



In recent times, the AI community has witnessed a remarkable surge in the event of larger and more performant language models, corresponding to Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, and within the imaging domain with models like SD2.1 and SDXL. These advancements have undoubtedly pushed the boundaries of what AI can achieve, enabling highly versatile and state-of-the-art image generation and language understanding capabilities. Nonetheless, as we marvel at the ability and complexity of those models, it is crucial to acknowledge a growing have to make AI models smaller, efficient, and more accessible, particularly by open-sourcing them.
At Segmind, now we have been working on find out how to make generative AI models faster and cheaper. Last yr, now we have open-sourced our accelerated SD-WebUI library called voltaML, which is a AITemplate/TensorRT based inference acceleration library that has delivered between 4-6X increase within the inference speed. To proceed towards the goal of constructing generative models faster, smaller and cheaper, we’re open-sourcing the weights and training code of our compressed SD models; SD-Small and SD-Tiny. The pretrained checkpoints can be found on Huggingface 🤗
Knowledge Distillation

Our recent compressed models have been trained on Knowledge-Distillation (KD) techniques and the work has been largely based on this paper. The authors describe a Block-removal Knowledge-Distillation method where a number of the UNet layers are removed and the coed model weights are trained. Using the KD methods described within the paper, we were in a position to train two compressed models using the 🧨 diffusers library; Small and Tiny, which have 35% and 55% fewer parameters, respectively than the bottom model while achieving comparable image fidelity as the bottom model. We’ve got open-sourced our distillation code on this repo and pretrained checkpoints on Huggingface 🤗.
Knowledge-Distillation training a neural network is analogous to a teacher guiding a student step-by-step. A big teacher model is pre-trained on a considerable amount of data after which a smaller model is trained on a smaller dataset, to mimic the outputs of the larger model together with classical training on the dataset.
On this particular style of knowledge distillation, the coed model is trained to do the traditional diffusion task of recovering a picture from pure noise, but at the identical time, the model is made to match the output of the larger teacher model. The matching of outputs happens at every block of the U-nets, hence the model quality is usually preserved. So, using the previous analogy, we are able to say that in this type of distillation, the coed won’t only attempt to learn from the Questions and Answers but in addition from the Teacher’s answers, in addition to the step-by-step approach to attending to the reply. We’ve got 3 components within the loss function to realize this, firstly the standard loss between latents of the goal image and latents of the generated image. Secondly, the loss between latents of the image generated by the teacher and latents of image generated by the coed. And lastly, and crucial component, is the feature level loss, which is the loss between the outputs of every of the blocks of the teacher and the coed.
Combining all of this makes up the Knowledge-Distillation training. Below is an architecture of the Block Removed UNet utilized in the KD as described within the paper.
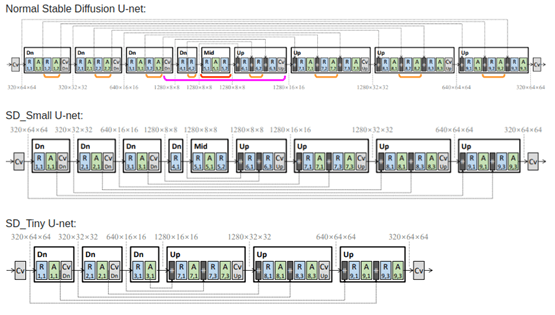
Image taken from the paper “On Architectural Compression of Text-to-Image Diffusion Models” by Shinkook. et. al
We’ve got taken Realistic-Vision 4.0 as our base teacher model and have trained on the LAION Art Aesthetic dataset with image scores above 7.5, due to their top quality image descriptions. Unlike the paper, now we have chosen to coach the 2 models on 1M images for 100K steps for the Small and 125K steps for the Tiny mode respectively. The code for the distillation training might be found here.
Model Usage
The Model might be used using the DiffusionPipeline from 🧨 diffusers
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a reasonably girl"
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")
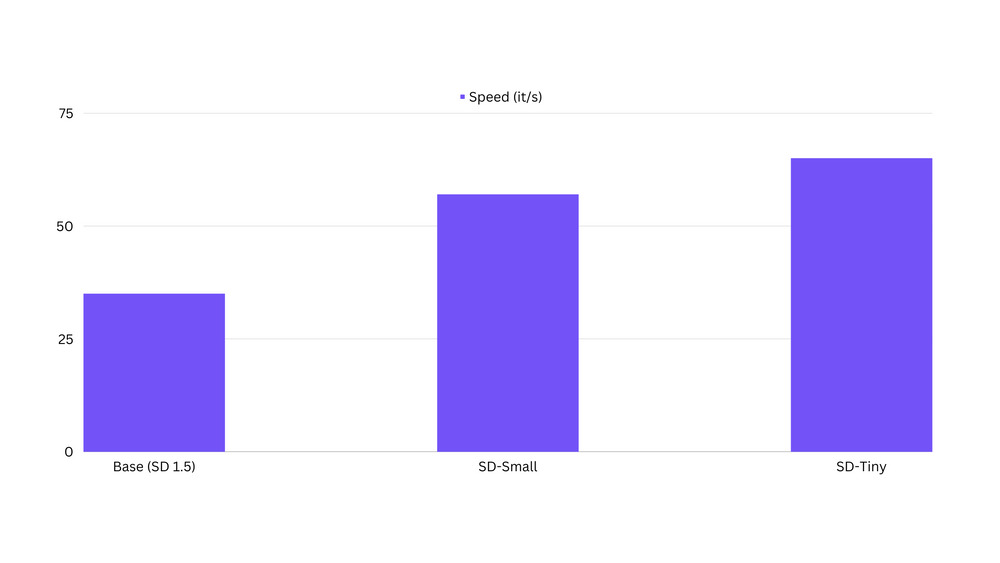
Speed by way of inference latency
We’ve got observed that distilled models are as much as 100% faster than the unique base models. The Benchmarking code might be found here.
Potential Limitations
The distilled models are in early phase and the outputs might not be at a production quality yet.
These models might not be the very best general models. They’re best used as fine-tuned or LoRA trained on specific concepts/styles.
Distilled models aren’t superb at composibility or multiconcepts yet.
Advantageous-tuning SD-tiny model on portrait dataset
We’ve got fine-tuned our sd-tiny model on portrait images generated with the Realistic Vision v4.0 model. Below are the wonderful tuning parameters used.
- Steps: 131000
- Learning rate: 1e-4
- Batch size: 32
- Gradient accumulation steps: 4
- Image resolution: 768
- Dataset size – 7k images
- Mixed-precision: fp16
We were in a position to produce image quality near the pictures produced by the unique model, with almost 40% fewer parameters and the sample results below speak for themselves:

The code for fine-tuning the bottom models might be found here.
LoRA Training
Considered one of the benefits of LoRA training on a distilled model is quicker training. Below are a number of the images of the primary LoRA we trained on the distilled model on some abstract concepts. The code for the LoRA training might be found here.

Conclusion
We invite the open-source community to assist us improve and achieve wider adoption of those distilled SD models. Users can join our Discord server, where we will probably be announcing the newest updates to those models, releasing more checkpoints and a few exciting recent LoRAs. And when you like our work, please give us a star on our Github.