

This blog post introduces a way to coach static embedding models that run 100x to 400x faster on CPU than state-of-the-art embedding models, while retaining many of the quality. This unlocks a whole lot of exciting use cases, including on-device and in-browser execution, edge computing, low power and embedded applications.
We apply this recipe to coach two extremely efficient embedding models: sentence-transformers/static-retrieval-mrl-en-v1 for English Retrieval, and sentence-transformers/static-similarity-mrl-multilingual-v1 for Multilingual Similarity tasks. These models are 100x to 400x faster on CPU than common counterparts like all-mpnet-base-v2 and multilingual-e5-small, while reaching not less than 85% of their performance on various benchmarks.
Today, we’re releasing:
- The 2 models (for English retrieval and for multilingual similarity) mentioned above.
- The detailed training strategy we followed, from ideation to dataset selection to implementation and evaluation.
- Two training scripts, based on the open-source sentence transformers library.
- Two Weights and Biases reports with training and evaluation metrics collected during training.
- The detailed list of datasets we used: 30 for training and 13 for evaluation.
We also discuss potential enhancements, and encourage the community to explore them and construct on this work!
Click to see Usage Snippets for the released models
The usage of those models may be very straightforward, equivalent to the traditional Sentence Transformers flow:
English Retrieval
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-retrieval-mrl-en-v1", device="cpu")
sentences = [
'Gadofosveset-enhanced MR angiography of carotid arteries: does steady-state imaging improve accuracy of first-pass imaging?',
'To evaluate the diagnostic accuracy of gadofosveset-enhanced magnetic resonance (MR) angiography in the assessment of carotid artery stenosis, with digital subtraction angiography (DSA) as the reference standard, and to determine the value of reading first-pass, steady-state, and "combined" (first-pass plus steady-state) MR angiograms.',
'In a longitudinal study we investigated in vivo alterations of CVO during neuroinflammation, applying Gadofluorine M- (Gf) enhanced magnetic resonance imaging (MRI) in experimental autoimmune encephalomyelitis, an animal model of multiple sclerosis. SJL/J mice were monitored by Gadopentate dimeglumine- (Gd-DTPA) and Gf-enhanced MRI after adoptive transfer of proteolipid-protein-specific T cells. Mean Gf intensity ratios were calculated individually for different CVO and correlated to the clinical disease course. Subsequently, the tissue distribution of fluorescence-labeled Gf as well as the extent of cellular inflammation was assessed in corresponding histological slices.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings[0], embeddings[1:])
print(similarities)
Multilingual Similarity
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-similarity-mrl-multilingual-v1", device="cpu")
sentences = [
'It is known for its dry red chili powder.',
'It is popular for dried red chili powder.',
'These monsters will move in large groups.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)

Table of Contents
What are Embeddings?
Embeddings are some of the versatile tools in natural language processing, enabling practitioners to resolve a big number of tasks. In essence, an embedding is a numerical representation of a more complex object, like text, images, audio, etc.
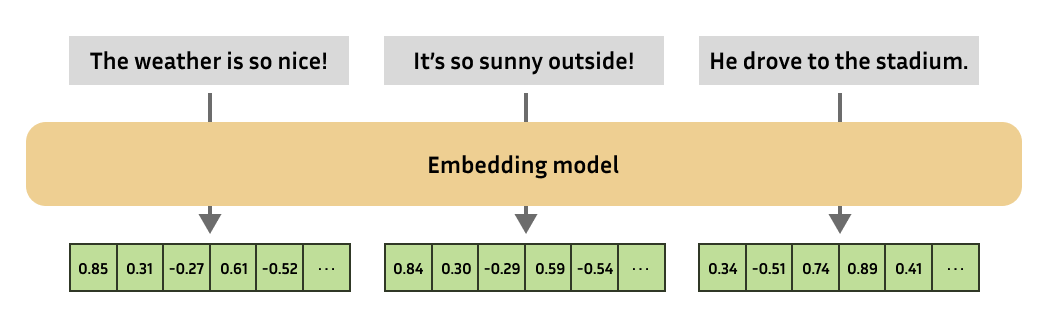
The embedding model will all the time produce embeddings of the identical fixed size. You may then compute the similarity of complex objects by computing the similarity of the respective embeddings.
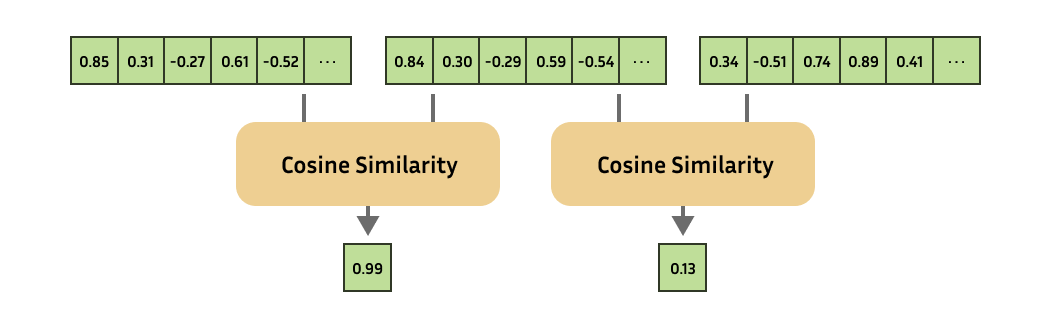
This has a considerable amount of use cases, and serves because the backbone for advice systems, retrieval, outlier detection, one-shot or few-shot learning, similarity search, clustering, paraphrase detection, classification, and way more.
Modern Embeddings
Lots of today’s embedding models consist of a handful of conversion steps. Following these steps known as “inference”.

The Tokenizer and Pooler are accountable for pre- and post-processing for the Encoder, respectively. The previous chops texts up into tokens (a.k.a. words or subwords) which could be understood by the Encoder, whereas the latter combines the embeddings for all tokens into one embedding for your complete text.
Inside this pipeline, the Encoder is usually a language model with attention layers, which allows each token to be computed throughout the context of the opposite tokens. For instance, bank could be a token, however the token embedding for that token will likely be different if the text refers to a “river bank” or the financial institution.
Large encoder models with a whole lot of attention layers might be effective at using the context to provide useful embeddings, but they accomplish that at a high price of slow inference. Notably, within the pipeline, the Encoder step is usually accountable for almost all the computational time.
Static Embeddings
Static Embeddings refers to a bunch of Encoder models that do not use large and slow attention-based models, but as a substitute depend on pre-computed token embeddings. Static embeddings were used years before the transformer architecture was developed. Common examples include GLoVe and word2vec. Recently, Model2Vec has been used to convert pre-trained embedding models into Static Embedding models.
For Static Embeddings, the Encoder step is so simple as a dictionary lookup: given the token, return the pre-computed token embedding. Consequently, inference is suddenly now not bottlenecked by the Encoder phase, leading to speedups of several orders of magnitude. This blogpost shows that the hit on quality could be quite small!
Our Method
We got down to revisit Static Embeddings models, using modern techniques to coach them. Most of our gains come from using a contrastive learning loss function, as we’ll explain shortly. Optionally, we are able to get additional speed improvements by utilizing Matryoshka Representation Learning, which makes it possible to make use of truncated versions of the embedding vectors.
We’ll be using the Sentence Transformers library for training. For a more general overview on how this library could be used to coach embedding models, consider reading the Training and Finetuning Embedding Models with Sentence Transformers v3 blogpost or the Sentence Transformers Training Overview documentation.
Training Details
The target with these reimagined Static Embeddings is to experiment with modern embedding model finetuning techniques on these highly efficient embedding models. Particularly, unlike GLoVe and word2vec, we might be using:
-
Contrastive Learning: With most machine learning, you’re taking input $X$ and expect output $Y$, after which train a model such that $X$ fed through the model produces something near $Y$. For embedding models, we haven’t got $Y$: we do not know what a superb embedding could be beforehand.
As a substitute, with Contrastive Learning, we’ve multiple inputs $X_1$ and $X_2$, and a similarity. We feed each inputs through the model, after which we are able to contrast the 2 embeddings leading to a predicted similarity. We will then push the embeddings further apart if the true similarity is low, or pull the embeddings closer together if the true similarity is high.
-
Matryoshka Representation Learning (MRL): Matryoshka Embedding Models (blogpost) is a clever training approach that enables users to truncate embedding models to smaller dimensions at a minimal performance hit. It involves using the contrastive loss function not only with the normal-sized embedding, but additionally with truncated versions of them. Consequently, the model learns to store information primarily at the beginning of the embeddings.
Truncated embeddings might be faster with downstream applications, resembling retrieval, classification, and clustering.
For future research, we leave various other modern training approaches for improving data quality. See Next Steps for concrete ideas.
Training Requirements
As shown within the Training Overview documentation in Sentence Transformers, training consists of three to five components:
- Dataset
- Loss Function
- Training Arguments (Optional)
- Evaluator (Optional)
- Trainer
In the next sections, we’ll undergo our thought processes for every of those.
Model Inspiration
In our experience, embedding models are either used 1) exclusively for retrieval or 2) for each task under the sun (classification, clustering, semantic textual similarity, etc.). We got down to train certainly one of each.
For the retrieval model, there is just a limited amount of multilingual retrieval training data available, and hence we selected to go for an English-only model. In contrast, we decided to coach a multilingual general similarity model because multilingual data was much easier to accumulate for this task.
For these models, we would really like to make use of the StaticEmbedding module, which implements an efficient tokenize method that avoids padding, and an efficient forward method that takes care of computing and pooling embeddings. It’s so simple as using a torch EmbeddingBag, which is nothing greater than an efficient Embedding (i.e. a lookup table for embeddings) with mean pooling.
We will initialize it in a number of ways: StaticEmbedding.from_model2vec to load a Model2Vec model, StaticEmbedding.from_distillation to perform Model2Vec-style distillation, or initializing it with a Tokenizer and an embedding dimension to get random weights.
Based on our findings, the last option works best when fully training with a considerable amount of data. Matching common models like all-mpnet-base-v2 or bge-large-en-v1.5, we’re selecting an embedding dimensionality of 1024, i.e. our embedding vectors consist of 1024 values each.
English Retrieval
For the English Retrieval model, we depend on the google-bert/bert-base-uncased tokenizer. As such, initializing the model looks like this:
from sentence_transformers import SentenceTransformer
from sentence_transformers.models import StaticEmbedding
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
The primary entry within the modules list must implement tokenize, and the last one must produce pooled embeddings. Each is the case here, so we’re good to begin training this model.
Multilingual Similarity
For the Multilingual Similarity model, we as a substitute depend on the google-bert/bert-base-multilingual-uncased tokenizer, and that is the only thing we alter in our initialization code:
from sentence_transformers import SentenceTransformer
from sentence_transformers.models import StaticEmbedding
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-multilingual-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
Training Dataset Selection
Alongside dozens of Sentence Transformer models, the Sentence Transformers organization on Hugging Face also hosts 70+ datasets (on the time of writing):
Beyond that, many datasets have been tagged with sentence-transformers to mark that they are useful for training embedding models:
English Retrieval
For the English Retrieval datasets, we’re primarily searching for any dataset with:
- question-answer pairs, optionally with negatives (i.e. mistaken answers) as well, and
- no overlap with the BEIR benchmark, a.k.a. the Retrieval tab on MTEB. Our goal is to avoid training on these datasets so we are able to use MTEB as a 0-shot benchmark.
We chosen the next datasets:
Multilingual Similarity
For the Multilingual Similarity datasets, we aimed for datasets with:
- parallel sentences across languages, i.e. the identical text in multiple languages, or
- positive pairs, i.e. pairs with high similarity, optionally with negatives (i.e. low similarity).
We chosen the next datasets as they contain parallel sentences:
And these datasets as they contain positive pairs of some kind:
Code
Loading these datasets is relatively easy, e.g.:
from datasets import load_dataset, Dataset
gooaq_dataset = load_dataset("sentence-transformers/gooaq", split="train")
gooaq_dataset_dict = gooaq_dataset.train_test_split(test_size=10_000, seed=12)
gooaq_train_dataset: Dataset = gooaq_dataset_dict["train"]
gooaq_eval_dataset: Dataset = gooaq_dataset_dict["test"]
print(gooaq_train_dataset)
"""
Dataset({
features: ['question', 'answer'],
num_rows: 3002496
})
"""
print(gooaq_eval_dataset)
"""
Dataset({
features: ['question', 'answer'],
num_rows: 10000
})
"""
The gooaq dataset doesn’t have already got a train-eval split, so we are able to make one with train_test_split. Otherwise, we are able to just load a precomputed split with e.g. split="eval".
Note that train_test_split does mean that the dataset must be loaded into memory, whereas it’s otherwise just kept on disk. This increased memory is just not ideal when training, so it’s advisable to 1) load the information, 2) split it, and three) put it aside to disk with save_to_disk. Before training, you’ll be able to then use load_from_disk to load it again.
Loss Function Selection
Inside Sentence Transformers, your loss model must match your training data format. The Loss Overview is designed as an outline of which losses are compatible with which formats.
Particularly, we currently have the next formats in our data:
- (anchor, positive) pair, no label
- (anchor, positive, negative) triplet, no label
- (anchor, positive, negative_1, …, negative_n) tuples, no label
For these formats, we’ve some excellent selections:
-
MultipleNegativesRankingLoss(MNRL): Also often called in-batch negatives loss or InfoNCE loss, this loss has been used to coach modern embedding models for a handful of years. Briefly, the loss optimizes the next:Given an anchor (e.g. a matter), assign the best similarity to the corresponding positive (i.e. answer) out of all positives and negatives (e.g. all answers) within the batch.
If you happen to provide the optional negatives, they are going to only be used as extra options (also often called in-batch negatives) from which the model must pick the right positive. Inside reason, the harder this “picking” is, the stronger the model will change into. For this reason, higher batch sizes lead to more in-batch negatives, which then increase performance (to a degree).
-
CachedMultipleNegativesRankingLoss(CMNRL): That is an extension of MNRL that implements GradCache, an approach that enables for arbitrarily increasing the batch size without increasing the memory.This loss is advisable over MNRL unless you’ll be able to already fit a big enough batch size in memory with just MNRL. In that case, you should use MNRL to save lots of the 20% training speed cost that CMNRL adds.
-
GISTEmbedLoss(GIST): This can also be an extension of MNRL, it uses aguideSentence Transformer model to remove potential false negatives from the list of options that the model must “pick” the right positive from.False negatives can hurt performance, but hard true negatives (texts which are near correct, but not quite) will help performance, so this filtering is a superb line to walk.
Because these static embedding models are extremely small, it is feasible to suit our desired batch size of 2048 samples on our hardware: a single RTX 3090 with 24GB, so we need not use CMNRL.
Moreover, because we’re training such fast models, the guide from the GISTEmbedLoss would make the training much slower. For this reason, we have opted to make use of MultipleNegativesRankingLoss for our models.
If we were to try these experiments again, we might pick a bigger batch size, e.g. 16384 with CMNRL. If you happen to try, please allow us to understand how it goes!
Code
The usage is relatively easy:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import MultipleNegativesRankingLoss
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
loss = MultipleNegativesRankingLoss(model)
Matryoshka Representation Learning
Beyond regular loss functions, Sentence Transformers also implements a handful of Loss modifiers. These work on top of normal loss functions, but apply them in other ways to try to instil useful properties into the trained embedding model.
A really interesting one is the MatryoshkaLoss, which turns the trained model right into a Matryoshka Model. This enables users to truncate the output embeddings at a minimal lack of performance, meaning that retrieval or clustering could be sped up resulting from the smaller dimensionalities.
Code
The MatryoshkaLoss is applied on top of a traditional loss. It’s advisable to also include the traditional embedding dimensionality within the list of matryoshka_dims:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import MultipleNegativesRankingLoss, MatryoshkaLoss
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
base_loss = MultipleNegativesRankingLoss(model)
loss = MatryoshkaLoss(model, base_loss, matryoshka_dims=[1024, 768, 512, 256, 128, 64, 32])
Training Arguments Selection
Sentence Transformers supports a whole lot of training arguments, the Most worthy of which have been listed within the Training Overview > Training Arguments documentation.
We used the identical core training parameters to coach each models:
num_train_epochs: 1- We’ve sufficient data, should we wish to coach for more, then we are able to add more data as a substitute of coaching with the identical data multiple times.
per_device_train_batch_size/per_device_eval_batch_size: 2048- 2048 dimensions fit comfortably on our RTX 3090. Various papers (Xiao et al., Li et al.) show that even larger batch sizes still improve performance. For future versions, we are going to apply
CachedMultipleNegativesRankingLosswith a bigger batch size, e.g. 16384.
- 2048 dimensions fit comfortably on our RTX 3090. Various papers (Xiao et al., Li et al.) show that even larger batch sizes still improve performance. For future versions, we are going to apply
learning_rate: 2e-1- Note! That is much larger than with normal embedding model training, which frequently uses a loss around 2e-5.
warmup_ratio: 0.1- 0.1 or 10% is a reasonably standard warmup ratio to easily introduce the high learning rate to the model.
bf16: True- In case your GPU(s) support(s)
bf16– it tends to make sense to coach with it. Otherwise you should usefp16=Trueif that is supported as a substitute.
- In case your GPU(s) support(s)
batch_sampler:BatchSamplers.NO_DUPLICATES- All losses with in-batch negatives (resembling MNRL) profit from this batch sampler that avoids duplicates throughout the batch. Duplicates often lead to false negatives, weakening the trained model.
multi_dataset_batch_sampler:MultiDatasetBatchSamplers.PROPORTIONAL- While you’re training with multiple datasets, it is common that not all datasets are the identical size. When that happens, you’ll be able to either:
- Round Robin: sample the identical amount of batches from each dataset until one is exhausted. You will have an equal distribution of information, but not all data might be used.
- Proportional: sample each dataset until all are exhausted. You will use up all data, but you will not have an equal distribution of information. We selected this one as we’re not too concerned with a knowledge imbalance.
- While you’re training with multiple datasets, it is common that not all datasets are the identical size. When that happens, you’ll be able to either:
Beyond these core arguments, we also set a number of training arguments for tracking and debugging: eval_strategy, eval_steps, save_strategy, save_steps, save_total_limit, logging_steps, logging_first_step, and run_name.
Code
In the long run, we used these SentenceTransformerTrainingArguments for the 2 models:
run_name = "static-retrieval-mrl-en-v1"
args = SentenceTransformerTrainingArguments(
output_dir=f"models/{run_name}",
num_train_epochs=1,
per_device_train_batch_size=2048,
per_device_eval_batch_size=2048,
learning_rate=2e-1,
warmup_ratio=0.1,
fp16=False,
bf16=True,
batch_sampler=BatchSamplers.NO_DUPLICATES,
multi_dataset_batch_sampler=MultiDatasetBatchSamplers.PROPORTIONAL,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=2,
logging_steps=1000,
logging_first_step=True,
run_name=run_name,
)
Evaluator Selection
If we offer an evaluation dataset to the Sentence Transformer Trainer, then upon evaluation we are going to get an evaluation loss. This’ll be useful to trace whether we’re overfitting or not, but not so meaningful in terms of real downstream performance.
For this reason, Sentence Transformers moreover supports Evaluators. Unlike the training loss, these give qualitative metrics like NDCG, MAP, MRR for Information Retrieval, Spearman Correlation for Semantic Textual Similarity, or Triplet accuracy (variety of samples where similarity(anchor, positive) > similarity(anchor, negative)).
As a consequence of its simplicity, we might be using the NanoBEIREvaluator for the retrieval model. This evaluator runs Information Retrieval benchmarks on the NanoBEIR collection of datasets. This dataset is a subset of the much larger (and thus slower) BEIR benchmark, which is usually used because the Retrieval tab within the MTEB Leaderboard.
Code
Because all datasets are already pre-defined, we are able to load the evaluator with none arguments:
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import NanoBEIREvaluator
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
evaluator = NanoBEIREvaluator()
evaluator(model)
Hardware Details
We’re training these models on consumer-level hardware, specifically:
- GPU: RTX 3090
- CPU: i7-13700K
- RAM: 32GB
Overall Training Scripts
This section accommodates the ultimate training scripts for each models with all the previously described components (datasets, loss functions, training arguments, evaluator, trainer) combined.
English Retrieval
Click to expand
import random
import logging
from datasets import load_dataset, Dataset, DatasetDict
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
SentenceTransformerModelCardData,
)
from sentence_transformers.losses import MatryoshkaLoss, MultipleNegativesRankingLoss
from sentence_transformers.training_args import BatchSamplers, MultiDatasetBatchSamplers
from sentence_transformers.evaluation import NanoBEIREvaluator
from sentence_transformers.models.StaticEmbedding import StaticEmbedding
from transformers import AutoTokenizer
logging.basicConfig(
format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO
)
random.seed(12)
def load_train_eval_datasets():
"""
Either load the train and eval datasets from disk or load them from the datasets library & save them to disk.
Upon saving to disk, we quit() to be sure that the datasets are usually not loaded into memory before training.
"""
try:
train_dataset = DatasetDict.load_from_disk("datasets/train_dataset")
eval_dataset = DatasetDict.load_from_disk("datasets/eval_dataset")
return train_dataset, eval_dataset
except FileNotFoundError:
print("Loading gooaq dataset...")
gooaq_dataset = load_dataset("sentence-transformers/gooaq", split="train")
gooaq_dataset_dict = gooaq_dataset.train_test_split(test_size=10_000, seed=12)
gooaq_train_dataset: Dataset = gooaq_dataset_dict["train"]
gooaq_eval_dataset: Dataset = gooaq_dataset_dict["test"]
print("Loaded gooaq dataset.")
print("Loading msmarco dataset...")
msmarco_dataset = load_dataset("sentence-transformers/msmarco-co-condenser-margin-mse-sym-mnrl-mean-v1", "triplet", split="train")
msmarco_dataset_dict = msmarco_dataset.train_test_split(test_size=10_000, seed=12)
msmarco_train_dataset: Dataset = msmarco_dataset_dict["train"]
msmarco_eval_dataset: Dataset = msmarco_dataset_dict["test"]
print("Loaded msmarco dataset.")
print("Loading squad dataset...")
squad_dataset = load_dataset("sentence-transformers/squad", split="train")
squad_dataset_dict = squad_dataset.train_test_split(test_size=10_000, seed=12)
squad_train_dataset: Dataset = squad_dataset_dict["train"]
squad_eval_dataset: Dataset = squad_dataset_dict["test"]
print("Loaded squad dataset.")
print("Loading s2orc dataset...")
s2orc_dataset = load_dataset("sentence-transformers/s2orc", "title-abstract-pair", split="train[:100000]")
s2orc_dataset_dict = s2orc_dataset.train_test_split(test_size=10_000, seed=12)
s2orc_train_dataset: Dataset = s2orc_dataset_dict["train"]
s2orc_eval_dataset: Dataset = s2orc_dataset_dict["test"]
print("Loaded s2orc dataset.")
print("Loading allnli dataset...")
allnli_train_dataset = load_dataset("sentence-transformers/all-nli", "triplet", split="train")
allnli_eval_dataset = load_dataset("sentence-transformers/all-nli", "triplet", split="dev")
print("Loaded allnli dataset.")
print("Loading paq dataset...")
paq_dataset = load_dataset("sentence-transformers/paq", split="train")
paq_dataset_dict = paq_dataset.train_test_split(test_size=10_000, seed=12)
paq_train_dataset: Dataset = paq_dataset_dict["train"]
paq_eval_dataset: Dataset = paq_dataset_dict["test"]
print("Loaded paq dataset.")
print("Loading trivia_qa dataset...")
trivia_qa = load_dataset("sentence-transformers/trivia-qa", split="train")
trivia_qa_dataset_dict = trivia_qa.train_test_split(test_size=5_000, seed=12)
trivia_qa_train_dataset: Dataset = trivia_qa_dataset_dict["train"]
trivia_qa_eval_dataset: Dataset = trivia_qa_dataset_dict["test"]
print("Loaded trivia_qa dataset.")
print("Loading msmarco_10m dataset...")
msmarco_10m_dataset = load_dataset("bclavie/msmarco-10m-triplets", split="train")
msmarco_10m_dataset_dict = msmarco_10m_dataset.train_test_split(test_size=10_000, seed=12)
msmarco_10m_train_dataset: Dataset = msmarco_10m_dataset_dict["train"]
msmarco_10m_eval_dataset: Dataset = msmarco_10m_dataset_dict["test"]
print("Loaded msmarco_10m dataset.")
print("Loading swim_ir dataset...")
swim_ir_dataset = load_dataset("nthakur/swim-ir-monolingual", "en", split="train").select_columns(["query", "text"])
swim_ir_dataset_dict = swim_ir_dataset.train_test_split(test_size=10_000, seed=12)
swim_ir_train_dataset: Dataset = swim_ir_dataset_dict["train"]
swim_ir_eval_dataset: Dataset = swim_ir_dataset_dict["test"]
print("Loaded swim_ir dataset.")
print("Loading pubmedqa dataset...")
pubmedqa_dataset = load_dataset("sentence-transformers/pubmedqa", "triplet-20", split="train")
pubmedqa_dataset_dict = pubmedqa_dataset.train_test_split(test_size=100, seed=12)
pubmedqa_train_dataset: Dataset = pubmedqa_dataset_dict["train"]
pubmedqa_eval_dataset: Dataset = pubmedqa_dataset_dict["test"]
print("Loaded pubmedqa dataset.")
print("Loading miracl dataset...")
miracl_dataset = load_dataset("sentence-transformers/miracl", "en-triplet-all", split="train")
miracl_dataset_dict = miracl_dataset.train_test_split(test_size=10_000, seed=12)
miracl_train_dataset: Dataset = miracl_dataset_dict["train"]
miracl_eval_dataset: Dataset = miracl_dataset_dict["test"]
print("Loaded miracl dataset.")
print("Loading mldr dataset...")
mldr_dataset = load_dataset("sentence-transformers/mldr", "en-triplet-all", split="train")
mldr_dataset_dict = mldr_dataset.train_test_split(test_size=10_000, seed=12)
mldr_train_dataset: Dataset = mldr_dataset_dict["train"]
mldr_eval_dataset: Dataset = mldr_dataset_dict["test"]
print("Loaded mldr dataset.")
print("Loading mr_tydi dataset...")
mr_tydi_dataset = load_dataset("sentence-transformers/mr-tydi", "en-triplet-all", split="train")
mr_tydi_dataset_dict = mr_tydi_dataset.train_test_split(test_size=10_000, seed=12)
mr_tydi_train_dataset: Dataset = mr_tydi_dataset_dict["train"]
mr_tydi_eval_dataset: Dataset = mr_tydi_dataset_dict["test"]
print("Loaded mr_tydi dataset.")
train_dataset = DatasetDict({
"gooaq": gooaq_train_dataset,
"msmarco": msmarco_train_dataset,
"squad": squad_train_dataset,
"s2orc": s2orc_train_dataset,
"allnli": allnli_train_dataset,
"paq": paq_train_dataset,
"trivia_qa": trivia_qa_train_dataset,
"msmarco_10m": msmarco_10m_train_dataset,
"swim_ir": swim_ir_train_dataset,
"pubmedqa": pubmedqa_train_dataset,
"miracl": miracl_train_dataset,
"mldr": mldr_train_dataset,
"mr_tydi": mr_tydi_train_dataset,
})
eval_dataset = DatasetDict({
"gooaq": gooaq_eval_dataset,
"msmarco": msmarco_eval_dataset,
"squad": squad_eval_dataset,
"s2orc": s2orc_eval_dataset,
"allnli": allnli_eval_dataset,
"paq": paq_eval_dataset,
"trivia_qa": trivia_qa_eval_dataset,
"msmarco_10m": msmarco_10m_eval_dataset,
"swim_ir": swim_ir_eval_dataset,
"pubmedqa": pubmedqa_eval_dataset,
"miracl": miracl_eval_dataset,
"mldr": mldr_eval_dataset,
"mr_tydi": mr_tydi_eval_dataset,
})
train_dataset.save_to_disk("datasets/train_dataset")
eval_dataset.save_to_disk("datasets/eval_dataset")
quit()
def foremost():
static_embedding = StaticEmbedding(AutoTokenizer.from_pretrained("google-bert/bert-base-uncased"), embedding_dim=1024)
model = SentenceTransformer(
modules=[static_embedding],
model_card_data=SentenceTransformerModelCardData(
language="en",
license="apache-2.0",
model_name="Static Embeddings with BERT uncased tokenizer finetuned on various datasets",
),
)
train_dataset, eval_dataset = load_train_eval_datasets()
print(train_dataset)
loss = MultipleNegativesRankingLoss(model)
loss = MatryoshkaLoss(model, loss, matryoshka_dims=[32, 64, 128, 256, 512, 1024])
run_name = "static-retrieval-mrl-en-v1"
args = SentenceTransformerTrainingArguments(
output_dir=f"models/{run_name}",
num_train_epochs=1,
per_device_train_batch_size=2048,
per_device_eval_batch_size=2048,
learning_rate=2e-1,
warmup_ratio=0.1,
fp16=False,
bf16=True,
batch_sampler=BatchSamplers.NO_DUPLICATES,
multi_dataset_batch_sampler=MultiDatasetBatchSamplers.PROPORTIONAL,
eval_strategy="steps",
eval_steps=250,
save_strategy="steps",
save_steps=250,
save_total_limit=2,
logging_steps=250,
logging_first_step=True,
run_name=run_name,
)
evaluator = NanoBEIREvaluator()
evaluator(model)
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=evaluator,
)
trainer.train()
evaluator(model)
model.save_pretrained(f"models/{run_name}/final")
model.push_to_hub(run_name, private=True)
if __name__ == "__main__":
foremost()
This script produced sentence-transformers/static-retrieval-mrl-en-v1 after 17.8 hours of coaching. In total, it consumed 2.6 kWh of energy and emitted 1kg of CO2. That’s roughly such as the quantity of CO2 a median person exhales per day.
See our Weights and Biases report for the training and evaluation metrics collected during training.
Multilingual Similarity
Click to expand
import random
import logging
from datasets import load_dataset, Dataset, DatasetDict
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
SentenceTransformerModelCardData,
)
from sentence_transformers.losses import MatryoshkaLoss, MultipleNegativesRankingLoss
from sentence_transformers.training_args import BatchSamplers, MultiDatasetBatchSamplers
from sentence_transformers.models.StaticEmbedding import StaticEmbedding
from transformers import AutoTokenizer
logging.basicConfig(
format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO
)
random.seed(12)
def load_train_eval_datasets():
"""
Either load the train and eval datasets from disk or load them from the datasets library & save them to disk.
Upon saving to disk, we quit() to be sure that the datasets are usually not loaded into memory before training.
"""
try:
train_dataset = DatasetDict.load_from_disk("datasets/train_dataset")
eval_dataset = DatasetDict.load_from_disk("datasets/eval_dataset")
return train_dataset, eval_dataset
except FileNotFoundError:
print("Loading wikititles dataset...")
wikititles_dataset = load_dataset("sentence-transformers/parallel-sentences-wikititles", split="train")
wikititles_dataset_dict = wikititles_dataset.train_test_split(test_size=10_000, seed=12)
wikititles_train_dataset: Dataset = wikititles_dataset_dict["train"]
wikititles_eval_dataset: Dataset = wikititles_dataset_dict["test"]
print("Loaded wikititles dataset.")
print("Loading tatoeba dataset...")
tatoeba_dataset = load_dataset("sentence-transformers/parallel-sentences-tatoeba", "all", split="train")
tatoeba_dataset_dict = tatoeba_dataset.train_test_split(test_size=10_000, seed=12)
tatoeba_train_dataset: Dataset = tatoeba_dataset_dict["train"]
tatoeba_eval_dataset: Dataset = tatoeba_dataset_dict["test"]
print("Loaded tatoeba dataset.")
print("Loading talks dataset...")
talks_dataset = load_dataset("sentence-transformers/parallel-sentences-talks", "all", split="train")
talks_dataset_dict = talks_dataset.train_test_split(test_size=10_000, seed=12)
talks_train_dataset: Dataset = talks_dataset_dict["train"]
talks_eval_dataset: Dataset = talks_dataset_dict["test"]
print("Loaded talks dataset.")
print("Loading europarl dataset...")
europarl_dataset = load_dataset("sentence-transformers/parallel-sentences-europarl", "all", split="train[:5000000]")
europarl_dataset_dict = europarl_dataset.train_test_split(test_size=10_000, seed=12)
europarl_train_dataset: Dataset = europarl_dataset_dict["train"]
europarl_eval_dataset: Dataset = europarl_dataset_dict["test"]
print("Loaded europarl dataset.")
print("Loading global voices dataset...")
global_voices_dataset = load_dataset("sentence-transformers/parallel-sentences-global-voices", "all", split="train")
global_voices_dataset_dict = global_voices_dataset.train_test_split(test_size=10_000, seed=12)
global_voices_train_dataset: Dataset = global_voices_dataset_dict["train"]
global_voices_eval_dataset: Dataset = global_voices_dataset_dict["test"]
print("Loaded global voices dataset.")
print("Loading jw300 dataset...")
jw300_dataset = load_dataset("sentence-transformers/parallel-sentences-jw300", "all", split="train")
jw300_dataset_dict = jw300_dataset.train_test_split(test_size=10_000, seed=12)
jw300_train_dataset: Dataset = jw300_dataset_dict["train"]
jw300_eval_dataset: Dataset = jw300_dataset_dict["test"]
print("Loaded jw300 dataset.")
print("Loading muse dataset...")
muse_dataset = load_dataset("sentence-transformers/parallel-sentences-muse", split="train")
muse_dataset_dict = muse_dataset.train_test_split(test_size=10_000, seed=12)
muse_train_dataset: Dataset = muse_dataset_dict["train"]
muse_eval_dataset: Dataset = muse_dataset_dict["test"]
print("Loaded muse dataset.")
print("Loading wikimatrix dataset...")
wikimatrix_dataset = load_dataset("sentence-transformers/parallel-sentences-wikimatrix", "all", split="train")
wikimatrix_dataset_dict = wikimatrix_dataset.train_test_split(test_size=10_000, seed=12)
wikimatrix_train_dataset: Dataset = wikimatrix_dataset_dict["train"]
wikimatrix_eval_dataset: Dataset = wikimatrix_dataset_dict["test"]
print("Loaded wikimatrix dataset.")
print("Loading opensubtitles dataset...")
opensubtitles_dataset = load_dataset("sentence-transformers/parallel-sentences-opensubtitles", "all", split="train[:5000000]")
opensubtitles_dataset_dict = opensubtitles_dataset.train_test_split(test_size=10_000, seed=12)
opensubtitles_train_dataset: Dataset = opensubtitles_dataset_dict["train"]
opensubtitles_eval_dataset: Dataset = opensubtitles_dataset_dict["test"]
print("Loaded opensubtitles dataset.")
print("Loading stackexchange dataset...")
stackexchange_dataset = load_dataset("sentence-transformers/stackexchange-duplicates", "post-post-pair", split="train")
stackexchange_dataset_dict = stackexchange_dataset.train_test_split(test_size=10_000, seed=12)
stackexchange_train_dataset: Dataset = stackexchange_dataset_dict["train"]
stackexchange_eval_dataset: Dataset = stackexchange_dataset_dict["test"]
print("Loaded stackexchange dataset.")
print("Loading quora dataset...")
quora_dataset = load_dataset("sentence-transformers/quora-duplicates", "triplet", split="train")
quora_dataset_dict = quora_dataset.train_test_split(test_size=10_000, seed=12)
quora_train_dataset: Dataset = quora_dataset_dict["train"]
quora_eval_dataset: Dataset = quora_dataset_dict["test"]
print("Loaded quora dataset.")
print("Loading wikianswers duplicates dataset...")
wikianswers_duplicates_dataset = load_dataset("sentence-transformers/wikianswers-duplicates", split="train[:10000000]")
wikianswers_duplicates_dict = wikianswers_duplicates_dataset.train_test_split(test_size=10_000, seed=12)
wikianswers_duplicates_train_dataset: Dataset = wikianswers_duplicates_dict["train"]
wikianswers_duplicates_eval_dataset: Dataset = wikianswers_duplicates_dict["test"]
print("Loaded wikianswers duplicates dataset.")
print("Loading all nli dataset...")
all_nli_train_dataset = load_dataset("sentence-transformers/all-nli", "triplet", split="train")
all_nli_eval_dataset = load_dataset("sentence-transformers/all-nli", "triplet", split="dev")
print("Loaded all nli dataset.")
print("Loading easy wiki dataset...")
simple_wiki_dataset = load_dataset("sentence-transformers/simple-wiki", split="train")
simple_wiki_dataset_dict = simple_wiki_dataset.train_test_split(test_size=10_000, seed=12)
simple_wiki_train_dataset: Dataset = simple_wiki_dataset_dict["train"]
simple_wiki_eval_dataset: Dataset = simple_wiki_dataset_dict["test"]
print("Loaded easy wiki dataset.")
print("Loading altlex dataset...")
altlex_dataset = load_dataset("sentence-transformers/altlex", split="train")
altlex_dataset_dict = altlex_dataset.train_test_split(test_size=10_000, seed=12)
altlex_train_dataset: Dataset = altlex_dataset_dict["train"]
altlex_eval_dataset: Dataset = altlex_dataset_dict["test"]
print("Loaded altlex dataset.")
print("Loading flickr30k captions dataset...")
flickr30k_captions_dataset = load_dataset("sentence-transformers/flickr30k-captions", split="train")
flickr30k_captions_dataset_dict = flickr30k_captions_dataset.train_test_split(test_size=10_000, seed=12)
flickr30k_captions_train_dataset: Dataset = flickr30k_captions_dataset_dict["train"]
flickr30k_captions_eval_dataset: Dataset = flickr30k_captions_dataset_dict["test"]
print("Loaded flickr30k captions dataset.")
print("Loading coco captions dataset...")
coco_captions_dataset = load_dataset("sentence-transformers/coco-captions", split="train")
coco_captions_dataset_dict = coco_captions_dataset.train_test_split(test_size=10_000, seed=12)
coco_captions_train_dataset: Dataset = coco_captions_dataset_dict["train"]
coco_captions_eval_dataset: Dataset = coco_captions_dataset_dict["test"]
print("Loaded coco captions dataset.")
print("Loading nli for simcse dataset...")
nli_for_simcse_dataset = load_dataset("sentence-transformers/nli-for-simcse", "triplet", split="train")
nli_for_simcse_dataset_dict = nli_for_simcse_dataset.train_test_split(test_size=10_000, seed=12)
nli_for_simcse_train_dataset: Dataset = nli_for_simcse_dataset_dict["train"]
nli_for_simcse_eval_dataset: Dataset = nli_for_simcse_dataset_dict["test"]
print("Loaded nli for simcse dataset.")
print("Loading negation dataset...")
negation_dataset = load_dataset("jinaai/negation-dataset", split="train")
negation_dataset_dict = negation_dataset.train_test_split(test_size=100, seed=12)
negation_train_dataset: Dataset = negation_dataset_dict["train"]
negation_eval_dataset: Dataset = negation_dataset_dict["test"]
print("Loaded negation dataset.")
train_dataset = DatasetDict({
"wikititles": wikititles_train_dataset,
"tatoeba": tatoeba_train_dataset,
"talks": talks_train_dataset,
"europarl": europarl_train_dataset,
"global_voices": global_voices_train_dataset,
"jw300": jw300_train_dataset,
"muse": muse_train_dataset,
"wikimatrix": wikimatrix_train_dataset,
"opensubtitles": opensubtitles_train_dataset,
"stackexchange": stackexchange_train_dataset,
"quora": quora_train_dataset,
"wikianswers_duplicates": wikianswers_duplicates_train_dataset,
"all_nli": all_nli_train_dataset,
"simple_wiki": simple_wiki_train_dataset,
"altlex": altlex_train_dataset,
"flickr30k_captions": flickr30k_captions_train_dataset,
"coco_captions": coco_captions_train_dataset,
"nli_for_simcse": nli_for_simcse_train_dataset,
"negation": negation_train_dataset,
})
eval_dataset = DatasetDict({
"wikititles": wikititles_eval_dataset,
"tatoeba": tatoeba_eval_dataset,
"talks": talks_eval_dataset,
"europarl": europarl_eval_dataset,
"global_voices": global_voices_eval_dataset,
"jw300": jw300_eval_dataset,
"muse": muse_eval_dataset,
"wikimatrix": wikimatrix_eval_dataset,
"opensubtitles": opensubtitles_eval_dataset,
"stackexchange": stackexchange_eval_dataset,
"quora": quora_eval_dataset,
"wikianswers_duplicates": wikianswers_duplicates_eval_dataset,
"all_nli": all_nli_eval_dataset,
"simple_wiki": simple_wiki_eval_dataset,
"altlex": altlex_eval_dataset,
"flickr30k_captions": flickr30k_captions_eval_dataset,
"coco_captions": coco_captions_eval_dataset,
"nli_for_simcse": nli_for_simcse_eval_dataset,
"negation": negation_eval_dataset,
})
train_dataset.save_to_disk("datasets/train_dataset")
eval_dataset.save_to_disk("datasets/eval_dataset")
quit()
def foremost():
static_embedding = StaticEmbedding(AutoTokenizer.from_pretrained("google-bert/bert-base-multilingual-uncased"), embedding_dim=1024)
model = SentenceTransformer(
modules=[static_embedding],
model_card_data=SentenceTransformerModelCardData(
license="apache-2.0",
model_name="Static Embeddings with BERT Multilingual uncased tokenizer finetuned on various datasets",
),
)
train_dataset, eval_dataset = load_train_eval_datasets()
print(train_dataset)
loss = MultipleNegativesRankingLoss(model)
loss = MatryoshkaLoss(model, loss, matryoshka_dims=[32, 64, 128, 256, 512, 1024])
run_name = "static-similarity-mrl-multilingual-v1"
args = SentenceTransformerTrainingArguments(
output_dir=f"models/{run_name}",
num_train_epochs=1,
per_device_train_batch_size=2048,
per_device_eval_batch_size=2048,
learning_rate=2e-1,
warmup_ratio=0.1,
fp16=False,
bf16=True,
batch_sampler=BatchSamplers.NO_DUPLICATES,
multi_dataset_batch_sampler=MultiDatasetBatchSamplers.PROPORTIONAL,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=2,
logging_steps=1000,
logging_first_step=True,
run_name=run_name,
)
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
)
trainer.train()
model.save_pretrained(f"models/{run_name}/final")
model.push_to_hub(run_name, private=True)
if __name__ == "__main__":
foremost()
This script produced sentence-transformers/static-similarity-mrl-multilingual-v1 after 3.1 hours of coaching. In total, it consumed 0.5 kWh of energy and emitted 0.2kg of CO2. That’s roughly 20% of the CO2 that a median person exhales per day.
See our Weights and Biases report for the training and evaluation losses collected during training.
Usage
The usage of those models may be very straightforward, equivalent to the traditional Sentence Transformers flow:
English Retrieval
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-retrieval-mrl-en-v1", device="cpu")
sentences = [
'Gadofosveset-enhanced MR angiography of carotid arteries: does steady-state imaging improve accuracy of first-pass imaging?',
'To evaluate the diagnostic accuracy of gadofosveset-enhanced magnetic resonance (MR) angiography in the assessment of carotid artery stenosis, with digital subtraction angiography (DSA) as the reference standard, and to determine the value of reading first-pass, steady-state, and "combined" (first-pass plus steady-state) MR angiograms.',
'In a longitudinal study we investigated in vivo alterations of CVO during neuroinflammation, applying Gadofluorine M- (Gf) enhanced magnetic resonance imaging (MRI) in experimental autoimmune encephalomyelitis, an animal model of multiple sclerosis. SJL/J mice were monitored by Gadopentate dimeglumine- (Gd-DTPA) and Gf-enhanced MRI after adoptive transfer of proteolipid-protein-specific T cells. Mean Gf intensity ratios were calculated individually for different CVO and correlated to the clinical disease course. Subsequently, the tissue distribution of fluorescence-labeled Gf as well as the extent of cellular inflammation was assessed in corresponding histological slices.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings[0], embeddings[1:])
print(similarities)
The upcoming Performance > English Retrieval section will show that these results are quite solid, inside 15% of commonly used Transformer-based encoder models like all-mpnet-base-v2.
Multilingual Similarity
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-similarity-mrl-multilingual-v1", device="cpu")
sentences = [
'It is known for its dry red chili powder.',
'It is popular for dried red chili powder.',
'These monsters will move in large groups.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
This model only loses about 8% of performance in comparison with the favored but much slower multilingual-e5-small, as shown within the upcoming Performance > Multilingual Similarity section.
Matryoshka Dimensionality Truncation
To cut back the dimensionality of your calculated embeddings, you’ll be able to simply pass the truncate_dim parameter. This works for all Sentence Transformer models.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"sentence-transformers/static-retrieval-mrl-en-v1",
device="cpu",
truncate_dim=256,
)
sentences = [
'Gadofosveset-enhanced MR angiography of carotid arteries: does steady-state imaging improve accuracy of first-pass imaging?',
'To evaluate the diagnostic accuracy of gadofosveset-enhanced magnetic resonance (MR) angiography in the assessment of carotid artery stenosis, with digital subtraction angiography (DSA) as the reference standard, and to determine the value of reading first-pass, steady-state, and "combined" (first-pass plus steady-state) MR angiograms.',
'In a longitudinal study we investigated in vivo alterations of CVO during neuroinflammation, applying Gadofluorine M- (Gf) enhanced magnetic resonance imaging (MRI) in experimental autoimmune encephalomyelitis, an animal model of multiple sclerosis. SJL/J mice were monitored by Gadopentate dimeglumine- (Gd-DTPA) and Gf-enhanced MRI after adoptive transfer of proteolipid-protein-specific T cells. Mean Gf intensity ratios were calculated individually for different CVO and correlated to the clinical disease course. Subsequently, the tissue distribution of fluorescence-labeled Gf as well as the extent of cellular inflammation was assessed in corresponding histological slices.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings[0], embeddings[1:])
print(similarities)
Third Party libraries
This model also works out of the box in various third party libraries, for instance LangChain, LlamaIndex, Haystack, and txtai.
LangChain
from langchain_huggingface import HuggingFaceEmbeddings
model_name = "sentence-transformers/static-retrieval-mrl-en-v1"
model_kwargs = {'device': 'cpu'}
model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
LlamaIndex
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model_name = "sentence-transformers/static-retrieval-mrl-en-v1"
device = "cpu"
embed_model = HuggingFaceEmbedding(
model_name=model_name,
device=device,
)
Settings.embed_model = embed_model
Haystack
from haystack.components.embedders import (
SentenceTransformersDocumentEmbedder,
SentenceTransformersTextEmbedder,
)
model_name = "sentence-transformers/static-retrieval-mrl-en-v1"
device = "cpu"
document_embedder = SentenceTransformersDocumentEmbedder(
model=model_name,
device=device,
)
text_embedder = SentenceTransformersTextEmbedder(
model=model_name,
device=device,
)
txtai
from txtai import Embeddings
model_name = "sentence-transformers/static-retrieval-mrl-en-v1"
embeddings = Embeddings(path=model_name)
Performance
English Retrieval
After training, we have evaluated the ultimate model sentence-transformers/static-retrieval-mrl-en-v1 on NanoBEIR (normal dimensionality and with Matryoshka dimensions) in addition to on BEIR.
NanoBEIR
We have evaluated sentence-transformers/static-retrieval-mrl-en-v1 on NanoBEIR and plotted it against the inference speed computed on our hardware. For the inference speed tests, we calculated the variety of computed query embeddings of the GooAQ dataset per second, either on CPU or GPU.
We evaluate against 3 forms of models:
-
Attention-based dense embedding models, e.g. traditional Sentence Transformer models like
all-mpnet-base-v2,bge-base-en-v1.5, andgte-large-en-v1.5. -
Static Embedding-based models, e.g.
static-retrieval-mrl-en-v1,potion-base-8M,M2V_base_output, andglove.6B.300d. -
Sparse bag-of-words model, BM25, often a powerful baseline.
Click to expand BM25 implementation details
We relied on the highly efficient bm25s implementation, using
model.get_scores()on tokens after tokenization and stemming with the EnglishPyStemmer.
NOTE: Most of the attention-based dense embedding models are finetuned on the training splits of the (Nano)BEIR evaluation datasets. This provides the models an unfair advantage on this benchmark and can lead to lower downstream performance on real retrieval tasks.
static-retrieval-mrl-en-v1 is purposefully not trained on any of those datasets.
Click to see a table with all values from the subsequent 2 Figures
| Model | NanoBEIR NDCG@10 | CPU (sentences per second) | GPU (sentences per second) |
|---|---|---|---|
| zeta-alpha-ai/Zeta-Alpha-E5-Mistral | 0.6860 | 0.00* | 0.00* |
| Alibaba-NLP/gte-large-en-v1.5 | 0.6808 | 56.01 | 965.95 |
| Salesforce/SFR-Embedding-Mistral | 0.6800 | 0.00* | 0.00* |
| mixedbread-ai/mxbai-embed-large-v1 | 0.6567 | 79.83 | 1376.80 |
| BAAI/bge-large-en-v1.5 | 0.6592 | 80.94 | 1315.03 |
| intfloat/e5-mistral-7b-instruct | 0.6530 | 0.00* | 0.00* |
| Alibaba-NLP/gte-base-en-v1.5 | 0.6411 | 197.85 | 3142.94 |
| BAAI/bge-base-en-v1.5 | 0.6376 | 264.83 | 4363.04 |
| BAAI/bge-small-en-v1.5 | 0.6267 | 888.46 | 10159.97 |
| nomic-ai/nomic-embed-text-v1.5 | 0.6179 | 86.86 | 2843.03 |
| jinaai/jina-embeddings-v3 | 0.6174 | 0.55 | 3377.56 |
| BAAI/bge-m3 | 0.6054 | 80.63 | 1434.82 |
| sentence-transformers/all-mpnet-base-v2 | 0.5757 | 270.40 | 4043.13 |
| TaylorAI/gte-tiny | 0.5692 | 1752.26 | 17215.15 |
| sentence-transformers/all-MiniLM-L6-v2 | 0.5623 | 1739.31 | 16942.46 |
| mixedbread-ai/mxbai-embed-xsmall-v1 | 0.5557 | 1749.42 | 16773.76 |
| sentence-transformers/all-MiniLM-L12-v2 | 0.5533 | 909.72 | 9915.69 |
| sentence-transformers/static-retrieval-mrl-en-v1 | 0.5032 | 107419.51 | 97171.47 |
| bm25 | 0.4518 | 49706.77 | 49706.77 |
| minishlab/potion-base-8M | 0.4421 | 124029.91 | 122384.10 |
| minishlab/potion-base-4M | 0.4225 | 123082.88 | 123612.54 |
| minishlab/M2V_base_glove | 0.4077 | 142173.77 | 146154.73 |
| minishlab/M2V_base_glove_subword | 0.3914 | 127426.83 | 131412.56 |
| minishlab/M2V_base_output | 0.3851 | 84191.93 | 85738.36 |
| minishlab/potion-base-2M | 0.3666 | 128994.27 | 122358.16 |
| sentence-transformers/glove.6B.300d | 0.3293 | 76519.74 | 62782.23 |
| sentence-transformers/glove.840B.300d | 0.2899 | 86348.98 | 75350.36 |
*: For the 7B LLMs, we didn’t do inference experiments as their inference speed could be indistinguishable from 0 within the Figures.- We performed experiments to find out the optimal batch size for every model.
GPU
CPU

We will draw some notable conclusions from these figures:
static-retrieval-mrl-en-v1outperforms all other Static Embedding models, like GloVe or Model2Vec.static-retrieval-mrl-en-v1is the one Static Embedding model to outperform BM25.static-retrieval-mrl-en-v1is- 87.4% as performant because the commonly used
all-mpnet-base-v2, - 24x faster on GPU,
- 397x faster on CPU.
- 87.4% as performant because the commonly used
static-retrieval-mrl-en-v1is quicker on CPU than on GPU: This model can run extraordinarily quickly in all places, including consumer-grade PCs, tiny servers, phones, or in-browser.
Matryoshka Evaluation
Moreover, we experimented with the outcomes on NanoBEIR performance once we performed Matryoshka-style dimensionality reduction by truncating the output embeddings to a lower dimensionality.

These findings show that reducing the dimensionality by e.g. 2x only has a 1.47% reduction in performance (0.5031 NDCG@10 vs 0.4957 NDCG@10), while realistically leading to a 2x speedup in retrieval speed.
Multilingual Similarity
We have moreover evaluated the ultimate sentence-transformers/static-similarity-mrl-multilingual-v1 model on 5 languages which have a whole lot of benchmarks across various tasks on MTEB.
We would like to reiterate that this model is just not intended for retrieval use cases. As a substitute, we evaluate on Semantic Textual Similarity (STS), Classification, and Pair Classification. We compare against the wonderful and small multilingual-e5-small model.

Across all measured languages, static-similarity-mrl-multilingual-v1 reaches a median 92.3% for STS, 95.52% for Pair Classification, and 86.52% for Classification relative to multilingual-e5-small.

To make up for this performance reduction, static-similarity-mrl-multilingual-v1 is roughly ~125x faster on CPU and ~10x faster on GPU devices than multilingual-e5-small. As a consequence of the super-linear nature of attention models, versus the linear nature of static embedding models, the speedup will only grow larger because the variety of tokens to encode increases.
Matryoshka Evaluation
Lastly, we experimented with the impacts on English STS on MTEB performance once we did Matryoshka-style dimensionality reduction by truncating the output embeddings to a lower dimensionality.

As you’ll be able to see, you’ll be able to easily reduce the dimensionality by 2x or 4x with minor (0.15% or 0.56%) performance hits. If the speed of your downstream task or your storage costs are a bottleneck, this could can help you alleviate a few of those concerns.
Conclusion
This blogpost described all the steps that we undertook from ideation to finished models, along with details regarding usage and evaluation of the 2 resulting models: static-retrieval-mrl-en-v1 and static-similarity-mrl-multilingual-v1.
The evaluations show that:
- Static Embedding-based models can exceed 85% of the performance of common attention-based dense models,
- Static Embedding-based models are realistically 10x to 25x faster on GPUs and 100x to 400x faster on CPUs than common efficient alternatives like all-mpnet-base-v2 and multilingual-e5-small. This speedup only grows larger with longer texts.
- Training with a Matryoshka Loss allows significant preservation of downstream performance:
Must you need an efficient CPU-only dense embedding model in your retrieval or similarity tasks, then static-retrieval-mrl-en-v1 and static-similarity-mrl-multilingual-v1 might be extremely performant solutions at minimal costs that get surprisingly near the attention-based dense models.
Next Steps
Try it out! If you happen to already use a Sentence Transformer model somewhere, be at liberty to swap it out for static-retrieval-mrl-en-v1 or static-similarity-mrl-multilingual-v1. Or, higher yet: train your personal models on data that’s representative for the duty and language of your interest.
Moreover, some questions remain concerning the trained models:
-
Because Static Embedding-based models aren’t bottlenecked by positional embeddings or superlinear time complexity, they will have arbitrarily high maximum sequence lengths. Nevertheless, sooner or later the law of huge numbers is prone to “normalize” all embeddings for really long documents, such that they don’t seem to be useful anymore.
More experiments are required to find out what a superb cutoff point is. For now, we leave the utmost sequence length, chunking, etc. to the user.
Moreover, there are quite a number of possible extensions which are prone to improve the performance of this model, which we happily leave to other model authors. We’re also open to collaborations:
- Hard Negatives Mining: Seek for similar, but not quite relevant, texts to enhance training data difficulty.
- Model Souping: Combining weights from multiple models trained in the identical way with different seeds or data distributions.
- Curriculum Learning: Train on examples of accelerating difficulties.
- Guided False In-Batch Negatives Filtering: Exclude false negatives via an efficient pre-trained embedding model.
- Seed Optimization for the Random Weight Initialization: Train the primary steps with various seeds to seek out one with a useful weight initialization.
- Tokenizer Retraining: Retrain a tokenizer with modern texts and learnings.
- Gradient Caching: Applying GradCache via
CachedMultipleNegativesRankingLossallows for larger batches, which frequently lead to superior performance. - Model Distillation: Somewhat than training exclusively using supervised training data, we may feed unsupervised data through a bigger embedding model and distil those embeddings into the static embedding-based student model.
Acknowledgements
I would really like to thank Stéphan Tulkens and Thomas van Dongen of The Minish Lab for bringing Static Embedding models to my attention via their Model2Vec work. Moreover, I would really like to thank Vaibhav Srivastav and Pedro Cuenca for his or her assistance with this blogpost, and Antoine Chaffin for brainstorming the discharge checkpoints.
Lastly, an enormous due to all researchers working on embedding models, datasets, and open source Python packages. You strengthen the industry, and I construct in your shoulders. At some point, I hope you construct on mine.