


Welcome to our latest dive into the world of leaderboards and models evaluation. In a previous post, we navigated the waters of evaluating Large Language Models. Today, we set sail to a unique, yet equally difficult domain – Object Detection.
Recently, we released our Object Detection Leaderboard, rating object detection models available within the Hub based on some metrics. On this blog, we are going to display how the models were evaluated and demystify the favored metrics utilized in Object Detection, from Intersection over Union (IoU) to Average Precision (AP) and Average Recall (AR). More importantly, we are going to highlight the inherent divergences and pitfalls that may occur during evaluation, ensuring that you just’re equipped with the knowledge not only to grasp but to evaluate model performance critically.
Every developer and researcher goals for a model that may accurately detect and delineate objects. Our Object Detection Leaderboard is the fitting place to search out an open-source model that most closely fits their application needs. But what does “accurate” truly mean on this context? Which metrics should one trust? How are they computed? And, perhaps more crucially, why some models may present divergent results in numerous reports? All these questions might be answered on this blog.
So, let’s embark on this exploration together and unlock the secrets of the Object Detection Leaderboard! In the event you prefer to skip the introduction and learn the way object detection metrics are computed, go to the Metrics section. In the event you wish to search out tips on how to pick one of the best models based on the Object Detection Leaderboard, you could check the Object Detection Leaderboard section.
Table of Contents
What’s Object Detection?
In the sector of Computer Vision, Object Detection refers back to the task of identifying and localizing individual objects inside a picture. Unlike image classification, where the duty is to find out the predominant object or scene within the image, object detection not only categorizes the thing classes present but additionally provides spatial information, drawing bounding boxes around each detected object. An object detector may also output a “rating” (or “confidence”) per detection. It represents the probability, based on the model, that the detected object belongs to the expected class for every bounding box.
The next image, as an example, shows five detections: one “ball” with a confidence of 98% and 4 “person” with a confidence of 98%, 95%, 97%, and 97%.

Object detection models are versatile and have a big selection of applications across various domains. Some use cases include vision in autonomous vehicles, face detection, surveillance and security, medical imaging, augmented reality, sports evaluation, smart cities, gesture recognition, etc.
The Hugging Face Hub has lots of of object detection models pre-trained in numerous datasets, in a position to discover and localize various object classes.
One specific kind of object detection models, called zero-shot, can receive additional text queries to go looking for goal objects described within the text. These models can detect objects they have not seen during training, as a substitute of being constrained to the set of classes used during training.
The variety of detectors goes beyond the range of output classes they will recognize. They vary by way of underlying architectures, model sizes, processing speeds, and prediction accuracy.
A preferred metric used to judge the accuracy of predictions made by an object detection model is the Average Precision (AP) and its variants, which might be explained later on this blog.
Evaluating an object detection model encompasses several components, like a dataset with ground-truth annotations, detections (output prediction), and metrics. This process is depicted within the schematic provided in Figure 2:
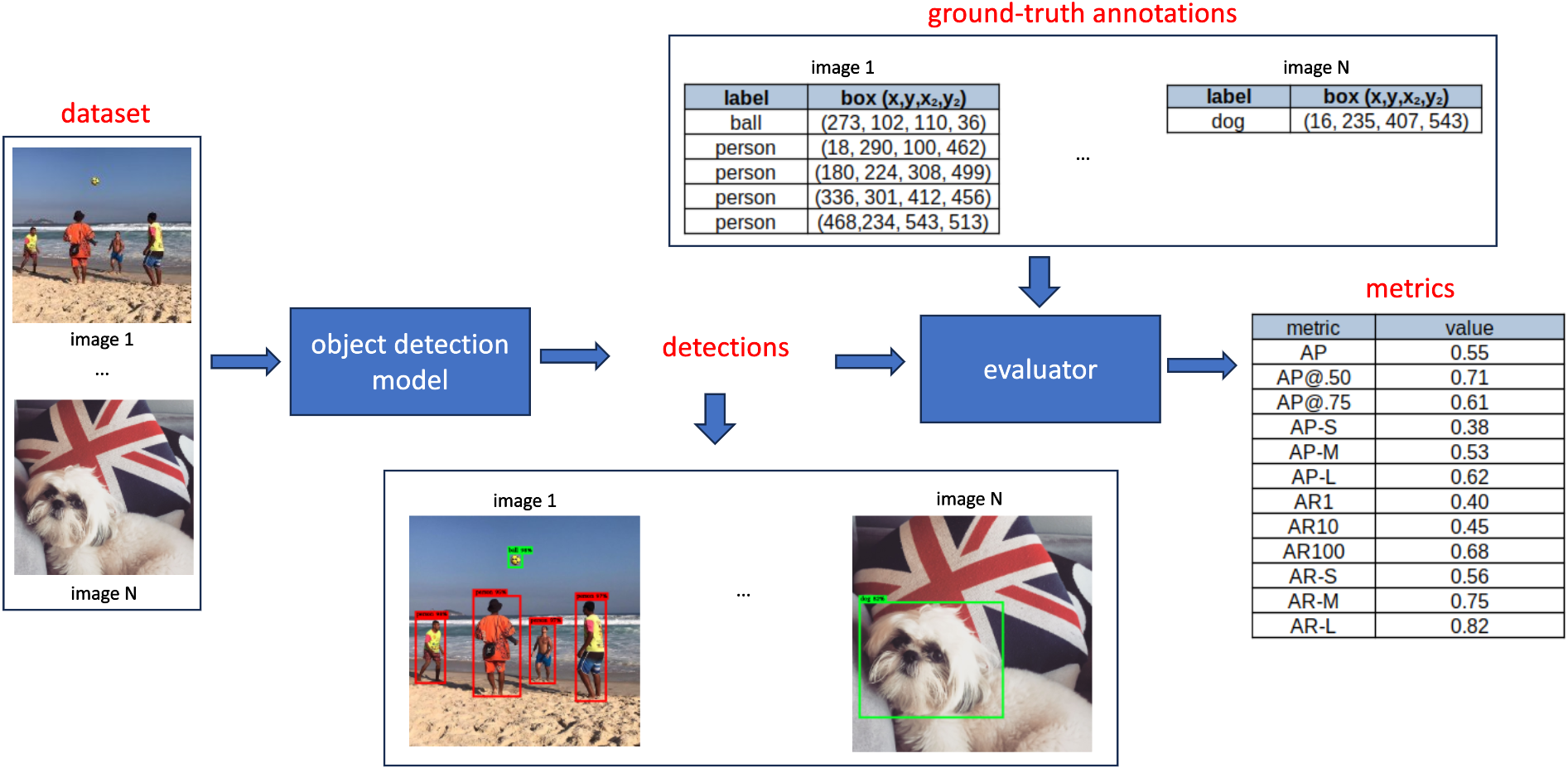
First, a benchmarking dataset containing images with ground-truth bounding box annotations is chosen and fed into the thing detection model. The model predicts bounding boxes for every image, assigning associated class labels and confidence scores to every box. In the course of the evaluation phase, these predicted bounding boxes are compared with the ground-truth boxes within the dataset. The evaluation yields a set of metrics, each ranging between [0, 1], reflecting a particular evaluation criteria. In the subsequent section, we’ll dive into the computation of the metrics intimately.
Metrics
This section will delve into the definition of Average Precision and Average Recall, their variations, and their associated computation methodologies.
What’s Average Precision and tips on how to compute it?
Average Precision (AP) is a single-number that summarizes the Precision x Recall curve. Before we explain tips on how to compute it, we first need to grasp the concept of Intersection over Union (IoU), and tips on how to classify a detection as a True Positive or a False Positive.
IoU is a metric represented by a number between 0 and 1 that measures the overlap between the expected bounding box and the actual (ground truth) bounding box. It’s computed by dividing the realm where the 2 boxes overlap by the realm covered by each boxes combined. Figure 3 visually demonstrates the IoU using an example of a predicted box and its corresponding ground-truth box.
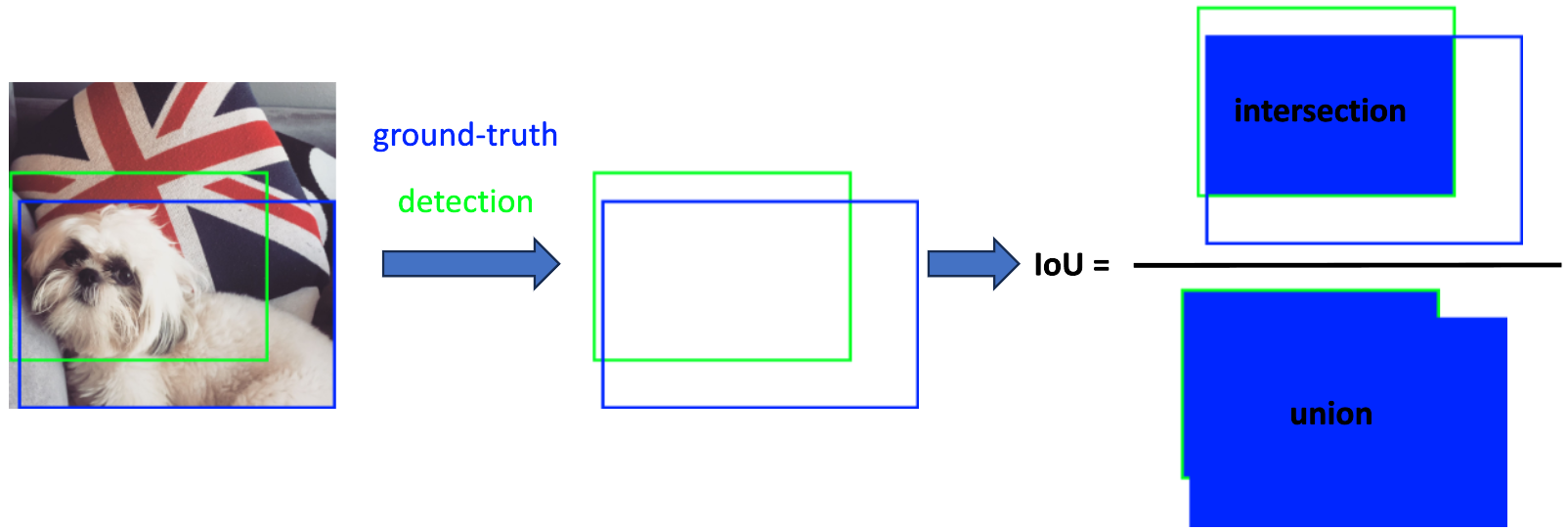
If the bottom truth and detected boxes share an identical coordinates, representing the identical region within the image, their IoU value is 1. Conversely, if the boxes don’t overlap at any pixel, the IoU is taken into account to be 0.
In scenarios where high precision in detections is anticipated (e.g. an autonomous vehicle), the expected bounding boxes should closely align with the ground-truth boxes. For that, a IoU threshold ( ) approaching 1 is preferred. However, for applications where the precise position of the detected bounding boxes relative to the goal object isn’t critical, the edge may be relaxed, setting closer to 0.
Every box predicted by the model is taken into account a “positive” detection. The Intersection over Union (IoU) criterion classifies each prediction as a real positive (TP) or a false positive (FP), based on the boldness threshold we defined.
Based on predefined , we will define True Positives and True Negatives:
- True Positive (TP): An accurate detection where IoU ≥ .
- False Positive (FP): An incorrect detection (missed object), where the IoU < .
Conversely, negatives are evaluated based on a ground-truth bounding box and may be defined as False Negative (FN) or True Negative (TN):
- False Negative (FN): Refers to a ground-truth object that the model did not detect.
- True Negative (TN): Denotes an accurate non-detection. Throughout the domain of object detection, countless bounding boxes inside a picture should NOT be identified, as they do not represent the goal object. Consider all possible boxes in a picture that don’t represent the goal object – quite an enormous number, isn’t it? 🙂 That is why we don’t consider TN to compute object detection metrics.
Now that we will discover our TPs, FPs, and FNs, we will define Precision and Recall:
- Precision is the power of a model to discover only the relevant objects. It’s the proportion of correct positive predictions and is given by:
which translates to the ratio of true positives over all detected boxes.
- Recall gauges a model’s competence find all of the relevant cases (all ground truth bounding boxes). It indicates the proportion of TP detected amongst all ground truths and is given by:
Note that TP, FP, and FN rely on a predefined IoU threshold, as do Precision and Recall.
Average Precision captures the power of a model to categorise and localize objects appropriately considering different values of Precision and Recall. For that we’ll illustrate the connection between Precision and Recall by plotting their respective curves for a particular goal class, say “dog”. We’ll adopt a moderate IoU threshold = 75% to delineate our TP, FP and FN. Subsequently, we will compute the Precision and Recall values. For that, we want to differ the boldness scores of our detections.
Figure 4 shows an example of the Precision x Recall curve. For a deeper exploration into the computation of this curve, the papers “A Comparative Evaluation of Object Detection Metrics with a Companion Open-Source Toolkit” (Padilla, et al) and “A Survey on Performance Metrics for Object-Detection Algorithms” (Padilla, et al) offer more detailed toy examples demonstrating tips on how to compute this curve.
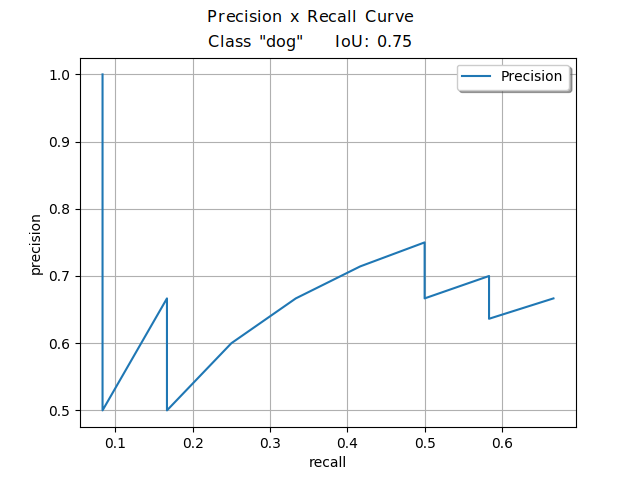
The Precision x Recall curve illustrates the balance between Precision and Recall based on different confidence levels of a detector’s bounding boxes. Each point of the plot is computed using a unique confidence value.
To display tips on how to calculate the Average Precision plot, we’ll use a practical example from one among the papers mentioned earlier. Consider a dataset of seven images with 15 ground-truth objects of the identical class, as shown in Figure 5. Let’s consider that each one boxes belong to the identical class, “dog” for simplification purposes.
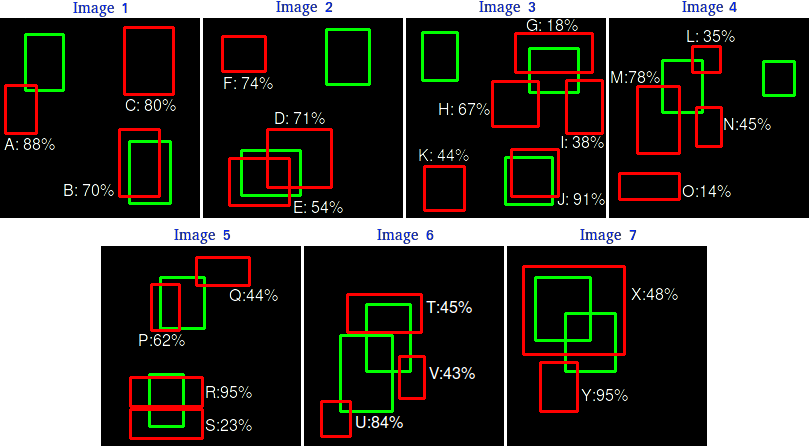
Our hypothetical object detector retrieved 24 objects in our dataset, illustrated by the red boxes. To compute Precision and Recall we use the Precision and Recall equations in any respect confidence levels to judge how well the detector performed for this specific class on our benchmarking dataset. For that, we want to ascertain some rules:
- Rule 1: For simplicity, let’s consider our detections a True Positive (TP) if IOU ≥ 30%; otherwise, it’s a False Positive (FP).
- Rule 2: For cases where a detection overlaps with multiple ground-truth (as in Images 2 to 7), the expected box with the very best IoU is taken into account TP, and the opposite is FP.
Based on these rules, we will classify each detection as TP or FP, as shown in Table 1:
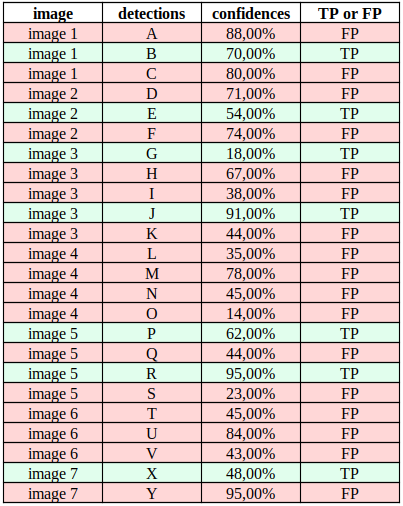
Note that by rule 2, in image 1, “E” is TP while “D” is FP because IoU between “E” and the ground-truth is bigger than IoU between “D” and the ground-truth.
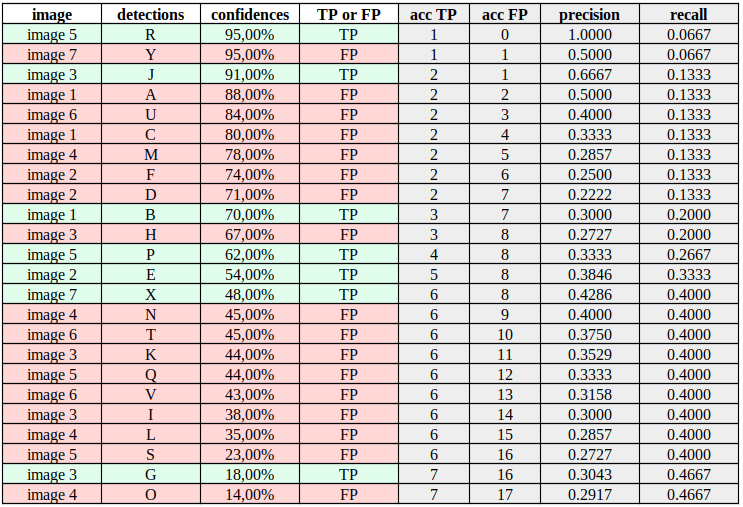
Now, we want to compute Precision and Recall considering the boldness value of every detection. A superb method to accomplish that is to sort the detections by their confidence values as shown in Table 2. Then, for every confidence value in each row, we compute the Precision and Recall considering the cumulative TP (acc TP) and cumulative FP (acc FP). The “acc TP” of every row is increased in 1 each time a TP is noted, and the “acc FP” is increased in 1 when a FP is noted. Columns “acc TP” and “acc FP” principally tell us the TP and FP values given a selected confidence level. The computation of every value of Table 2 may be viewed in this spreadsheet.
For instance, consider the twelfth row (detection “P”) of Table 2. The worth “acc TP = 4” signifies that if we benchmark our model on this particular dataset with a confidence of 0.62, we might appropriately detect 4 goal objects and incorrectly detect eight goal objects. This might end in:
and .
Now, we will plot the Precision x Recall curve with the values, as shown in Figure 6:
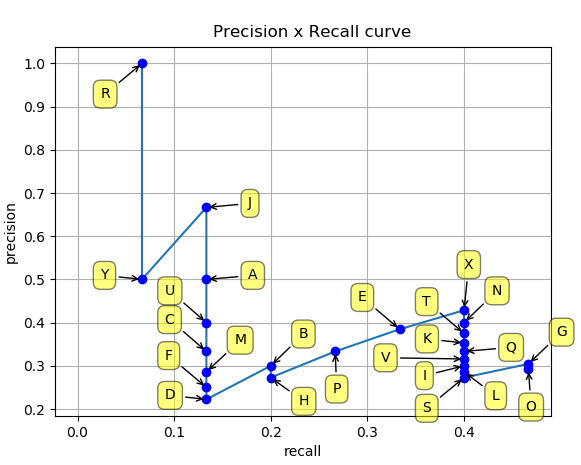
By examining the curve, one may infer the potential trade-offs between Precision and Recall and discover a model’s optimal operating point based on a specific confidence threshold, even when this threshold isn’t explicitly depicted on the curve.
If a detector’s confidence leads to a number of false positives (FP), it can likely have high Precision. Nonetheless, this might result in missing many true positives (TP), causing a high false negative (FN) rate and, subsequently, low Recall. However, accepting more positive detections can boost Recall but may also raise the FP count, thereby reducing Precision.
The world under the Precision x Recall curve (AUC) computed for a goal class represents the Average Precision value for that individual class. The COCO evaluation approach refers to “AP” because the mean AUC value amongst all goal classes within the image dataset, also known as Mean Average Precision (mAP) by other approaches.
For a big dataset, the detector will likely output boxes with a big selection of confidence levels, leading to a jagged Precision x Recall line, making it difficult to compute its AUC (Average Precision) precisely. Different methods approximate the realm of the curve with different approaches. A preferred approach known as N-interpolation, where N represents what number of points are sampled from the Precision x Recall blue line.
The COCO approach, as an example, uses 101-interpolation, which computes 101 points for equally spaced Recall values (0. , 0.01, 0.02, … 1.00), while other approaches use 11 points (11-interpolation). Figure 7 illustrates a Precision x Recall curve (in blue) with 11 equal-spaced Recall points.
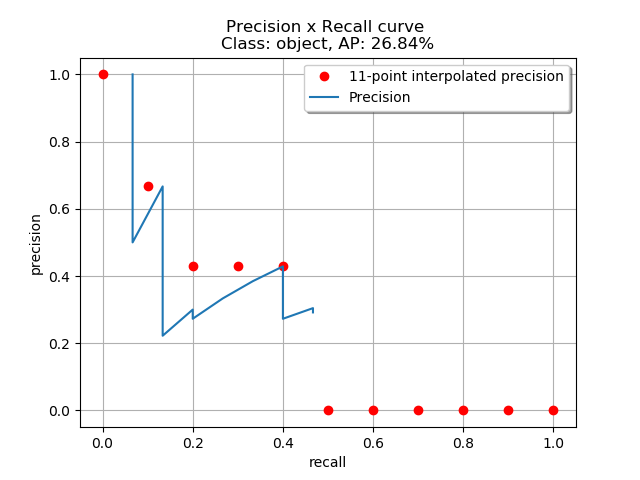
The red points are placed based on the next:
where is the measured Precision at Recall .
On this definition, as a substitute of using the Precision value observed in each Recall level , the Precision is obtained by considering the utmost Precision whose Recall value is bigger than .
For one of these approach, the AUC, which represents the Average Precision, is approximated by the common of all points and given by:
What’s Average Recall and tips on how to compute it?
Average Recall (AR) is a metric that is often used alongside AP to judge object detection models. While AP evaluates each Precision and Recall across different confidence thresholds to supply a single-number summary of model performance, AR focuses solely on the Recall aspect, not taking the confidences into consideration and considering all detections as positives.
COCO’s approach computes AR because the mean of the utmost obtained Recall over IOUs > 0.5 and classes.
Through the use of IOUs within the range [0.5, 1] and averaging Recall values across this interval, AR assesses the model’s predictions on their object localization. Hence, in case your goal is to judge your model for each high Recall and precise object localization, AR might be a useful evaluation metric to think about.
What are the variants of Average Precision and Average Recall?
Based on predefined IoU thresholds and the areas related to ground-truth objects, different versions of AP and AR may be obtained:
- AP@.5: sets IoU threshold = 0.5 and computes the Precision x Recall AUC for every goal class within the image dataset. Then, the computed results for every class are summed up and divided by the variety of classes.
- AP@.75: uses the identical methodology as AP@.50, with IoU threshold = 0.75. With this higher IoU requirement, AP@.75 is taken into account stricter than AP@.5 and needs to be used to judge models that need to realize a high level of localization accuracy of their detections.
- AP@[.5:.05:.95]: also referred to AP by cocoeval tools. That is an expanded version of AP@.5 and AP@.75, because it computes AP@ with different IoU thresholds (0.5, 0.55, 0.6,…,0.95) and averages the computed results as shown in the next equation. As compared to AP@.5 and AP@.75, this metric provides a holistic evaluation, capturing a model’s performance across a broader range of localization accuracies.
- AP-S: It applies AP@[.5:.05:.95] considering (small) ground-truth objects with pixels.
- AP-M: It applies AP@[.5:.05:.95] considering (medium-sized) ground-truth objects with pixels.
- AP-L: It applies AP@[.5:.05:.95] considering (large) ground-truth objects with pixels.
For Average Recall (AR), 10 IoU thresholds (0.5, 0.55, 0.6,…,0.95) are used to compute the Recall values. AR is computed by either limiting the variety of detections per image or by limiting the detections based on the thing’s area.
- AR-1: considers as much as 1 detection per image.
- AR-10: considers as much as 10 detections per image.
- AR-100: considers as much as 100 detections per image.
- AR-S: considers (small) objects with pixels.
- AR-M: considers (medium-sized) objects with pixels.
- AR-L: considers (large) objects with pixels.
Object Detection Leaderboard
We recently released the Object Detection Leaderboard to match the accuracy and efficiency of open-source models from our Hub.
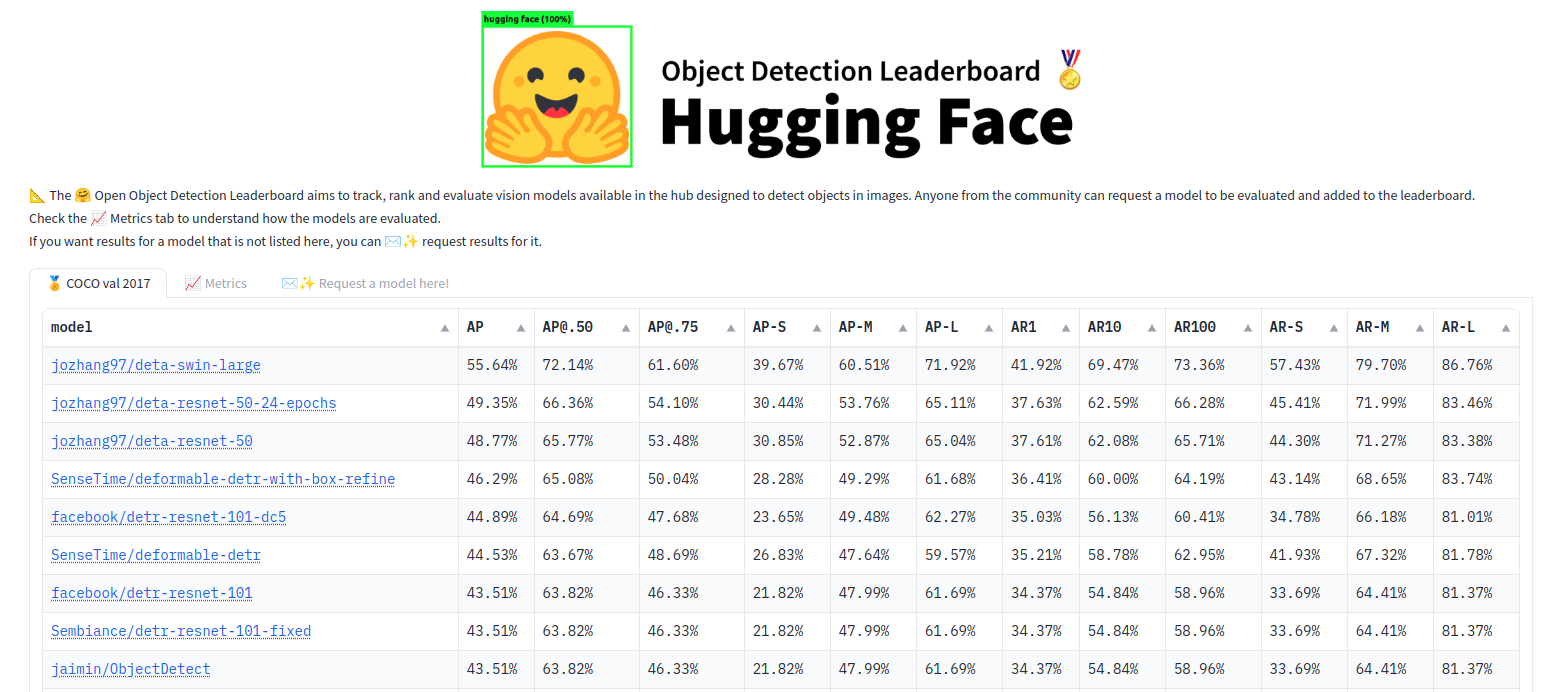
To measure accuracy, we used 12 metrics involving Average Precision and Average Recall using COCO style, benchmarking over COCO val 2017 dataset.
As discussed previously, different tools may adopt different particularities in the course of the evaluation. To forestall results mismatching, we preferred to not implement our version of the metrics. As a substitute, we opted to make use of COCO’s official evaluation code, also known as PyCOCOtools, code available here.
By way of efficiency, we calculate the frames per second (FPS) for every model using the common evaluation time across the complete dataset, considering pre and post-processing steps. Given the variability in GPU memory requirements for every model, we selected to judge with a batch size of 1 (this selection can be influenced by our pre-processing step, which we’ll delve into later). Nonetheless, it’s price noting that this approach may not align perfectly with real-world performance, as larger batch sizes (often containing several images), are commonly used for higher efficiency.
Next, we are going to provide recommendations on selecting one of the best model based on the metrics and indicate which parameters may interfere with the outcomes. Understanding these nuances is crucial, as this might spark doubts and discussions throughout the community.
The right way to pick one of the best model based on the metrics?
Choosing an appropriate metric to judge and compare object detectors considers several aspects. The first considerations include the appliance’s purpose and the dataset’s characteristics used to coach and evaluate the models.
For general performance, AP (AP@[.5:.05:.95]) is a superb selection for those who want all-round model performance across different IoU thresholds, and not using a hard requirement on the localization of the detected objects.
In the event you need a model with good object recognition and objects generally in the fitting place, you possibly can have a look at the AP@.5. In the event you prefer a more accurate model for putting the bounding boxes, AP@.75 is more appropriate.
If you could have restrictions on object sizes, AP-S, AP-M and AP-L come into play. For instance, in case your dataset or application predominantly features small objects, AP-S provides insights into the detector’s efficacy in recognizing such small targets. This becomes crucial in scenarios corresponding to detecting distant vehicles or small artifacts in medical imaging.
Which parameters can impact the Average Precision results?
After picking an object detection model from the Hub, we will vary the output boxes if we use different parameters within the model’s pre-processing and post-processing steps. These may influence the assessment metrics. We identified a number of the commonest aspects that will result in variations in results:
- Ignore detections which have a rating under a certain threshold.
- Use
batch_sizes > 1for inference. - Ported models don’t output the identical logits as the unique models.
- Some ground-truth objects could also be ignored by the evaluator.
- Computing the IoU could also be complicated.
- Text-conditioned models require precise prompts.
Let’s take the DEtection TRansformer (DETR) (facebook/detr-resnet-50) model as our example case. We are going to show how these aspects may affect the output results.
Thresholding detections before evaluation
Our sample model uses the DetrImageProcessor class to process the bounding boxes and logits, as shown within the snippet below:
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.5)
The parameter threshold in function post_process_object_detection is used to filter the detected bounding boxes based on their confidence scores.
As previously discussed, the Precision x Recall curve is built by measuring the Precision and Recall across the total range of confidence values [0,1]. Thus, limiting the detections before evaluation will produce biased results, as we are going to leave some detections out.
Various the batch size
The batch size not only affects the processing time but can also result in numerous detected boxes. The image pre-processing step may change the resolution of the input images based on their sizes.
As mentioned in DETR documentation, by default, DetrImageProcessor resizes the input images such that the shortest side is 800 pixels, and resizes again in order that the longest is at most 1333 pixels. On account of this, images in a batch can have different sizes. DETR solves this by padding images as much as the biggest size in a batch, and by making a pixel mask that indicates which pixels are real/that are padding.
As an instance this process, let’s consider the examples in Figure 9 and Figure 10. In Figure 9, we consider batch size = 1, so each images are processed independently with DetrImageProcessor. The primary image is resized to (800, 1201), making the detector predict 28 boxes with class vase, 22 boxes with class chair, ten boxes with class bottle, etc.
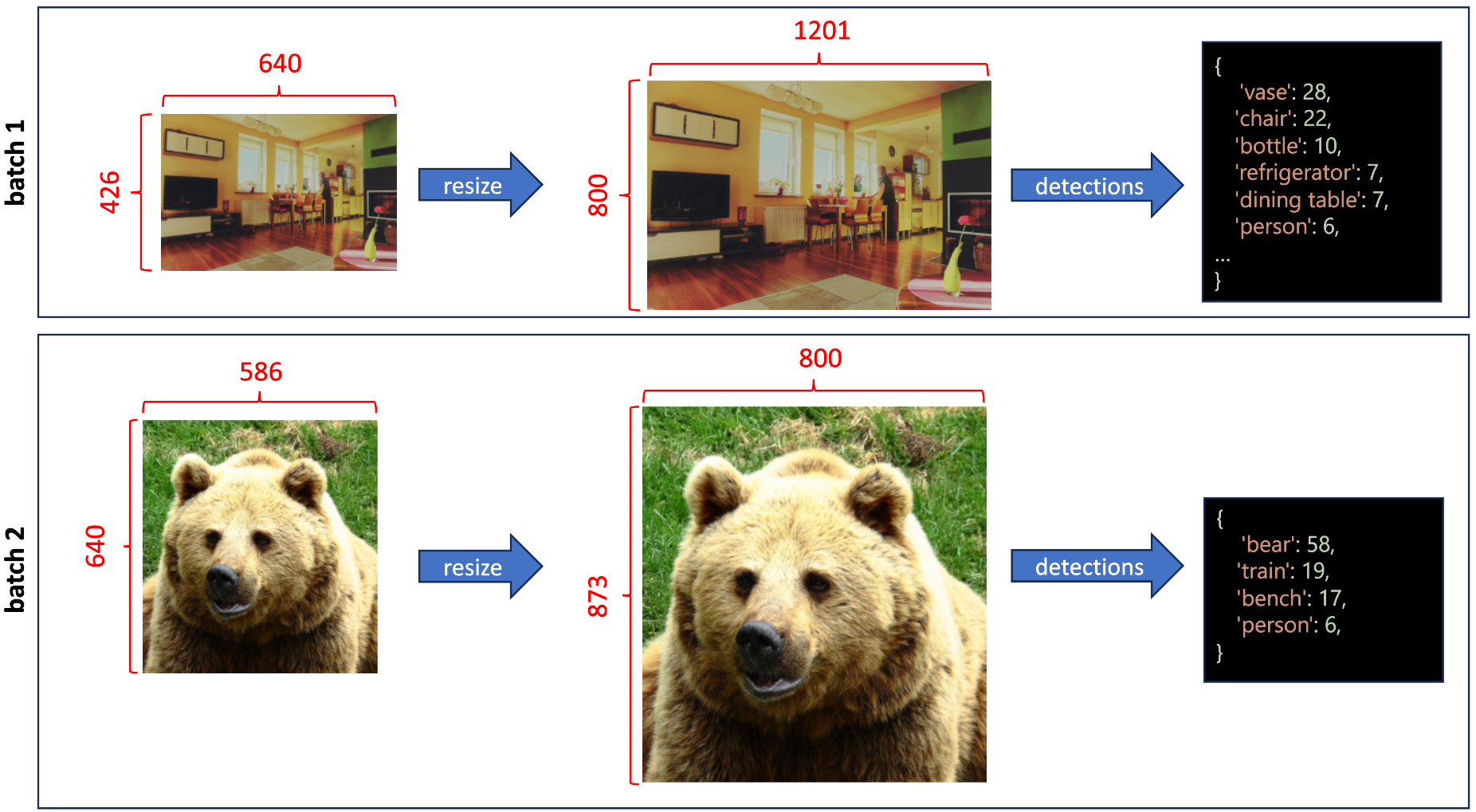
Figure 10 shows the method with batch size = 2, where the identical two images are processed with DetrImageProcessor in the identical batch. Each images are resized to have the identical shape (873, 1201), and padding is applied, so the a part of the photographs with the content is kept with their original aspect ratios. Nonetheless, the primary image, as an example, outputs a unique variety of objects: 31 boxes with the category vase, 20 boxes with the category chair, eight boxes with the category bottle, etc. Note that for the second image, with batch size = 2, a brand new class is detected dog. This happens as a result of the model’s capability to detect objects of various sizes depending on the image’s resolution.

Ported models should output the identical logits as the unique models
At Hugging Face, we’re very careful when porting models to our codebase. Not only with respect to the architecture, clear documentation and coding structure, but we also need to ensure that the ported models are in a position to produce the identical logits as the unique models given the identical inputs.
The logits output by a model are post-processed to supply the boldness scores, label IDs, and bounding box coordinates. Thus, minor changes within the logits can influence the metrics results. You could recall the instance above, where we discussed the means of computing Average Precision. We showed that confidence levels sort the detections, and small variations may result in a unique order and, thus, different results.
It is important to acknowledge that models can produce boxes in various formats, and that also could also be considered, making proper conversions required by the evaluator.
- (x, y, width, height): this represents the upper-left corner coordinates followed by absolutely the dimensions (width and height).
- (x, y, x2, y2): this format indicates the coordinates of the upper-left corner and the lower-right corner.
- (rel_x_center, rel_y_center, rel_width, rel_height): the values represent the relative coordinates of the middle and the relative dimensions of the box.
Some ground-truths are ignored in some benchmarking datasets
Some datasets sometimes use special labels which can be ignored in the course of the evaluation process.
COCO, as an example, uses the tag iscrowd to label large groups of objects (e.g. many apples in a basket). During evaluation, objects tagged as iscrowd=1 are ignored. If this isn’t considered, you could obtain different results.
Calculating the IoU requires careful consideration
IoU might sound straightforward to calculate based on its definition. Nonetheless, there’s a vital detail to concentrate on: if the bottom truth and the detection don’t overlap in any respect, not even by one pixel, the IoU needs to be 0. To avoid dividing by zero when calculating the union, you possibly can add a small value (called epsilon), to the denominator. Nonetheless, it’s essential to decide on epsilon fastidiously: a price greater than 1e-4 may not be neutral enough to present an accurate result.
Text-conditioned models demand the fitting prompts
There could be cases wherein we would like to judge text-conditioned models corresponding to OWL-ViT, which might receive a text prompt and supply the situation of the specified object.
For such models, different prompts (e.g. “Find the dog” and “Where’s the bulldog?”) may end in the identical results. Nonetheless, we decided to follow the procedure described in each paper. For the OWL-ViT, as an example, we predict the objects by utilizing the prompt “a picture of a {}” where {} is replaced with the benchmarking dataset’s classes.
Conclusions
On this post, we introduced the issue of Object Detection and depicted the principal metrics used to judge them.
As noted, evaluating object detection models may take more work than it looks. The particularities of every model should be fastidiously considered to forestall biased results. Also, each metric represents a unique standpoint of the identical model, and picking “one of the best” metric depends upon the model’s application and the characteristics of the chosen benchmarking dataset.
Below is a table that illustrates really helpful metrics for specific use cases and provides real-world scenarios as examples. Nonetheless, it is important to notice that these are merely suggestions, and the perfect metric can vary based on the distinct particularities of every application.
| Use Case | Real-world Scenarios | Really useful Metric |
|---|---|---|
| General object detection performance | Surveillance, sports evaluation | AP |
| Low accuracy requirements (broad detection) | Augmented reality, gesture recognition | AP@.5 |
| High accuracy requirements (tight detection) | Face detection | AP@.75 |
| Detecting small objects | Distant vehicles in autonomous cars, small artifacts in medical imaging | AP-S |
| Medium-sized objects detection | Luggage detection in airport security scans | AP-M |
| Large-sized objects detection | Detecting vehicles in parking lots | AP-L |
| Detecting 1 object per image | Single object tracking in videos | AR-1 |
| Detecting as much as 10 objects per image | Pedestrian detection in street cameras | AR-10 |
| Detecting as much as 100 objects per image | Crowd counting | AR-100 |
| Recall for small objects | Medical imaging for tiny anomalies | AR-S |
| Recall for medium-sized objects | Sports evaluation for players | AR-M |
| Recall for giant objects | Wildlife tracking in wide landscapes | AR-L |
The outcomes shown in our 🤗 Object Detection Leaderboard are computed using an independent tool PyCOCOtools widely utilized by the community for model benchmarking. We’re aiming to gather datasets of various domains (e.g. medical images, sports, autonomous vehicles, etc). You should use the discussion page to make requests for datasets, models and features. Wanting to see your model or dataset feature on our leaderboard? Don’t hold back! Introduce your model and dataset, fine-tune, and let’s get it ranked! 🥇
Additional Resources
Special thanks 🙌 to @merve, @osanseviero and @pcuenq for his or her feedback and great comments. 🤗