treated as a “per-pixel classification” problem. Popular semantic segmentation models which adopt this paradigm are SegFormer, on which we wrote an in depth blog post, and UPerNet.
Universal image segmentation
Luckily, since around 2020, people began to give you models that may solve all 3 tasks (instance, semantic and panoptic segmentation) with a unified architecture, using the identical paradigm. This began with DETR, which was the primary model that solved panoptic segmentation using a “binary mask classification” paradigm, by treating “things” and “stuff” classes in a unified way. The important thing innovation was to have a Transformer decoder give you a set of binary masks + classes in a parallel way. This was then improved within the MaskFormer paper, which showed that the “binary mask classification” paradigm also works rather well for semantic segmentation.
Mask2Former extends this to instance segmentation by further improving the neural network architecture. Hence, we have evolved from separate architectures to what researchers now confer with as “universal image segmentation” architectures, able to solving any image segmentation task. Interestingly, these universal models all adopt the “mask classification” paradigm, discarding the “per-pixel classification” paradigm entirely. A figure illustrating Mask2Former’s architecture is depicted below (taken from the original paper).
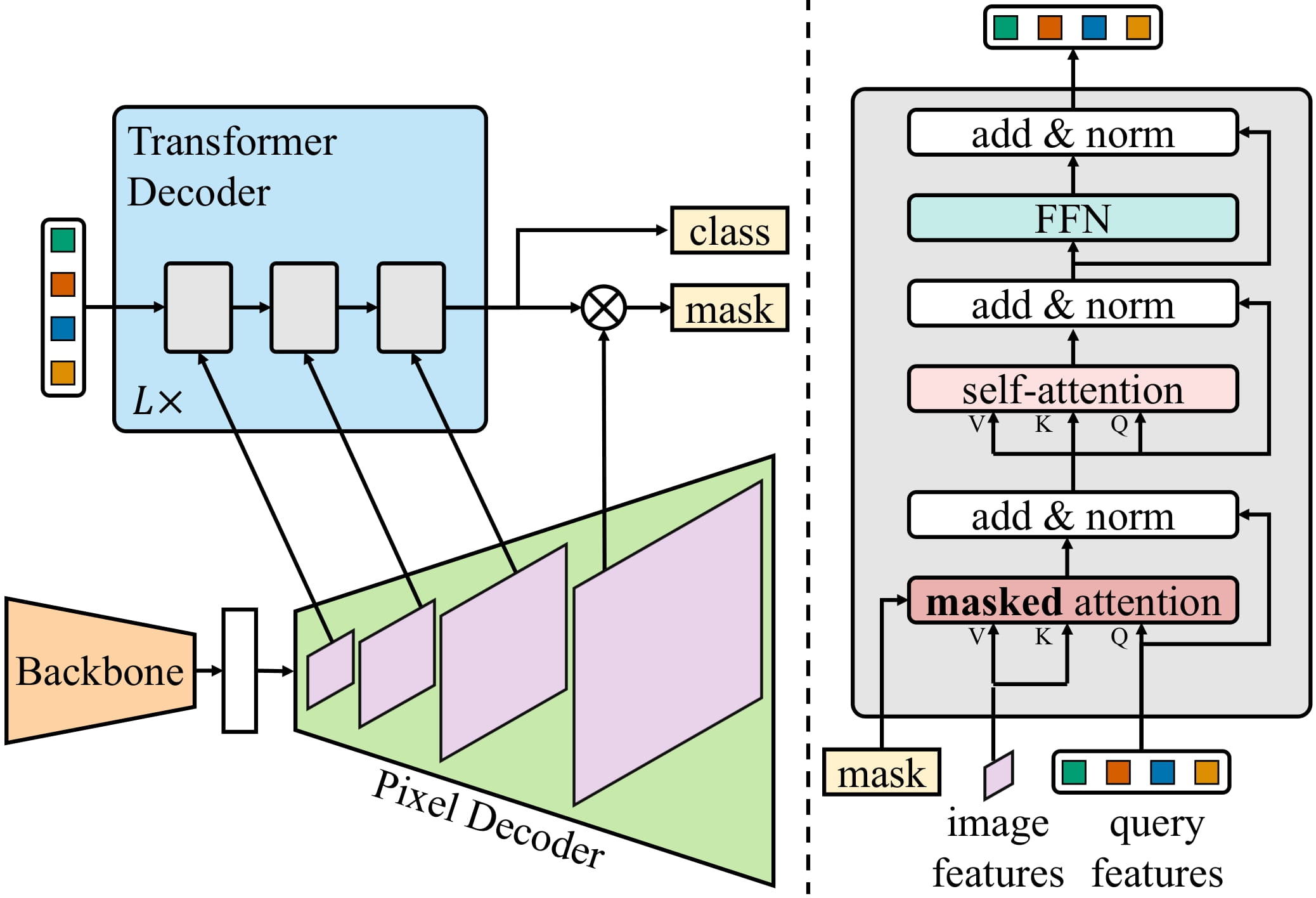
In brief, a picture is first sent through a backbone (which, within the paper could possibly be either ResNet or Swin Transformer) to get an inventory of low-resolution feature maps. Next, these feature maps are enhanced using a pixel decoder module to get high-resolution features. Finally, a Transformer decoder takes in a set of queries and transforms them right into a set of binary mask and sophistication predictions, conditioned on the pixel decoder’s features.
Note that Mask2Former still must be trained on each task individually to acquire state-of-the-art results. This has been improved by the OneFormer model, which obtains state-of-the-art performance on all 3 tasks by only training on a panoptic version of the dataset (!), by adding a text encoder to condition the model on either “instance”, “semantic” or “panoptic” inputs. This model can be as of today available in 🤗 transformers. It’s much more accurate than Mask2Former, but comes with greater latency because of the extra text encoder. See the figure below for an summary of OneFormer. It leverages either Swin Transformer or the brand new DiNAT model as backbone.

Inference with Mask2Former and OneFormer in Transformers
Usage of Mask2Former and OneFormer is pretty straightforward, and really just like their predecessor MaskFormer. Let’s instantiate a Mask2Former model from the hub trained on the COCO panoptic dataset, together with its processor. Note that the authors released at least 30 checkpoints trained on various datasets.
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
Next, let’s load the familiar cats image from the COCO dataset, on which we’ll perform inference.
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image

We prepare the image for the model using the image processor, and forward it through the model.
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
The model outputs a set of binary masks and corresponding class logits. The raw outputs of Mask2Former could be easily postprocessed using the image processor to get the ultimate instance, semantic or panoptic segmentation predictions:
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())
Output:
----------------------------------------------------------------------------------------------------
dict_keys(['segmentation', 'segments_info'])
In panoptic segmentation, the ultimate prediction incorporates 2 things: a segmentation map of shape (height, width) where each value encodes the instance ID of a given pixel, in addition to a corresponding segments_info. The segments_info incorporates more information in regards to the individual segments of the map (corresponding to their class / category ID). Note that Mask2Former outputs binary mask proposals of shape (96, 96) for efficiency and the target_sizes argument is used to resize the ultimate mask to the unique image size.
Let’s visualize the outcomes:
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# get the used color map
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# for every segment, draw its legend
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)
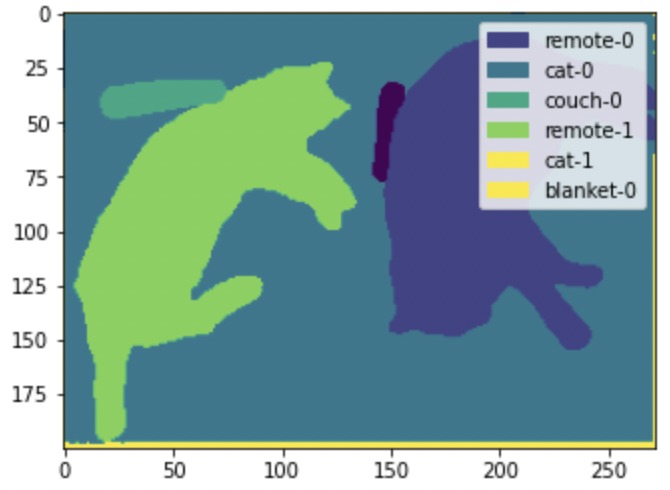
Here, we will see that the model is able to detecting the person cats and remotes within the image. Semantic segmentation alternatively would just create a single mask for the “cat” category.
To perform inference with OneFormer, which has the same API except that it also takes an extra text prompt as input, we confer with the demo notebook.
Wonderful-tuning Mask2Former and OneFormer in Transformers
For fine-tuning Mask2Former/OneFormer on a custom dataset for either instance, semantic and panoptic segmentation, take a look at our demo notebooks. MaskFormer, Mask2Former and OneFormer share the same API so upgrading from MaskFormer is simple and requires minimal changes.
The demo notebooks make use of MaskFormerForInstanceSegmentation to load the model whereas you’ll need to modify to using either Mask2FormerForUniversalSegmentation or OneFormerForUniversalSegmentation. In case of image processing for Mask2Former, you will even have to modify to using Mask2FormerImageProcessor. It’s also possible to load the image processor using the AutoImageProcessor class which routinely takes care of loading the proper processor corresponding to your model. OneFormer alternatively requires a OneFormerProcessor, which prepares the pictures, together with a text input, for the model.
Conclusion
That is it! You now know in regards to the difference between instance, semantic and panoptic segmentation, in addition to methods to use “universal architectures” corresponding to Mask2Former and OneFormer using the 🤗 transformers library.
We hope you enjoyed this post and learned something. Be at liberty to tell us whether you might be satisfied with the outcomes when fine-tuning Mask2Former or OneFormer.
Should you liked this topic and need to learn more, we recommend the next resources:
- Our demo notebooks for MaskFormer, Mask2Former and OneFormer, which give a broader overview on inference (including visualization) in addition to fine-tuning on custom data.
- The [live demo spaces] for Mask2Former and OneFormer available on the Hugging Face Hub which you should use to quickly check out the models on sample inputs of your selection.