




Recently, we introduced the newest generation of Intel Xeon CPUs (code name Sapphire Rapids), its recent hardware features for deep learning acceleration, and how you can use them to speed up distributed fine-tuning and inference for natural language processing Transformers.
On this post, we’re going to point out you different techniques to speed up Stable Diffusion models on Sapphire Rapids CPUs. A follow-up post will do the identical for distributed fine-tuning.
On the time of writing, the only technique to get your hands on a Sapphire Rapids server is to make use of the Amazon EC2 R7iz instance family. Because it’s still in preview, you could have to enroll to get access. Like in previous posts, I’m using an r7iz.metal-16xl instance (64 vCPU, 512GB RAM) with an Ubuntu 20.04 AMI (ami-07cd3e6c4915b2d18).
Let’s start! Code samples can be found on Gitlab.
The Diffusers library
The Diffusers library makes it very simple to generate images with Stable Diffusion models. In the event you’re not aware of these models, here’s an ideal illustrated introduction.
First, let’s create a virtual environment with the required libraries: Transformers, Diffusers, Speed up, and PyTorch.
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers speed up torch==1.13.1
Then, we write an easy benchmarking function that repeatedly runs inference, and returns the common latency for a single-image generation.
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
Now, let’s construct a StableDiffusionPipeline with the default float32 data type, and measure its inference latency.
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
The common latency is 32.3 seconds. As demonstrated by this Intel Space, the identical code runs on a previous generation Intel Xeon (code name Ice Lake) in about 45 seconds.
Out of the box, we will see that Sapphire Rapids CPUs are quite faster with none code change!
Now, let’s speed up!
Optimum Intel and OpenVINO
Optimum Intel accelerates end-to-end pipelines on Intel architectures. Its API is incredibly just like the vanilla Diffusers API, making it trivial to adapt existing code.
Optimum Intel supports OpenVINO, an Intel open-source toolkit for high-performance inference.
Optimum Intel and OpenVINO will be installed as follows:
pip install optimum[openvino]
Ranging from the code above, we only need to exchange StableDiffusionPipeline with OVStableDiffusionPipeline. To load a PyTorch model and convert it to the OpenVINO format on-the-fly, you’ll be able to set export=True when loading your model.
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
ov_pipe.save_pretrained("./openvino")
OpenVINO routinely optimizes the model for the bfloat16 format. Because of this, the common latency is now 16.7 seconds, a sweet 2x speedup.
The pipeline above support dynamic input shapes, with no restriction on the variety of images or their resolution. With Stable Diffusion, your application is often restricted to at least one (or a couple of) different output resolutions, reminiscent of 512×512, or 256×256. Thus, it makes lots of sense to unlock significant acceleration by reshaping the pipeline to a hard and fast resolution. In the event you need multiple output resolution, you’ll be able to simply maintain a couple of pipeline instances, one for every resolution.
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
With a static shape, average latency is slashed to 4.7 seconds, an extra 3.5x speedup.
As you’ll be able to see, OpenVINO is an easy and efficient technique to speed up Stable Diffusion inference. When combined with a Sapphire Rapids CPU, it delivers almost 10x speedup in comparison with vanilla inference on Ice Lake Xeons.
In the event you cannot or don’t desire to make use of OpenVINO, the remainder of this post will show you a series of other optimization techniques. Fasten your seatbelt!
System-level optimization
Diffuser models are large multi-gigabyte models, and image generation is a memory-intensive operation. By installing a high-performance memory allocation library, we should always give you the chance to hurry up memory operations and parallelize them across the Xeon cores. Please note that it will change the default memory allocation library in your system. In fact, you’ll be able to return to the default library by uninstalling the brand new one.
jemalloc and tcmalloc are equally interesting. Here, I’m installing jemalloc as my tests give it a slight performance edge. It could actually even be tweaked for a specific workload, for instance to maximise CPU utilization. You’ll be able to consult with the tuning guide for details.
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
Next, we install the libiomp library to optimize parallel processing. It’s a part of Intel OpenMP* Runtime.
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
Finally, we install the numactl command line tool. This lets us pin our Python process to specific cores, and avoid a number of the overhead related to context switching.
numactl -C 0-31 python sd_blog_1.py
Because of these optimizations, our original Diffusers code now predicts in 11.8 seconds. That is almost 3x faster, with none code change. These tools are definitely working great on our 32-core Xeon.
We’re removed from done. Let’s add the Intel Extension for PyTorch to the combo.
IPEX and BF16
The Intel Extension for Pytorch (IPEX) extends PyTorch and takes advantage of hardware acceleration features present on Intel CPUs, reminiscent of AVX-512 Vector Neural Network Instructions (AVX512 VNNI) and Advanced Matrix Extensions (AMX).
Let’s install it.
pip install intel_extension_for_pytorch==1.13.100
We then update our code to optimize each pipeline element with IPEX (you’ll be able to list them by printing the pipe object). This requires converting them to the channels-last format.
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
We also enable the bloat16 data format to leverage the AMX tile matrix multiply unit (TMMU) accelerator present on Sapphire Rapids CPUs.
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
With this updated version, inference latency is further reduced from 11.9 seconds to 5.4 seconds. That is greater than 2x acceleration due to IPEX and AMX.
Can we extract a bit more performance? Yes, with schedulers!
Schedulers
The Diffusers library lets us attach a scheduler to a Stable Diffusion pipeline. Schedulers try to search out one of the best trade-off between denoising speed and denoising quality.
In line with the documentation: “On the time of writing this doc DPMSolverMultistepScheduler gives arguably one of the best speed/quality trade-off and will be run with as little as 20 steps.“
Let’s try it.
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
With this final version, inference latency is now all the way down to 5.05 seconds. In comparison with our initial Sapphire Rapids baseline (32.3 seconds), this is sort of 6.5x faster!
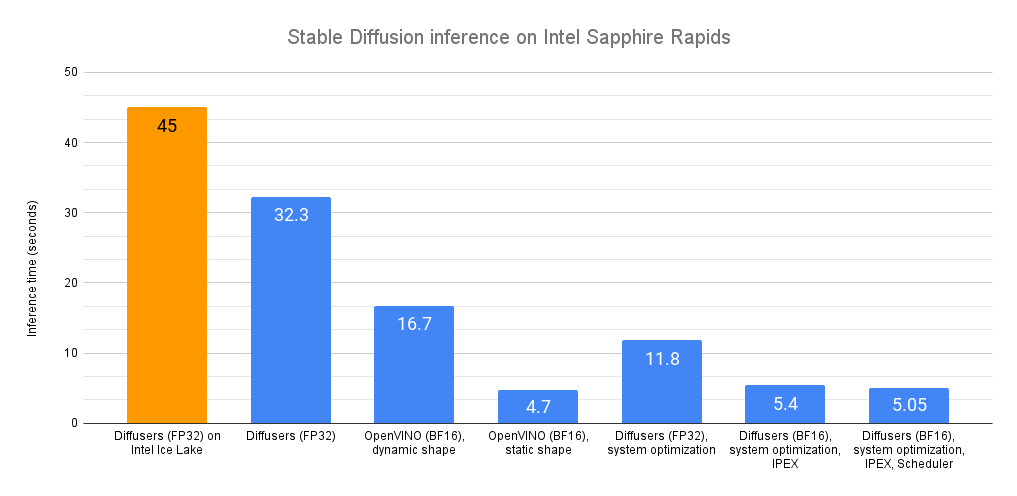
*Environment: Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, speed up 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7*
Conclusion
The flexibility to generate high-quality images in seconds should work well for lots of use cases, reminiscent of customer apps, content generation for marketing and media, or synthetic data for dataset augmentation.
Listed here are some resources to provide help to start:
If you could have questions or feedback, we might like to read them on the Hugging Face forum.
Thanks for reading!