



The rise of Generative AI and LLMs like ChatGPT has increased the interest and importance of embedding models for a wide range of tasks especially for retrievel augemented generation, like search or chat together with your data. Embeddings are helpful since they represent sentences, images, words, etc. as numeric vector representations, which allows us to map semantically related items and retrieve helpful information. This helps us to supply relevant context for our prompt to enhance the standard and specificity of generation.
In comparison with LLMs are Embedding Models smaller in size and faster for inference. That may be very vital since it’s essential to recreate your embeddings after you modified your model or improved your model fine-tuning. Moreover, is it vital that the entire retrieval augmentation process is as fast as possible to supply user experience.
On this blog post, we are going to show you learn how to deploy open-source Embedding Models to Hugging Face Inference Endpoints using Text Embedding Inference, our managed SaaS solution that makes it easy to deploy models. Moreover, we are going to teach you learn how to run large scale batch requests.
- What’s Hugging Face Inference Endpoints
- What’s Text Embedding Inference
- Deploy Embedding Model as Inference Endpoint
- Send request to endpoint and create embeddings
Before we start, let’s refresh our knowledge about Inference Endpoints.
1. What’s Hugging Face Inference Endpoints?
Hugging Face Inference Endpoints offers a straightforward and secure strategy to deploy Machine Learning models to be used in production. Inference Endpoints empower developers and data scientists to create Generative AI applications without managing infrastructure: simplifying the deployment process to a couple of clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security.
Listed below are a few of a very powerful features:
- Easy Deployment: Deploy models as production-ready APIs with just a couple of clicks, eliminating the necessity to handle infrastructure or MLOps.
- Cost Efficiency: Profit from automatic scale to zero capability, reducing costs by cutting down the infrastructure when the endpoint will not be in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness.
- Enterprise Security: Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance.
- LLM Optimization: Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference
- Comprehensive Task Support: Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and simple customization to enable advanced tasks like speaker diarization or any Machine Learning task and library.
You’ll be able to start with Inference Endpoints at: https://ui.endpoints.huggingface.co/
2. What’s Text Embeddings Inference?
Text Embeddings Inference (TEI) is a purpose built solution for deploying and serving open source text embeddings models. TEI is construct for high-performance extraction supporting the preferred models. TEI supports all top 10 models of the Massive Text Embedding Benchmark (MTEB) Leaderboard, including FlagEmbedding, Ember, GTE and E5. TEI currently implements the next performance optimizing features:
- No model graph compilation step
- Small docker images and fast boot times. Prepare for true serverless!
- Token based dynamic batching
- Optimized transformers code for inference using Flash Attention, Candle and cuBLASLt
- Safetensors weight loading
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
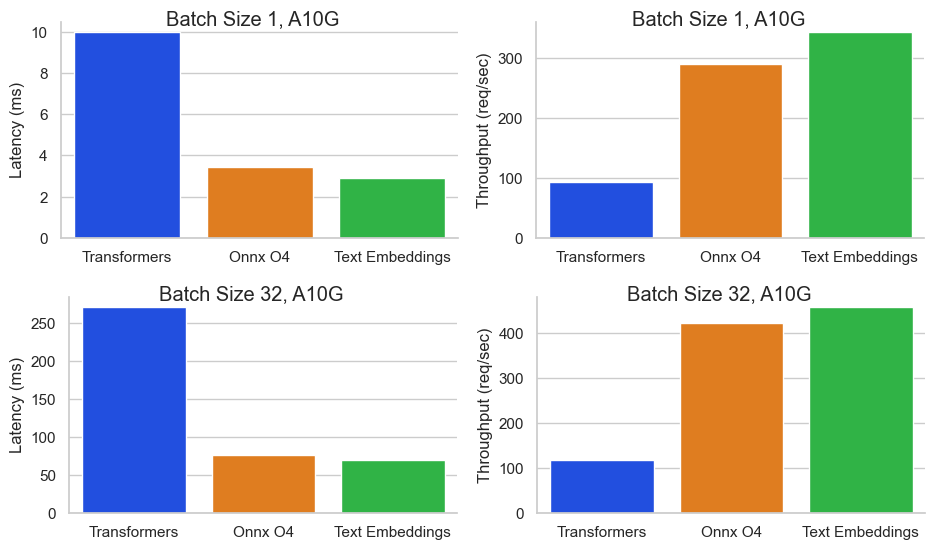
Those feature enabled industry-leading performance on throughput and price. In a benchmark for BAAI/bge-base-en-v1.5 on an Nvidia A10G Inference Endpoint with a sequence length of 512 tokens and a batch size of 32, we achieved a throughput of 450+ req/sec resulting into a value of 0.00156$ / 1M tokens or 0.00000156$ / 1k tokens. That’s 64x cheaper than OpenAI Embeddings ($0.0001 / 1K tokens).
3. Deploy Embedding Model as Inference Endpoint
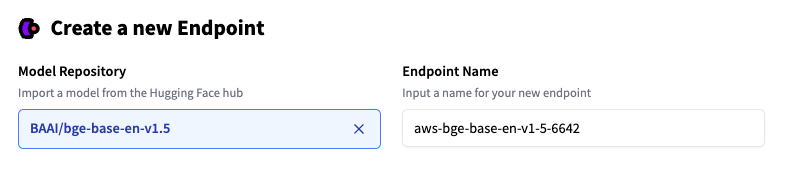
To start, it’s essential to be logged in with a User or Organization account with a payment method on file (you may add one here), then access Inference Endpoints at https://ui.endpoints.huggingface.co
Then, click on “Latest endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case BAAI/bge-base-en-v1.5.
Inference Endpoints suggest an instance type based on the model size, which needs to be sufficiently big to run the model. Here Intel Ice Lake 2 vCPU. To get the performance for the benchmark we ran you, change the instance to 1x Nvidia A10G.
Note: If the instance type can’t be chosen, it’s essential to contact us and request an instance quota.

You’ll be able to then deploy your model with a click on “Create Endpoint”. After 1-3 minutes, the Endpoint needs to be online and available to serve requests.
4. Send request to endpoint and create embeddings
The Endpoint overview provides access to the Inference Widget, which may be used to manually send requests. This lets you quickly test your Endpoint with different inputs and share it with team members.
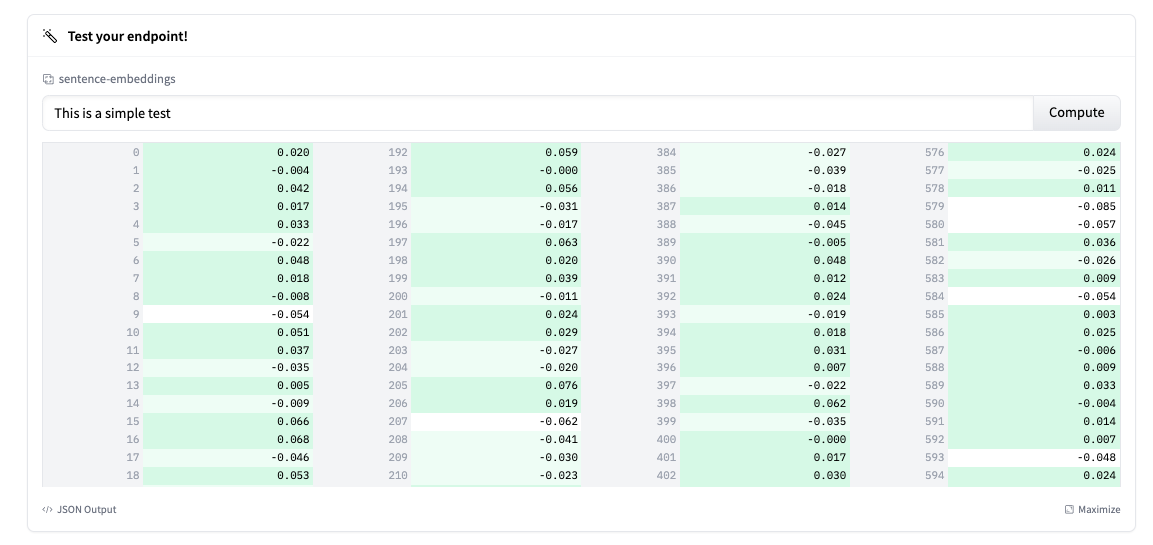
Note: TEI is currently will not be mechanically truncating the input. You’ll be able to enable this by setting truncate: true in your request.
Along with the widget the overview provides an code snippet for cURL, Python and Javascript, which you should use to send request to the model. The code snippet shows you learn how to send a single request, but TEI also supports batch requests, which lets you send multiple document at the identical to extend utilization of your endpoint. Below is an example on learn how to send a batch request with truncation set to true.
import requests
API_URL = "https://l2skjfwp9punv393.us-east-1.aws.endpoints.huggingface.cloud"
headers = {
"Authorization": "Bearer YOUR TOKEN",
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": ["sentence 1", "sentence 2", "sentence 3"],
"truncate": True
})
Conclusion
TEI on Hugging Face Inference Endpoints enables blazing fast and ultra cost-efficient deployment of state-of-the-art embeddings models. With industry-leading throughput of 450+ requests per second and costs as little as $0.00000156 / 1k tokens, Inference Endpoints delivers 64x cost savings in comparison with OpenAI Embeddings.
For developers and firms leveraging text embeddings to enable semantic search, chatbots, recommendations, and more, Hugging Face Inference Endpoints eliminates infrastructure overhead and delivers high throughput at lowest cost streamlining the method from research to production.
Thanks for reading! If you will have any questions, be at liberty to contact me on Twitter or LinkedIn.