
AI models have gotten increasingly complex, often exceeding the capabilities of accessible hardware. Quantization has emerged as an important technique to handle this challenge, enabling resource-intensive models to run on constrained hardware. The NVIDIA TensorRT and Model Optimizer tools simplify the quantization process, maintaining model accuracy while improving efficiency.
This blog series is designed to demystify quantization for developers latest to AI research, with a concentrate on practical implementation. By the tip of this post, you’ll understand how quantization works and when to use it.
The advantages of quantization
Model quantization makes it possible to deploy increasingly complex deep learning models in resource-constrained environments without sacrificing significant model accuracy. As AI models—especially generative AI models—grow in size and computational demands, quantization addresses challenges similar to memory usage, inference speed, and energy consumption by reducing the precision of model parameters (weights and/or activations), e.g., from FP32 precision to FP8 precision. This reduction decreases the model’s size and computational requirements, enabling faster computation during inference and lower power consumption in comparison with the unique model. Nevertheless, quantization can result in some accuracy degradation in comparison with the unique model. Finding the best tradeoff between model accuracy and efficiency depends heavily on the precise use case.
Quantization data types
Data types (similar to FP32, FP16, FP8) directly impact the computational resources required, influencing each the speed and efficiency of the model. Several floating-point formats could be used to represent a model’s parameters. Common formats include FP32, FP16, BF16, and FP8. Typically, a floating-point number uses n bits to store a numerical value, which is split into three components:
- Sign: This single bit indicates the sign of the number, 0 for positive and 1 for negative.
- Exponent: This portion encodes the exponent, representing the ability to which the bottom (commonly 2 in binary systems) is raised and defines the range of the datatype.
- Significand/mantissa: This represents the numerous digits of the number. The precision of the number heavily will depend on the length of the significand.
The formula used for this representation is:

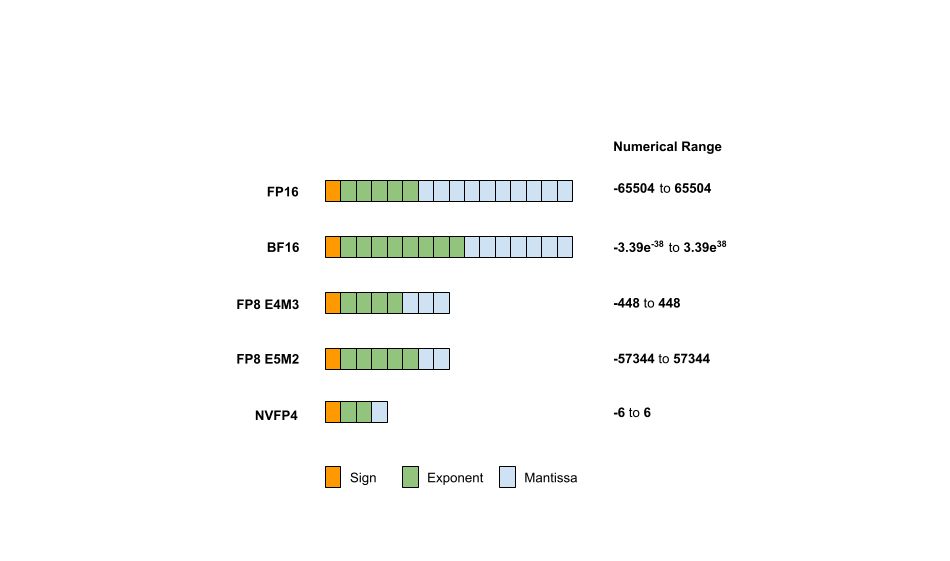
Because the variety of bits assigned to the exponent and mantissa can vary, the datatype is typically further specified. For FP8, you may find E4M3 indicating that 4 bits are used for the exponent and three bits for the mantissa. Figure 1 shows the varied representations and corresponding ranges of various data types, including FP16, BF16, FP8, and FP4.
Three key elements you’ll be able to quantize
Probably the most straightforward idea is to quantize the model’s weights to cut back its memory footprint. Nevertheless, there are additional components that could be quantized. The second necessary aspect is model activations, that are the intermediate outputs generated by model layers after each operation during inference. Although these activations are dynamic and never explicitly included within the model, they play an important role in quantization.
If the Llama2 7B model is stored in FP16/BF16, each parameter occupies 2 bytes, leading to a complete memory usage of roughly ~14 GB (7B parameters * 2 bytes/parameter). By quantizing the model to FP8, the memory required for the model weights is reduced to ~7GB, halving the memory footprint. Moreover, quantizing the model’s intermediate activations (compute) can further enhance inference speed through the use of specialized tensor core hardware that scales throughput with reduced bit width.
For transformer-based decoder models, one other component to contemplate is the KV cache during inference. This is restricted to decoder models, as they generate output tokens autoregressively using the KV cache to hurry up this process. The KV cache size will depend on the sequence length and the variety of layers and heads. For Llama2 7B with an extended context window (e.g., 4096 tokens), the KV cache may contribute several gigabytes to the overall memory footprint.
In summary, there are three key elements you’ll be able to quantize in today’s transformer-based models: model weights, model activations, and KV caches (applicable only to decoder models).
Quantization algorithms
Now that you have got a basic understanding of what quantization is, you’ll learn in regards to the quantization algorithm, showing how high-precision values are converted into low-precision representations. This process involves different techniques for determining the zero point and scaling factor, which results in the 2 essential varieties of quantization: affine/asymmetric and symmetric.
Affine quantization in comparison with symmetric quantization
Quantization maps floating point ![{LARGE x in [alpha, beta]}](https://s0.wp.com/latex.php?latex=%7B%5CLARGE+x+%5Cin+%5B%5Calpha%2C+%5Cbeta%5D%7D&bg=transparent&fg=000&s=0&c=20201002)
![{LARGE x_q in [alpha_q, beta_q]}](https://s0.wp.com/latex.php?latex=%7B%5CLARGE+x_q+%5Cin+%5B%5Calpha_q%2C+%5Cbeta_q%5D%7D&bg=transparent&fg=000&s=0&c=20201002)


Affine quantization
Affine, or asymmetric, quantization is defined by two key parameters: the dimensions factor 


Once these parameters are established, the quantization process can begin:

Where:
To get better the approximate full-precision value from a quantized value:

Where 

Throughout the quantization and de-quantization processes, rounding errors and clipping errors naturally occur, that are inherent to the quantization process.
Symmetric quantization
Symmetric quantization is a simplified version of the final asymmetric case, where zero-point


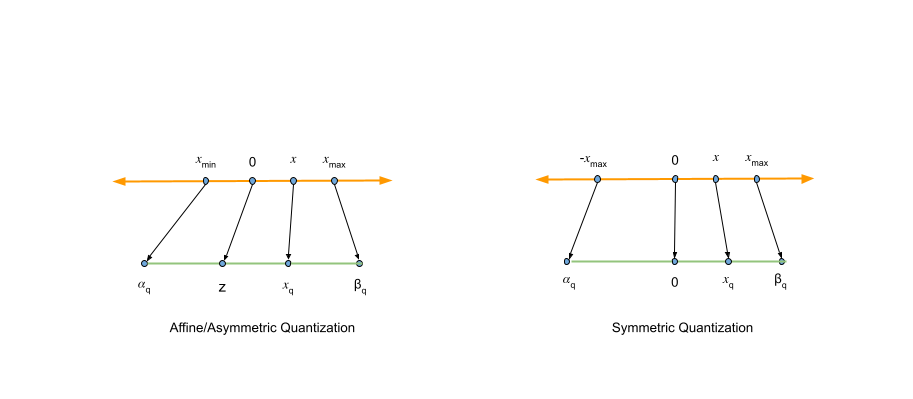
Because asymmetric quantization doesn’t offer a major boost in accuracy in comparison with symmetric quantization, the main target will probably be on supporting the symmetric case to any extent further, because it’s less complex. Moreover, aligning with industry standards, each NVIDIA TensorRT and Model Optimizer tools employ symmetric quantization.
AbsMax algorithm
The dimensions factor plays a key role. But how is its value actually determined? This section looks at a typical method called AbsMax quantization, which is widely used to calculate these values because of its simplicity and effectiveness.
The dimensions factor

The worth will depend on the range of the true input data and the range of the goal quantized representation.
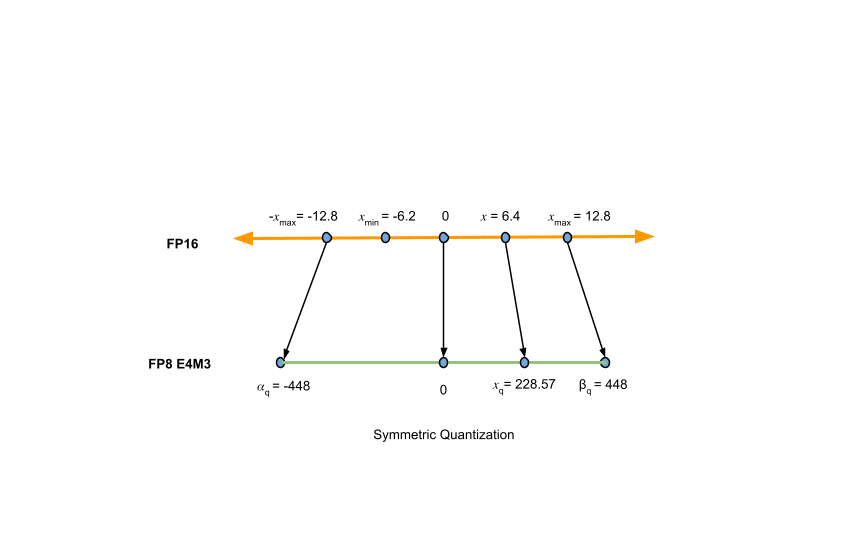
Figure 3 shows FP16 to FP8 symmetric quantization using the AbsMax algorithm. The dimensions for this process could be determined as follows:

Given 

Quantization granularity
To this point, we’ve defined the quantization parameters, learned methods to perform quantization, and methods to compute them using basic AbsMax quantization. Next, we’ll explore quantization granularity—that’s, how the quantization parameters are shared across the weather of a tensor. More specifically, this refers back to the level of granularity at which we compute the 

- Per-tensor (or per-layer) quantization: All values inside the tensor are quantized using the identical set of quantization parameters. That is the only and most memory-efficient approach, nevertheless it may result in higher quantization errors, especially when the information distribution varies across dimensions.
- Per-channel quantization: Different quantization parameters are used for every channel (typically along the channel dimension in convolutions). This reduces quantization error by isolating the impact of outlier values to their respective channels, quite than affecting the whole tensor.
- Per-block (or per-group) quantization: This provides more fine-grained control by dividing the tensor into smaller blocks or groups, each with its own quantization parameters. It’s especially useful when different regions of the tensor have various value distributions.

Advanced algorithms
Beyond the essential AbsMax algorithm, several advanced quantization algorithms have emerged to reinforce efficiency while minimizing degradation in accuracy. This section briefly introduces three of probably the most widely adopted.
- Activation-aware Weight Quantization (AWQ): AWQ is a weight-only quantization method that identifies and protects a small fraction of “salient” weight channels—those most crucial to model performance—by analyzing activation statistics collected during calibration. It applies per-channel scaling to those necessary weights, effectively reducing quantization error and enabling efficient low-bit quantization.
- Generative Pre-trained Transformer Quantization (GPTQ): GPTQ compresses models by quantizing each row of a weight matrix independently. It uses approximate second-order information, specifically the Hessian matrix, to guide the quantization process. This approach minimizes the output error introduced by quantization, enabling efficient and accurate compression with minimal loss in model performance.
- SmoothQuant: SmoothQuant enables each weights and activations to be quantized to eight bits by applying a mathematically equivalent per-channel scaling transformation that smooths out activation outliers, shifting quantization difficulty from activations to weights and preserving model accuracy and hardware efficiency.
Quantization approaches
Quantizing a model’s weights is simple, as these are static and data independent, with no additional data needed normally. Unlike weights, activations dynamically depend upon input data distributions that may vary significantly across different inputs and thereby influence the perfect scaling factor. Doing this calibration on pre-trained models refers to post-training quantization (PTQ).
During PTQ we add observers to every activation we would like to quantize and inference the model with representative data. The observers then take a look at the activation output and use the identical algorithm as before to find out a scaling factor. In AbsMax-quantization, the utmost absolute activation value 

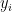

Post-training quantization
There are two essential approaches to PTQ: weight-only quantization and quantization of weights and activations.
In weight-only quantization, we’ve access to the trained model’s weights, and we simply quantize these weights. Because the weights are known and glued, no additional data is required. The method involves mapping the weights to lower-precision values using a calculated scale with/without zero-point parameters.
To quantize each weights and activations, we’d like representative input data. It’s because activations can only be obtained by running the model on actual input data. The means of collecting activation statistics and determining appropriate scale and zero-point values for them is referred to as calibration. During calibration, the model weights remain unchanged, and the input data is used to compute the quantization parameters, i.e., scales and 0 points. Based on when the calibration process occurs, weights and activations quantization could be categorized into two essential approaches: static quantization and dynamic quantization.
- Static quantization: This method involves using a calibration dataset to compute the quantization parameters once. These parameters are then fixed and reused for all future inferences.
- Dynamic quantization: On this approach, quantization parameters are computed during inference, meaning they will vary for every input as they’re calculated on the fly. This method doesn’t require a calibration dataset.
Quantization aware training
Quantization aware training (QAT) is a way designed to offset quality degradation that always accompanies the quantization of models. Unlike PTQ, which applies quantization after model training, QAT integrates quantization effects directly into the training process. That is achieved by simulating low-precision arithmetic during each the forward and backward passes, enabling the model parameters to learn and adapt to quantization-induced errors similar to rounding and clipping errors.
During QAT, the model employs “fake quantization” modules that mimic the behavior of low-precision operations without altering the actual data types. These modules quantize after which dequantize model weights and activations, enabling the model to experience quantization effects while maintaining high-precision computations for gradient updates. Typically, during QAT, the “fake quantization” modules are frozen, and the model weights are fine-tuned.
To deal with the non-differentiability of quantization functions similar to rounding during training, QAT uses the straight-through estimator (STE). STE approximates the gradient of those functions as identity during backpropagation, facilitating effective training despite the presence of non-differentiable operations.
Conclusion
On this blog post, we covered the theoretical features of quantization, providing technical background on different floating-point formats, popular quantization methods (similar to PTQ and QAT), and what to quantize—namely, weights, activations, and the KV cache for LLMs.
We also recommend exploring the next excellent blog posts to deepen your understanding of quantization and gain more advanced insights: