
Claude Sonnet 4.5 is the perfect coding model on the earth. It is the strongest model for constructing complex agents. It’s the perfect model at using computers. And it shows substantial gains in reasoning and math.
Code is in all places. It runs every application, spreadsheet, and software tool you utilize. Having the ability to use those tools and reason through hard problems is how modern work gets done.
Claude Sonnet 4.5 makes this possible. We’re releasing it together with a set of major upgrades to our products. In Claude Code, we have added checkpoints—one among our most requested features—that save your progress and help you roll back immediately to a previous state. We have refreshed the terminal interface and shipped a native VS Code extension. We have added a brand new context editing feature and memory tool to the Claude API that lets agents run even longer and handle even greater complexity. Within the Claude apps, we have brought code execution and file creation (spreadsheets, slides, and documents) directly into the conversation. And we have made the Claude for Chrome extension available to Max users who joined the waitlist last month.
We’re also giving developers the constructing blocks we use ourselves to make Claude Code. We’re calling this the Claude Agent SDK. The infrastructure that powers our frontier products—and allows them to succeed in their full potential—is now yours to construct with.
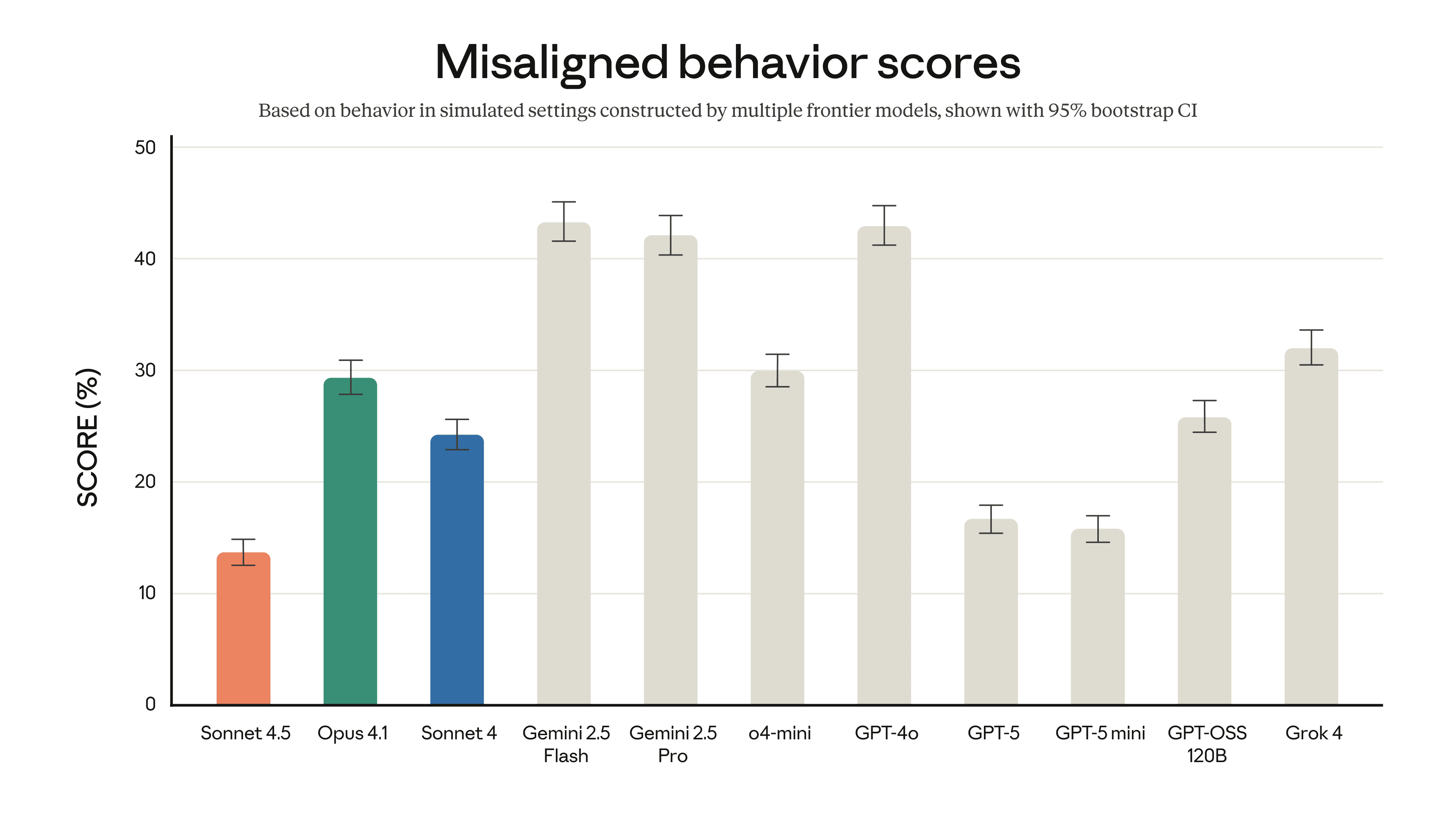
That is the most aligned frontier model we’ve ever released, showing large improvements across several areas of alignment in comparison with previous Claude models.
Claude Sonnet 4.5 is offered in all places today. When you’re a developer, simply use claude-sonnet-4-5 via the Claude API. Pricing stays the identical as Claude Sonnet 4, at $3/$15 per million tokens.
Frontier intelligence
Claude Sonnet 4.5 is state-of-the-art on the SWE-bench Verified evaluation, which measures real-world software coding abilities. Practically speaking, we’ve observed it maintaining focus for greater than 30 hours on complex, multi-step tasks.
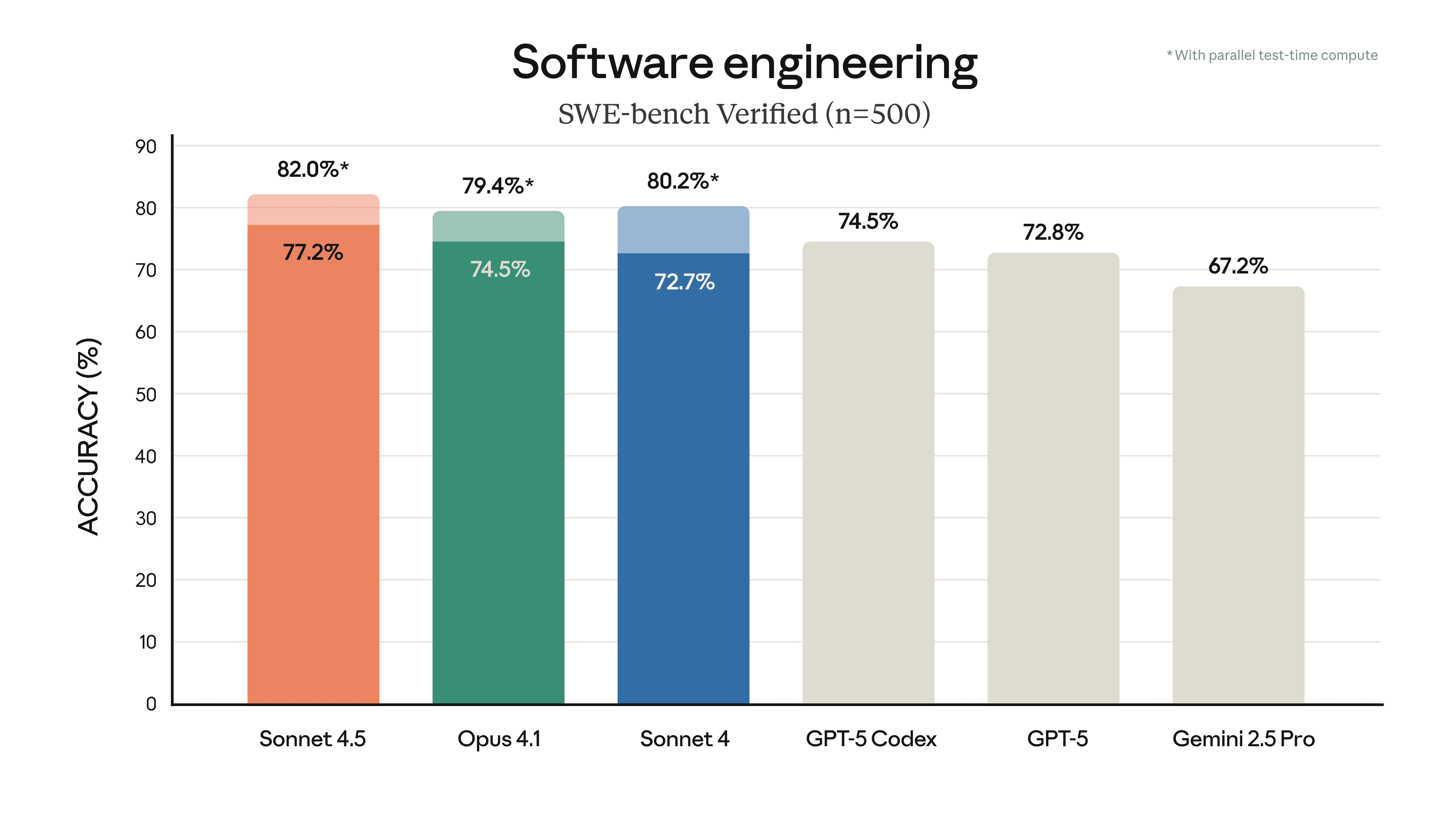
Claude Sonnet 4.5 represents a big breakthrough on computer use. On OSWorld, a benchmark that tests AI models on real-world computer tasks, Sonnet 4.5 now leads at 61.4%. Just 4 months ago, Sonnet 4 held the lead at 42.2%. Our Claude for Chrome extension puts these upgraded capabilities to make use of. Within the demo below, we show Claude working directly in a browser, navigating sites, filling spreadsheets, and completing tasks.
The model also shows improved capabilities on a broad range of evaluations including reasoning and math:
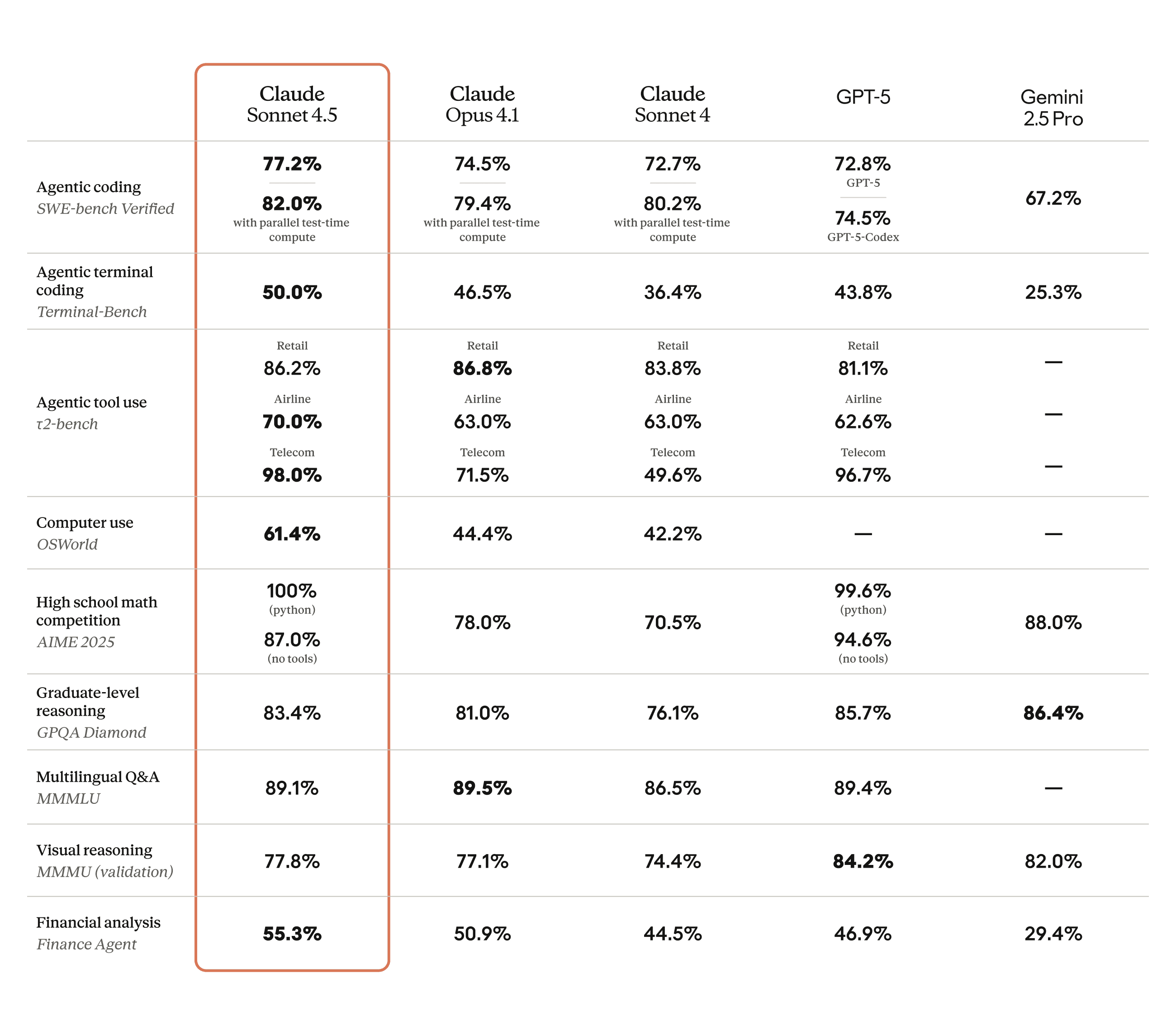
Experts in finance, law, medicine, and STEM found Sonnet 4.5 shows dramatically higher domain-specific knowledge and reasoning in comparison with older models, including Opus 4.1.
The model’s capabilities are also reflected within the experiences of early customers:
We’re seeing state-of-the-art coding performance from Claude Sonnet 4.5, with significant improvements on longer horizon tasks. It reinforces why many developers using Cursor select Claude for solving their most complex problems.
Claude Sonnet 4.5 amplifies GitHub Copilot’s core strengths. Our initial evals show significant improvements in multi-step reasoning and code comprehension—enabling Copilot’s agentic experiences to handle complex, codebase-spanning tasks higher.
Claude Sonnet 4.5 is great at software development tasks, learning our codebase patterns to deliver precise implementations. It handles every little thing from debugging to architecture with deep contextual understanding, transforming our development velocity.
Claude Sonnet 4.5 reduced average vulnerability intake time for our Hai security agents by 44% while improving accuracy by 25%, helping us reduce risk for businesses with confidence.
Claude Sonnet 4.5 is state-of-the-art on essentially the most complex litigation tasks. For instance, analyzing full briefing cycles and conducting research to synthesize excellent first drafts of an opinion for judges, or interrogating entire litigation records to create detailed summary judgment evaluation.
Claude Sonnet 4.5’s edit capabilities are exceptional — we went from 9% error rate on Sonnet 4 to 0% on our internal code editing benchmark. Higher tool success at lower cost is a significant leap for agentic coding. Claude Sonnet 4.5 balances creativity and control perfectly.
Claude Sonnet 4.5 delivers impressive gains on our most complex, long-context tasks—from engineering in our codebase to in-product features and research. It’s noticeably more intelligent and an enormous breakthrough, helping us push what 240M+ users can design with Canva.
Claude Sonnet 4.5 has noticeably improved Figma Make in early testing, making it easier to prompt and iterate. Teams can explore and validate their ideas with more functional prototypes and smoother interactions, while still getting the design quality Figma is understood for.
Sonnet 4.5 represents a brand new generation of coding models. It’s surprisingly efficient at maximizing actions per context window through parallel tool execution, for instance running multiple bash commands directly.
For Devin, Claude Sonnet 4.5 increased planning performance by 18% and end-to-end eval scores by 12%—the largest jump we have seen for the reason that release of Claude Sonnet 3.6. It excels at testing its own code, enabling Devin to run longer, handle harder tasks, and deliver production-ready code.
Claude Sonnet 4.5 shows strong promise for red teaming, generating creative attack scenarios that speed up how we study attacker tradecraft. These insights strengthen our defenses across endpoints, identity, cloud, data, SaaS, and AI workloads.
Claude Sonnet 4.5 resets our expectations—it handles 30+ hours of autonomous coding, freeing our engineers to tackle months of complex architectural work in dramatically less time while maintaining coherence across massive codebases.
For complex financial evaluation—risk, structured products, portfolio screening—Claude Sonnet 4.5 with considering delivers investment-grade insights that require less human review. When depth matters greater than speed, it is a meaningful step forward for institutional finance.
Our most aligned model yet
In addition to being our most capable model, Claude Sonnet 4.5 is our most aligned frontier model yet. Claude’s improved capabilities and our extensive safety training have allowed us to substantially improve the model’s behavior, reducing concerning behaviors like sycophancy, deception, power-seeking, and the tendency to encourage delusional considering. For the model’s agentic and computer use capabilities, we’ve also made considerable progress on defending against prompt injection attacks, one of the serious risks for users of those capabilities.
You’ll be able to read an in depth set of safety and alignment evaluations, which for the primary time includes tests using techniques from mechanistic interpretability, within the Claude Sonnet 4.5 system card.
Claude Sonnet 4.5 is being released under our AI Safety Level 3 (ASL-3) protections, as per our framework that matches model capabilities with appropriate safeguards. These safeguards include filters called classifiers that aim to detect potentially dangerous inputs and outputs—specifically those related to chemical, biological, radiological, and nuclear (CBRN) weapons.
These classifiers might sometimes inadvertently flag normal content. We’ve made it easy for users to proceed any interrupted conversations with Sonnet 4, a model that poses a lower CBRN risk. We have already made significant progress in reducing these false positives, reducing them by an element of ten since we originally described them, and an element of two since Claude Opus 4 was released in May. We’re continuing to make progress in making the classifiers more discerning1.
The Claude Agent SDK
We have spent greater than six months shipping updates to Claude Code, so we all know what it takes to construct and design AI agents. We have solved hard problems: how agents should manage memory across long-running tasks, how you can handle permission systems that balance autonomy with user control, and how you can coordinate subagents working toward a shared goal.
Now we’re making all of this available to you. The Claude Agent SDK is similar infrastructure that powers Claude Code, but it surely shows impressive advantages for a really wide range of tasks, not only coding. As of today, you should use it to construct your individual agents.
We built Claude Code since the tool we wanted didn’t exist yet. The Agent SDK gives you an identical foundation to construct something just as capable for whatever problem you are solving.
Bonus research preview
We’re releasing a brief research preview alongside Claude Sonnet 4.5, called “Imagine with Claude“.
On this experiment, Claude generates software on the fly. No functionality is predetermined; no code is prewritten. What you see is Claude creating in real time, responding and adapting to your requests as you interact.
It is a fun demonstration showing what Claude Sonnet 4.5 can do—a technique to see what’s possible if you mix a capable model with the best infrastructure.
“Imagine with Claude” is offered to Max subscribers for the subsequent five days. We encourage you to try it out on claude.ai/imagine.
Further information
We recommend upgrading to Claude Sonnet 4.5 for all uses. Whether you’re using Claude through our apps, our API, or Claude Code, Sonnet 4.5 is a drop-in substitute that gives much improved performance for a similar price. Claude Code updates can be found to all users. Claude Developer Platform updates, including the Claude Agent SDK, can be found to all developers. Code execution and file creation can be found on all paid plans within the Claude apps.
For complete technical details and evaluation results, see our system card, model page, and documentation. For more information, explore our engineering posts and research post on cybersecurity.