

I even have a number of respect for iOS/Mac developers. I began writing apps for iPhones in 2007, when not even APIs or documentation existed. The brand new devices adopted some unfamiliar decisions within the constraint space, with a mix of power, screen real estate, UI idioms, network access, persistence, and latency that was different to what we were used to before. Yet, this community soon managed to create top-notch applications that felt at home with the brand new paradigm.
I imagine that ML is a brand new option to construct software, and I do know that many Swift developers want to include AI features of their apps. The ML ecosystem has matured so much, with 1000’s of models that solve a wide range of problems. Furthermore, LLMs have recently emerged as almost general-purpose tools – they might be adapted to latest domains so long as we will model our task to work on text or text-like data. We’re witnessing a defining moment in computing history, where LLMs are going out of research labs and becoming computing tools for everyone.
Nonetheless, using an LLM model equivalent to Llama in an app involves several tasks which many individuals face and solve alone. Now we have been exploring this space and would like to proceed working on it with the community. We aim to create a set of tools and constructing blocks that help developers construct faster.
Today, we’re publishing this guide to undergo the steps required to run a model equivalent to Llama 2 in your Mac using Core ML. We’re also releasing alpha libraries and tools to support developers within the journey. We’re calling all Swift developers keen on ML – is that all Swift developers? – to contribute with PRs, bug reports, or opinions to enhance this together.
Let’s go!
Released Today
swift-transformers, an in-development Swift package to implement a transformers-like API in Swift focused on text generation. It’s an evolution ofswift-coreml-transformerswith broader goals: Hub integration, arbitrary tokenizer support, and pluggable models.swift-chat, a straightforward app demonstrating tips on how to use the package.- An updated version of
exporters, a Core ML conversion package for transformers models. - An updated version of
transformers-to-coreml, a no-code Core ML conversion tool built onexporters. - Some converted models, equivalent to Llama 2 7B or Falcon 7B, ready to be used with these text generation tools.
Tasks Overview
After I published tweets showing Falcon or Llama 2 running on my Mac, I got many questions from other developers asking tips on how to convert those models to Core ML, because they wish to use them of their apps as well. Conversion is an important step, nevertheless it’s just the primary piece of the puzzle. The true reason I write those apps is to face the identical problems that another developer would and discover areas where we may help. We’ll undergo a few of these tasks in the remaining of this post, explaining where (and where not) we’ve tools to assist.
- Conversion to Core ML. We’ll use Llama 2 as a real-life example.
- Optimization techniques to make your model (and app) run fast and eat as little memory as possible. That is an area that permeates across the project and there is not any silver-bullet solution you possibly can apply.
swift-transformers, our latest library to assist with some common tasks.- Tokenizers. Tokenization is the option to convert text input to the actual set of numbers which might be processed by the model (and back to text from the generated predictions). That is so much more involved than it sounds, as there are numerous different options and techniques.
- Model and Hub wrappers. If we would like to support the wide range of models on the Hub, we won’t afford to hardcode model settings. We created a straightforward
LanguageModelabstraction and various utilities to download model and tokenizer configuration files from the Hub. - Generation Algorithms. Language models are trained to predict a probability distribution for the subsequent token which will appear after a sequence of text. We want to call the model multiple times to generate text output and choose a token at each step. There are numerous ways to determine which token we must always select next.
- Supported Models. Not all model families are supported (yet).
swift-chat. It is a small app that simply shows tips on how to useswift-transformersin a project.- Missing Parts / Coming Next. Some stuff that is vital but not yet available, as directions for future work.
- Resources. Links to all of the projects and tools.
Conversion to Core ML
Core ML is Apple’s native framework for Machine Learning, and likewise the name of the file format it uses. After you exchange a model from (for instance) PyTorch to Core ML, you need to use it in your Swift apps. The Core ML framework mechanically selects one of the best hardware to run your model on: the CPU, the GPU, or a specialized tensor unit called the Neural Engine. A mixture of several of those compute units can be possible, depending on the characteristics of your system and the model details.
To see what it looks prefer to convert a model in real life, we’ll take a look at converting the recently-released Llama 2 model. The method can sometimes be convoluted, but we provide some tools to assist. These tools won’t all the time work, as latest models are being introduced on a regular basis, and we’d like to make adjustments and modifications.
Our advisable approach is:
- Use the
transformers-to-coremlconversion Space:
That is an automatic tool built on top of exporters (see below) that either works in your model, or doesn’t. It requires no coding: enter the Hub model identifier, select the duty you propose to make use of the model for, and click on apply. If the conversion succeeds, you possibly can push the converted Core ML weights to the Hub, and you’re done!
You possibly can visit the Space or use it directly here:
- Use
exporters, a Python conversion package built on top of Apple’scoremltools(see below).
This library gives you so much more options to configure the conversion task. As well as, it enables you to create your individual conversion configuration class, which it’s possible you’ll use for added control or to work around conversion issues.
- Use
coremltools, Apple’s conversion package.
That is the lowest-level approach and due to this fact provides maximum control. It will probably still fail for some models (especially latest ones), but you usually have the choice to dive contained in the source code and check out to work out why.
The excellent news about Llama 2 is that we did the legwork and the conversion process works using any of those methods. The bad news is that it did not convert when it was released, and we needed to do some fixing to support it. We briefly take a look at what happened in the appendix so you possibly can get a taste of what to do when things go incorrect.
Vital lessons learned
I’ve followed the conversion process for some recent models (Llama 2, Falcon, StarCoder), and I’ve applied what I learned to each exporters and the transformers-to-coreml Space. It is a summary of some takeaways:
- If you’ve to make use of
coremltools, use the newest version:7.0b1. Despite technically being a beta, I have been using it for weeks and it’s really good: stable, includes a number of fixes, supports PyTorch 2, and has latest features like advanced quantization tools. exportersnot applies a softmax to outputs when converting text generation tasks. We realized this was vital for some generation algorithms.exportersnow defaults to using fixed sequence lengths for text models. Core ML has a option to specify “flexible shapes”, such that your input sequence can have any length between 1 and, say, 4096 tokens. We discovered that flexible inputs only run on CPU, but not on GPU or the Neural Engine. More investigation coming soon!
We’ll keep adding best practices to our tools so that you haven’t got to find the identical issues again.
Optimization
There is no point in converting models in the event that they don’t run fast in your goal hardware and respect system resources. The models mentioned on this post are pretty big for local use, and we’re consciously using them to stretch the boundaries of what is possible with current technology and understand where the bottlenecks are.
There are a number of key optimization areas we have identified. They’re an important topic for us and the topic of current and upcoming work. A few of them include:
- Cache attention keys and values from previous generations, similar to the transformers models do within the PyTorch implementation. The computation of attention scores must run on the entire sequence generated up to now, but all of the past key-value pairs were already computed in previous runs. We’re currently not using any caching mechanism for Core ML models, but are planning to achieve this!
- Use discrete shapes as a substitute of a small fixed sequence length. The major reason not to make use of flexible shapes is that they should not compatible with the GPU or the Neural Engine. A secondary reason is that generation would develop into slower because the sequence length grows, due to absence of caching as mentioned above. Using a discrete set of fixed shapes, coupled with caching key-value pairs should allow for larger context sizes and a more natural chat experience.
- Quantization techniques. We have already explored them within the context of Stable Diffusion models, and are really excited concerning the options they’d bring. For instance, 6-bit palettization decreases model size and is efficient with resources. Mixed-bit quantization, a brand new technique, can achieve 4-bit quantization (on average) with low impact on model quality. We’re planning to work on these topics for language models too!
For production applications, consider iterating with smaller models, especially during development, after which apply optimization techniques to pick the smallest model you possibly can afford in your use case.
swift-transformers
swift-transformers is an in-progress Swift package that goals to supply a transformers-like API to Swift developers. Let’s have a look at what it has and what’s missing.
Tokenizers
Tokenization solves two complementary tasks: adapt text input to the tensor format utilized by the model and convert results from the model back to text. The method is nuanced, for instance:
- Can we use words, characters, groups of characters or bytes?
- How should we cope with lowercase vs uppercase letters? Should we even cope with the difference?
- Should we remove repeated characters, equivalent to spaces, or are they vital?
- How will we cope with words that should not within the model’s vocabulary?
There are a number of general tokenization algorithms, and a number of different normalization and pre-processing steps which might be crucial to using the model effectively. The transformers library made the choice to abstract all those operations in the identical library (tokenizers), and represent the selections as configuration files which might be stored within the Hub alongside the model. For instance, that is an excerpt from the configuration of the Llama 2 tokenizer that describes just the normalization step:
"normalizer": {
"type": "Sequence",
"normalizers": [
{
"type": "Prepend",
"prepend": "▁"
},
{
"type": "Replace",
"pattern": {
"String": " "
},
"content": "▁"
}
]
},
It reads like this: normalization is a sequence of operations applied so as. First, we Prepend character _ to the input string. Then we replace all spaces with _. There is a huge list of potential operations, they might be applied to regular expression matches, and so they must be performed in a really specific order. The code within the tokenizers library takes care of all these details for all of the models within the Hub.
In contrast, projects that use language models in other domains, equivalent to Swift apps, often resort to hardcoding these decisions as a part of the app’s source code. That is high quality for a few models, but then it’s difficult to switch a model with a unique one, and it is easy to make mistakes.
What we’re doing in swift-transformers is replicate those abstractions in Swift, so we write them once and everybody can use them of their apps. We are only getting began, so coverage remains to be small. Be happy to open issues within the repo or contribute your individual!
Specifically, we currently support BPE (Byte-Pair Encoding) tokenizers, considered one of the three major families in use today. The GPT models, Falcon and Llama, all use this method. Support for Unigram and WordPiece tokenizers will come later. We’ve not ported all of the possible normalizers, pre-tokenizers and post-processors – just those we encountered during our conversions of Llama 2, Falcon and GPT models.
That is tips on how to use the Tokenizers module in Swift:
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}
Nonetheless, you do not often have to tokenize the input text yourself – the Generation code will maintain it.
Model and Hub wrappers
As explained above, transformers heavily use configuration files stored within the Hub. We prepared a straightforward Hub module to download configuration files from the Hub, which is used to instantiate the tokenizer and retrieve metadata concerning the model.
Regarding models, we created a straightforward LanguageModel type as a wrapper for a Core ML model, specializing in the text generation task. Using protocols, we will query any model with the identical API.
To retrieve the suitable metadata for the model you utilize, swift-transformers relies on a number of custom metadata fields that have to be added to the Core ML file when converting it. swift-transformers will use this information to download all of the vital configuration files from the Hub. These are the fields we use, as presented in Xcode’s model preview:

exporters and transformers-to-coreml will mechanically add these fields for you. Please, be certain you add them yourself when you use coremltools manually.
Generation Algorithms
Language models are trained to predict a probability distribution of the subsequent token which will appear as a continuation to an input sequence. With a view to compose a response, we’d like to call the model multiple times until it produces a special termination token, or we reach the length we desire. There are numerous ways to determine what’s the subsequent best token to make use of. We currently support two of them:
- Greedy decoding. That is the plain algorithm: select the token with the best probability, append it to the sequence, and repeat. This can all the time produce the identical result for a similar input sequence.
- top-k sampling. Select the
top-k(wherekis a parameter) most probable tokens, after which randomly sample from them using parameters equivalent totemperature, which can increase variability on the expense of doubtless causing the model to go on tangents and lose track of the content.
Additional methods equivalent to “nucleus sampling” will come later. We recommend this blog post (updated recently) for a wonderful overview of generation methods and the way they work. Sophisticated methods equivalent to assisted generation will also be very useful for optimization!
Supported Models
Thus far, we have tested swift-transformers with a handful of models to validate the major design decisions. We’re looking forward to trying many more!
- Llama 2.
- Falcon.
- StarCoder models, based on a variant of the GPT architecture.
- GPT family, including GPT2, distilgpt, GPT-NeoX, GPT-J.
swift-chat
swift-chat is a straightforward demo app built on swift-transformers. Its major purpose is to point out tips on how to use swift-transformers in your code, but it might probably even be used as a model tester tool.
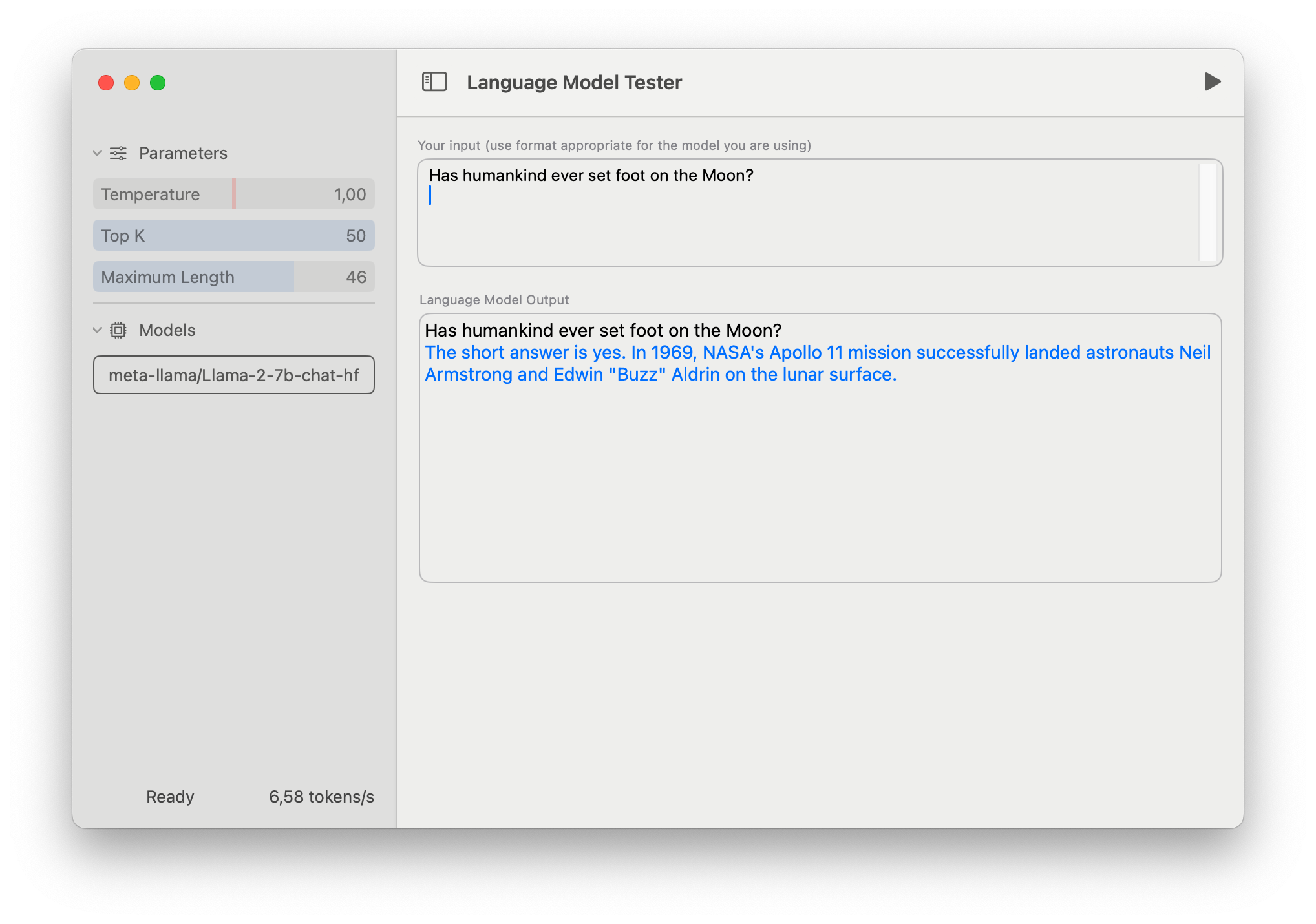
To make use of it, download a Core ML model from the Hub or create your individual, and choose it from the UI. All of the relevant model configuration files shall be downloaded from the Hub, using the metadata information to discover what model type that is.
The primary time you load a brand new model, it should take a while to organize it. On this phase, the CoreML framework will compile the model and choose what compute devices to run it on, based in your machine specs and the model’s structure. This information is cached and reused in future runs.
The app is intentionally easy to make it readable and concise. It also lacks a number of features, primarily due to current limitations in model context size. For instance, it doesn’t have any provision for “system prompts”, that are useful for specifying the behaviour of your language model and even its personality.
Missing Parts / Coming Next
As stated, we are only getting began! Our upcoming priorities include:
- Encoder-decoder models equivalent to T5 and Flan.
- More tokenizers: support for Unigram and WordPiece.
- Additional generation algorithms.
- Support key-value caching for optimization.
- Use discrete sequence shapes for conversion. Along with key-value caching it will allow for larger contexts.
Tell us what you think that we must always work on next, or head over to the repos for Good First Issues to try your hand on!
Conclusion
We introduced a set of tools to assist Swift developers incorporate language models of their apps. I am unable to wait to see what you create with them, and I look ahead to improving them with the community’s help! Don’t hesitate to get in contact 🙂
Appendix: Converting Llama 2 the Hard Way
You possibly can safely ignore this section unless you have experienced Core ML conversion issues and are able to fight 🙂
In my experience, there are two frequent the reason why PyTorch models fail to convert to Core ML using coremltools:
- Unsupported PyTorch operations or operation variants
PyTorch has so much of operations, and all of them must be mapped to an intermediate representation (MIL, for Model Intermediate Language), which in turn is converted to native Core ML instructions. The set of PyTorch operations is just not static, so latest ones must be added to coremltools too. As well as, some operations are really complex and might work on exotic combos of their arguments. An example of a recently-added, very complex op, was scaled dot-product attention, introduced in PyTorch 2. An example of a partially supported op is einsum: not all possible equations are translated to MIL.
- Edge cases and kind mismatches
Even for supported PyTorch operations, it’s totally difficult to be sure that the interpretation process works on all possible inputs across all the several input types. Be mindful that a single PyTorch op can have multiple backend implementations for various devices (cpu, CUDA), input types (integer, float), or precision (float16, float32). The product of all combos is staggering, and sometimes the way in which a model uses PyTorch code triggers a translation path which will haven’t been considered or tested.
That is what happened once I first tried to convert Llama 2 using coremltools:
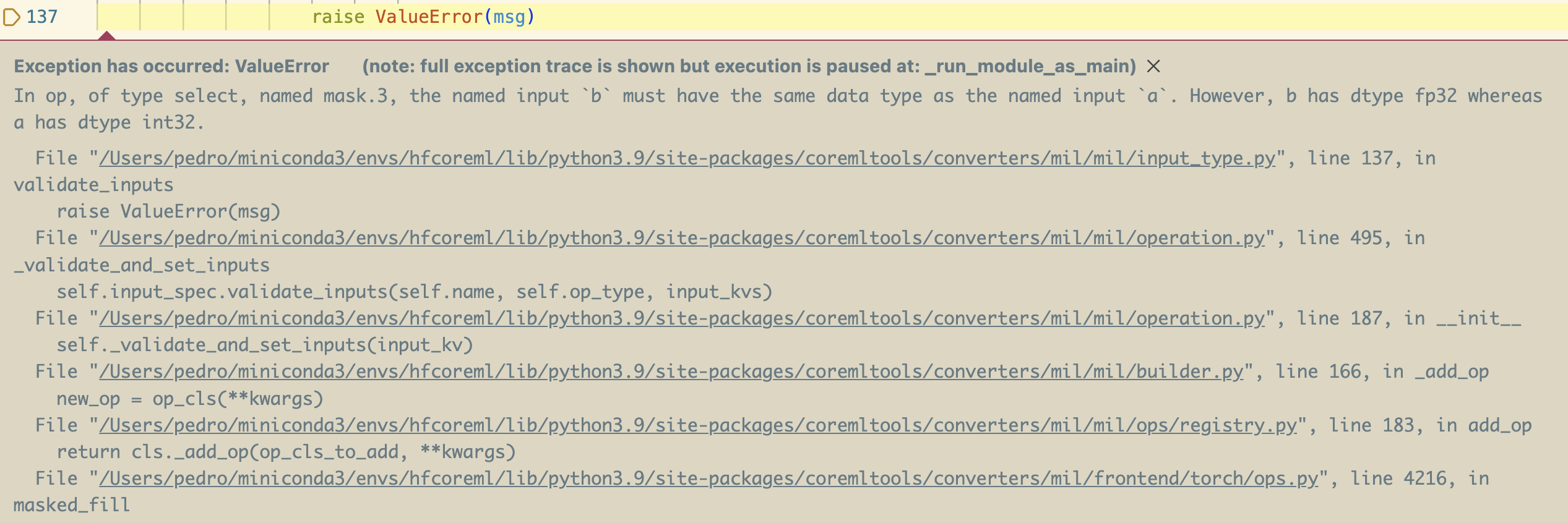
By comparing different versions of transformers, I could see the issue began happening when this line of code was introduced. It’s a part of a recent transformers refactor to higher cope with causal masks in all models that use them, so this might be an enormous problem for other models, not only Llama.
What the error screenshot is telling us is that there is a type mismatch attempting to fill the mask tensor. It comes from the 0 within the line: it’s interpreted as an int, however the tensor to be filled accommodates floats, and using differing kinds was rejected by the interpretation process. On this particular case, I got here up with a patch for coremltools, but fortunately this isn’t vital. In lots of cases, you possibly can patch your code (a 0.0 in an area copy of transformers would have worked), or create a “special operation” to cope with the exceptional case. Our exporters library has superb support for custom, special operations. See this instance for a missing einsum equation, or this one for a workaround to make StarCoder models work until a new edition of coremltools is released.
Fortunately, coremltools coverage for brand new operations is sweet and the team reacts very fast.