
On this blogpost, we are going to introduce you to the concept of Matryoshka Embeddings and explain why they’re useful. We’ll discuss how these models are theoretically trained and the way you may train them using Sentence Transformers.
Moreover, we are going to provide practical guidance on easy methods to use Matryoshka Embedding models and share a comparison between a Matryoshka embedding model and an everyday embedding model. Finally, we invite you to envision out our interactive demo that showcases the ability of those models.
Table of Contents
Understanding Embeddings
Embeddings are one of the versatile tools in natural language processing, enabling practitioners to resolve a big number of tasks. In essence, an embedding is a numerical representation of a more complex object, like text, images, audio, etc.
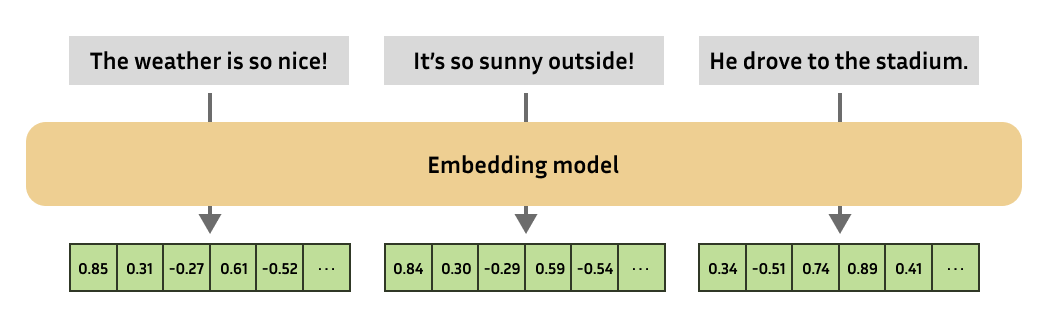
The embedding model will at all times produce embeddings of the identical fixed size. You may then compute the similarity of complex objects by computing the similarity of the respective embeddings!
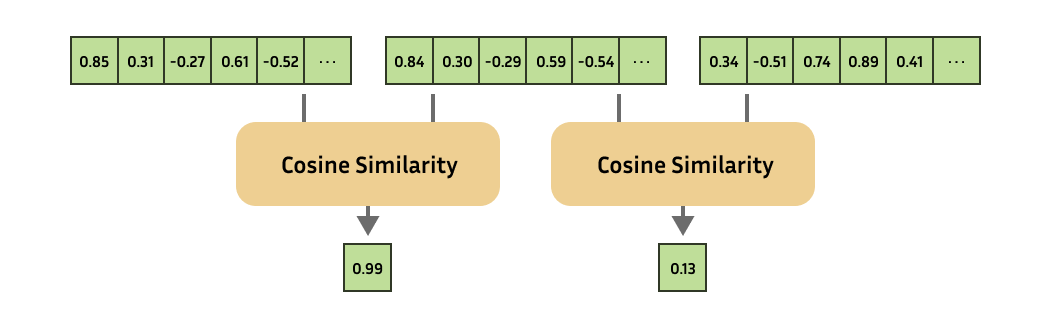
This has an unlimited amount of use cases, and serves because the backbone for advice systems, retrieval, one-shot or few-shot learning, outlier detection, similarity search, paraphrase detection, clustering, classification, and rather more!
🪆 Matryoshka Embeddings
As research progressed, latest state-of-the-art (text) embedding models began producing embeddings with increasingly higher output dimensions, i.e., every input text is represented using more values. Although this improves performance, it comes at the fee of efficiency of downstream tasks resembling search or classification.
Consequently, Kusupati et al. (2022) were inspired to create embedding models whose embeddings could reasonably be shrunk without suffering an excessive amount of on performance.
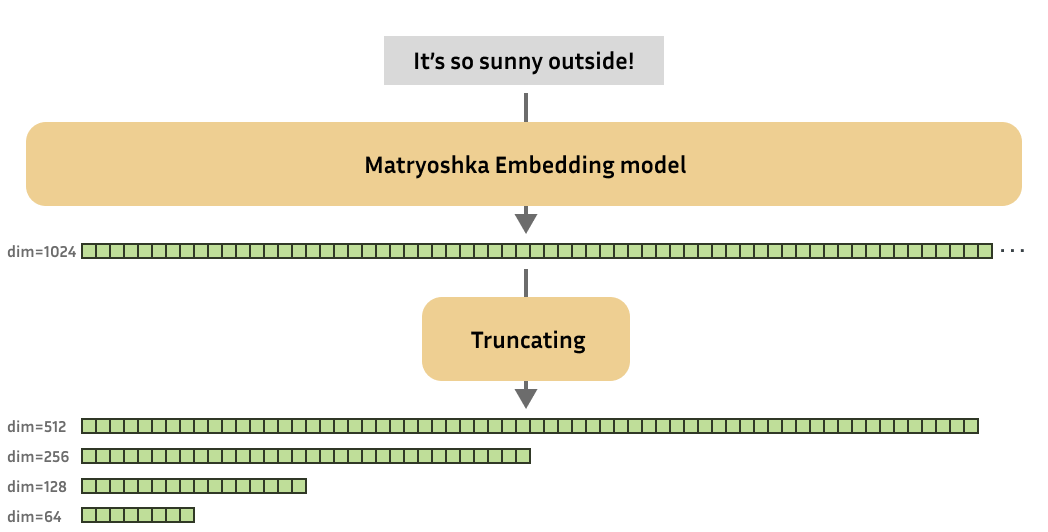
These Matryoshka embedding models are trained such that these small truncated embeddings would still be useful. Briefly, Matryoshka embedding models can produce useful embeddings of varied dimensions.
🪆 Matryoshka Dolls
For those unfamiliar, “Matryoshka dolls”, also generally known as “Russian nesting dolls”, are a set of picket dolls of decreasing size which are placed inside each other. In an analogous way, Matryoshka embedding models aim to store more vital information in earlier dimensions, and fewer vital information in later dimensions. This characteristic of Matryoshka embedding models allows us to truncate the unique (large) embedding produced by the model, while still retaining enough of the data to perform well on downstream tasks.
Why would you utilize 🪆 Matryoshka Embedding models?
Such variable-size embedding models might be quite invaluable to practitioners, for instance:
- Shortlisting and reranking: Slightly than performing your downstream task (e.g., nearest neighbor search) on the total embeddings, you may shrink the embeddings to a smaller size and really efficiently “shortlist” your embeddings. Afterwards, you may process the remaining embeddings using their full dimensionality.
- Trade-offs: Matryoshka models will help you scale your embedding solutions to your required storage cost, processing speed, and performance.
How are 🪆 Matryoshka Embedding models trained?
Theoretically
The Matryoshka Representation Learning (MRL) approach might be adopted for just about all embedding model training frameworks. Normally, a training step for an embedding model involves producing embeddings on your training batch (of texts, for instance) after which using some loss function to create a loss value that represents the standard of the produced embeddings. The optimizer will adjust the model weights throughout training to cut back the loss value.
For Matryoshka Embedding models, a training step also involves producing embeddings on your training batch, but you then use some loss function to find out not only the standard of your full-size embeddings, but in addition the standard of your embeddings at various different dimensionalities. For instance, output dimensionalities are 768, 512, 256, 128, and 64. The loss values for every dimensionality are added together, leading to a final loss value. The optimizer will then attempt to adjust the model weights to lower this loss value.
In practice, this incentivizes the model to frontload crucial information at the beginning of an embedding, such that it’ll be retained if the embedding is truncated.
In Sentence Transformers
Sentence Transformers is a commonly used framework to coach embedding models, and it recently implemented support for Matryoshka models. Training a Matryoshka embedding model using Sentence Transformers is kind of elementary: relatively than applying some loss function on only the full-size embeddings, we also apply that very same loss function on truncated portions of the embeddings.
For instance, if a model has an original embedding dimension of 768, it will probably now be trained on 768, 512, 256, 128 and 64. Each of those losses will probably be added together, optionally with some weight:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(
model=model,
loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64],
matryoshka_weight=[1, 1, 1, 1, 1],
)
model.fit(
train_objectives=[(train_dataset, loss)],
...,
)
Training with MatryoshkaLoss doesn’t incur a notable overhead in training time.
References:
See the next complete scripts as examples of easy methods to apply the MatryoshkaLoss in practice:
- matryoshka_nli.py: This instance uses the
MultipleNegativesRankingLosswithMatryoshkaLossto coach a powerful embedding model using Natural Language Inference (NLI) data. It’s an adaptation of the NLI documentation. - matryoshka_nli_reduced_dim.py: This instance uses the
MultipleNegativesRankingLosswithMatryoshkaLossto coach a powerful embedding model with a small maximum output dimension of 256. It trains using Natural Language Inference (NLI) data, and is an adaptation of the NLI documentation. - matryoshka_sts.py: This instance uses the
CoSENTLosswithMatryoshkaLossto coach an embedding model on the training set of theSTSBenchmarkdataset. It’s an adaptation of the STS documentation.
How do I take advantage of 🪆 Matryoshka Embedding models?
Theoretically
In practice, getting embeddings from a Matryoshka embedding model works the identical way as with a traditional embedding model. The one difference is that, after receiving the embeddings, we will optionally truncate them to a smaller dimensionality. Do note that if the embeddings were normalized, then after truncating they’ll now not be, so you might wish to re-normalize.
After truncating, you may either directly apply them on your use cases, or store them such that they might be used later. In any case, smaller embeddings in your vector database should end in considerable speedups!
Have in mind that although processing smaller embeddings for downstream tasks (retrieval, clustering, etc.) will probably be faster, getting the smaller embeddings from the model is just as fast as getting the larger ones.
In Sentence Transformers
In Sentence Transformers, you may load a Matryoshka Embedding model just like several other model, but you may specify the specified embedding size using the truncate_dim argument. After that, you may perform inference using the SentenceTransformers.encode function, and the embeddings will probably be mechanically truncated to the desired size.
Let’s try to make use of a model that I trained using matryoshka_nli.py with microsoft/mpnet-base:
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
matryoshka_dim = 64
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka", truncate_dim=matryoshka_dim)
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
print(embeddings.shape)
similarities = cos_sim(embeddings[0], embeddings[1:])
print(similarities)
Be happy to experiment with using different values for matryoshka_dim and observe how that affects the similarities. You may accomplish that either by running this code locally, on the cloud resembling with Google Colab, or by trying out the demo.
References:
Click here to see easy methods to use the Nomic v1.5 Matryoshka Model
Note: Nomic specifically requires an F.layer_norm before the embedding truncation. Because of this, the next snippet uses manual truncation to the specified dimension. For all other models, you should utilize the truncate_dim option within the constructor, as shown within the previous example.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
],
convert_to_tensor=True,
)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings[..., :matryoshka_dim]
similarities = cos_sim(embeddings[0], embeddings[1:])
Results
Now that Matryoshka models have been introduced, let us take a look at the actual performance that we may find a way to expect from a Matryoshka embedding model versus an everyday embedding model. For this experiment, I actually have trained two models:
Each of those models were trained on the AllNLI dataset, which is a concatenation of the SNLI and MultiNLI datasets. I actually have evaluated these models on the STSBenchmark test set using multiple different embedding dimensions. The outcomes are plotted in the next figure:
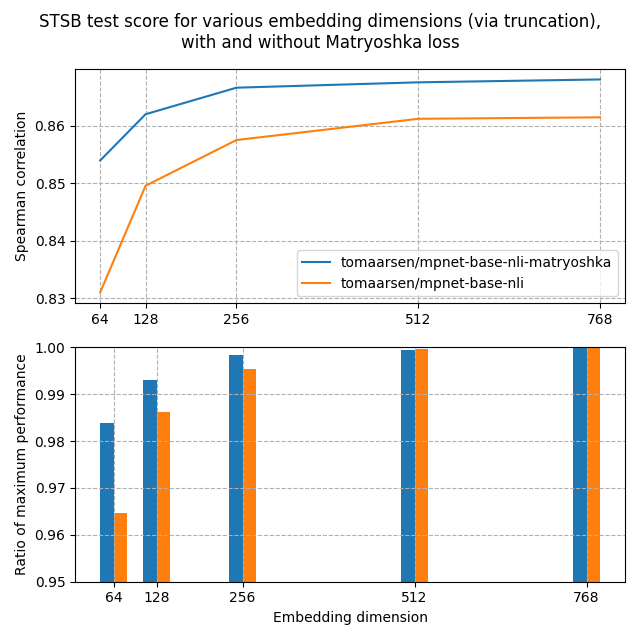
In the highest figure, you may see that the Matryoshka model reaches the next Spearman similarity than the usual model in any respect dimensionalities, indicative that the Matryoshka model is superior on this task.
Moreover, the performance of the Matryoshka model falls off much less quickly than the usual model. That is shown clearly within the second figure, which shows the performance on the embedding dimension relative to the utmost performance. Even at 8.3% of the embedding size, the Matryoshka model preserves 98.37% of the performance, much higher than the 96.46% by the usual model.
These findings are indicative that truncating embeddings by a Matryoshka model could: 1) significantly speed up downstream tasks resembling retrieval and a couple of) significantly save on space for storing, all with out a notable hit in performance.
Demo
On this demo, you may dynamically shrink the output dimensions of the nomic-ai/nomic-embed-text-v1.5 Matryoshka embedding model and observe the way it affects the retrieval performance. The entire embeddings are computed within the browser using 🤗 Transformers.js.
References
- Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., … & Farhadi, A. (2022). Matryoshka representation learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147
- Matryoshka Embeddings — Sentence-Transformers documentation. (n.d.). https://sbert.net/examples/training/matryoshka/README.html
- UKPLab. (n.d.). GitHub. https://github.com/UKPLab/sentence-transformers
- Unboxing Nomic Embed v1.5: Resizable Production Embeddings with Matryoshka Representation Learning. (n.d.). https://blog.nomic.ai/posts/nomic-embed-matryoshka