
The previous couple of months have been an exciting time for the Gemma family of open models. We introduced Gemma 3 and Gemma 3 QAT, delivering state-of-the-art performance for single cloud and desktop accelerators. Then, we announced the total release of Gemma 3n, a mobile-first architecture bringing powerful, real-time multimodal AI on to edge devices. Our goal has been to offer useful tools for developers to construct with AI, and we proceed to be amazed by the colourful Gemmaverse you’re helping create, celebrating together as downloads surpassed 200 million last week.
Today, we’re adding a brand new, highly specialized tool to the Gemma 3 toolkit: Gemma 3 270M, a compact, 270-million parameter model designed from the bottom up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
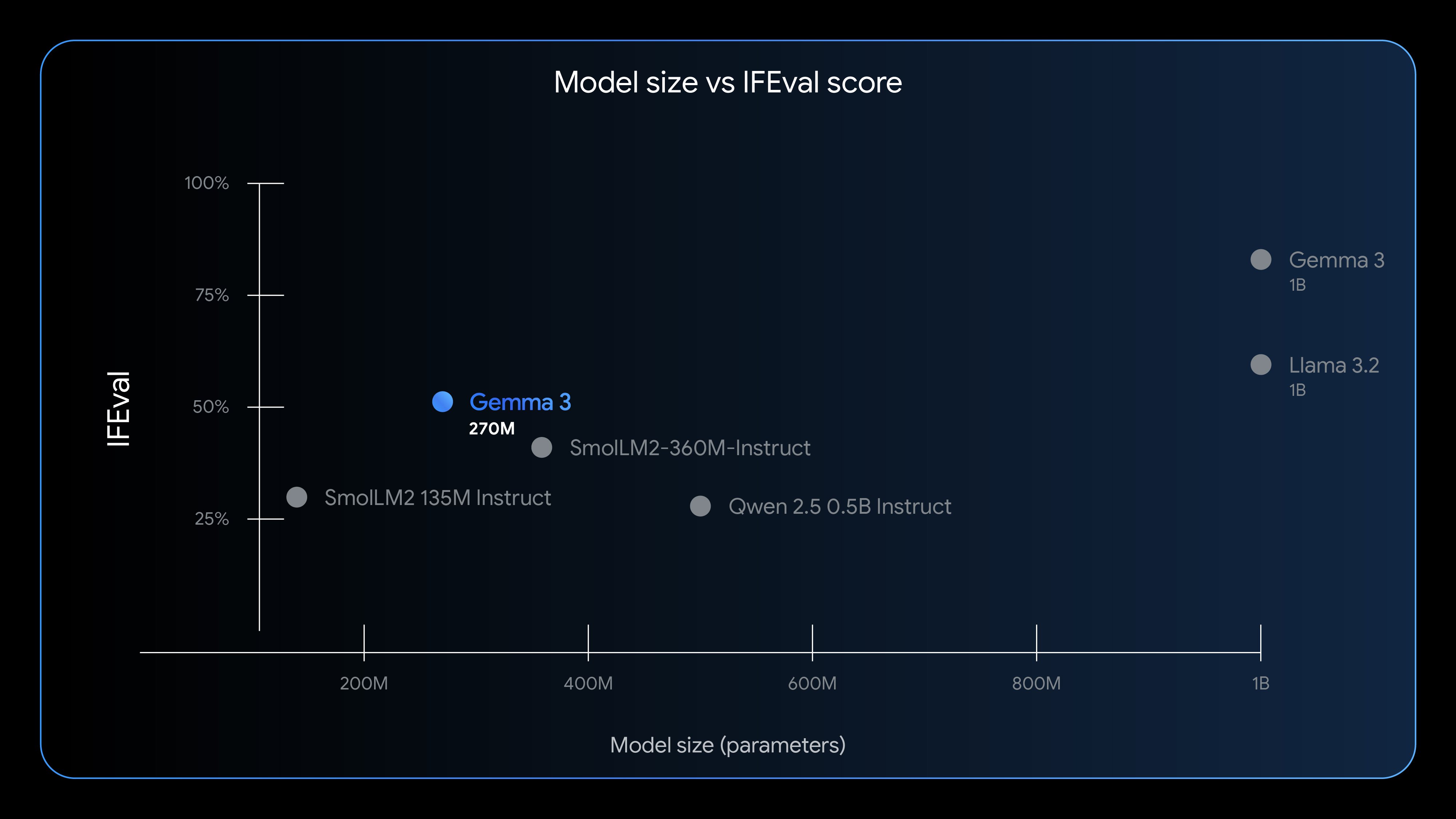
Gemma 3 270M brings strong instruction-following capabilities to a small-footprint model. As shown by the IFEval benchmark (which tests a model’s ability to follow verifiable instructions), it establishes a brand new level of performance for its size, making sophisticated AI capabilities more accessible for on-device and research applications.
Core capabilities of Gemma 3 270M
- Compact and capable architecture: Our recent model has a complete of 270 million parameters: 170 million embedding parameters as a consequence of a big vocabulary size and 100 million for our transformer blocks. Because of the big vocabulary of 256k tokens, the model can handle specific and rare tokens, making it a robust base model to be further fine-tuned in specific domains and languages.
- Extreme energy efficiency: A key advantage of Gemma 3 270M is its low power consumption. Internal tests on a Pixel 9 Pro SoC show the INT4-quantized model used just 0.75% of the battery for 25 conversations, making it our most power-efficient Gemma model.
- Instruction following: An instruction-tuned model is released alongside a pre-trained checkpoint. While this model isn’t designed for complex conversational use cases, it’s a robust model that follows general instructions right out of the box.
In engineering, success is defined by efficiency, not only raw power. You would not use a sledgehammer to hold an image frame. The identical principle applies to constructing with AI.
Gemma 3 270M embodies this “right tool for the job” philosophy. It is a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it might probably execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you may construct production systems which can be lean, fast, and dramatically cheaper to operate.
An actual-world blueprint for fulfillment
The facility of this approach has already delivered incredible leads to the actual world. An ideal example is the work done by Adaptive ML with SK Telecom. Facing the challenge of nuanced, multilingual content moderation, they selected to specialize. As an alternative of using an enormous, general-purpose model, Adaptive ML fine-tuned a Gemma 3 4B model. The outcomes were stunning: the specialized Gemma model not only met but exceeded the performance of much larger proprietary models on its specific task.
Gemma 3 270M is designed to let developers take this approach even further, unlocking even greater efficiency for well-defined tasks. It’s the proper start line for making a fleet of small, specialized models, each an authority at its own task.
But this power of specialization is not only for enterprise tasks; it also enables powerful creative applications. For instance, take a look at this Bedtime Story Generator web app:
Gemma 3 270M used to power a Bedtime Story Generator web app using Transformers.js. The model’s size and performance make it suitable for offline, web-based, creative tasks. (Credit: Joshua (@xenovacom on X) from the Hugging Face team)
When to decide on Gemma 3 270M
Gemma 3 270M inherits the advanced architecture and robust pre-training of the Gemma 3 collection, providing a solid foundation on your custom applications.
Here’s when it’s the proper selection:
- You’ve got a high-volume, well-defined task. Ideal for functions like sentiment evaluation, entity extraction, query routing, unstructured to structured text processing, creative writing, and compliance checks.
- You want to make every millisecond and micro-cent count. Drastically reduce, or eliminate, your inference costs in production and deliver faster responses to your users. A fine-tuned 270M model can run on lightweight, inexpensive infrastructure or directly on-device.
- You want to iterate and deploy quickly. The small size of Gemma 3 270M allows for rapid fine-tuning experiments, helping you discover the proper configuration on your use case in hours, not days.
- You want to ensure user privacy. Since the model can run entirely on-device, you may construct applications that handle sensitive information without ever sending data to the cloud.
- You wish a fleet of specialised task models. Construct and deploy multiple custom models, each expertly trained for a unique task, without breaking your budget.
Start with fine-tuning
We need to make it as easy as possible to show Gemma 3 270M into your individual custom solution. It’s built on the identical architecture as the remainder of the Gemma 3 models, with recipes and tools to get you began quickly. You’ll find our guide on full fine-tuning using Gemma 3 270M as a part of the Gemma docs.
The Gemmaverse is built on the concept innovation is available in all sizes. With Gemma 3 270M, we’re empowering developers to construct smarter, faster, and more efficient AI solutions. We will’t wait to see the specialized models you create.