
✨ Overview
Traditional machine learning (ML) perception models typically deal with specific features and single modalities, deriving insights solely from natural language, speech, or vision evaluation. Historically, extracting and consolidating information from multiple modalities has been difficult because of siloed processing, complex architectures, and the chance of information being “lost in translation.” Nevertheless, multimodal and long-context large language models (LLMs) like Gemini can overcome these issues by processing all modalities inside the same context, opening recent possibilities.
Moving beyond speech-to-text, this notebook explores how one can achieve comprehensive video transcriptions by leveraging all available modalities. It covers the next topics:
- A technique for addressing recent or complex problems with a multimodal LLM
- A prompt technique for decoupling data and preserving attention: tabular extraction
- Strategies for taking advantage of Gemini’s 1M-token context in a single request
- Practical examples of multimodal video transcriptions
- Suggestions & optimizations
🔥 Challenge
To totally transcribe a video, we’re trying to answer the next questions:
- 1️⃣ What was said and when?
- 2️⃣ Who’re the speakers?
- 3️⃣ Who said what?
Can we solve this problem in an easy and efficient way?
🌟 State-of-the-art
1️⃣ What was said and when?
This can be a known problem with an existing solution:
- Speech-to-Text (STT) is a process that takes an audio input and transforms speech into text. STT can provide timestamps on the word level. It is usually referred to as automatic speech recognition (ASR).
Within the last decade, task-specific ML models have most effectively addressed this.
2️⃣ Who’re the speakers?
We will retrieve speaker names in a video from two sources:
- What’s written (e.g., speakers may be introduced with on-screen information after they first speak)
- What’s spoken (e.g., “Hello Bob! Alice! How are you doing?”)
Vision and Natural Language Processing (NLP) models may help with the next features:
- Vision: Optical Character Recognition (OCR), also called text detection, extracts the text visible in images.
- Vision: Person Detection identifies if and where individuals are in a picture.
- NLP: Entity Extraction can discover named entities in text.
3️⃣ Who said what?
That is one other known problem with a partial solution (complementary to Speech-to-Text):
- Speaker Diarization (also referred to as speaker turn segmentation) is a process that splits an audio stream into segments for different detected speakers (“Speaker A”, “Speaker B”, etc.).
Researchers have made significant progress on this field for a long time, particularly with ML models in recent times, but this continues to be an lively field of research. Existing solutions have shortcomings, akin to requiring human supervision and hints (e.g., the minimum and maximum variety of speakers, the language spoken), and supporting a limited set of languages.
🏺 Traditional ML pipeline
Solving all of 1️⃣, 2️⃣, and three️⃣ isn’t straightforward. This is able to likely involve establishing an elaborate supervised processing pipeline, based on just a few state-of-the-art ML models, akin to the next:
We would need days or perhaps weeks to design and arrange such a pipeline. Moreover, on the time of writing, our multimodal-video-transcription challenge shouldn’t be a solved problem, so there’s absolutely no certainty of reaching a viable solution.
Gemini allows for rapid prompt-based problem solving. With just text instructions, we will extract information and transform it into recent insights, through an easy and automatic workflow.
🎬 Multimodal
Gemini is natively multimodal, which implies it could process various kinds of inputs:
- text
- image
- audio
- video
- document
🌐 Multilingual
Gemini can also be multilingual:
- It will probably process inputs and generate outputs in 100+ languages
- If we will solve the video challenge for one language, that solution should naturally extend to all other languages
🧰 A natural-language toolbox
Multimodal and multilingual understanding in a single model lets us shift from counting on task-specific ML models to using a single versatile LLM.
Our challenge now looks quite a bit simpler:

In other words, let’s rephrase our challenge: Can we fully transcribe a video with just the next?
- 1 video
- 1 prompt
- 1 request
Let’s try with Gemini…
🏁 Setup
🐍 Python packages
We’ll use the next packages:
google-genai: the Google Gen AI Python SDK lets us call Gemini with just a few lines of codepandasfor data visualization
We’ll also use these packages (dependencies of google-genai):
pydanticfor data managementtenacityfor request management
pip install --quiet "google-genai>=1.31.0" "pandas[output-formatting]"🔗 Gemini API
We have now two predominant options to send requests to Gemini:
- Vertex AI: Construct enterprise-ready projects on Google Cloud
- Google AI Studio: Experiment, prototype, and deploy small projects
The Google Gen AI SDK provides a unified interface to those APIs and we will use environment variables for the configuration.
Option A – Gemini API via Vertex AI 🔽
Requirement:
- A Google Cloud project
- The Vertex AI API have to be enabled for this project
Gen AI SDK environment variables:
Learn more about establishing a project and a development environment.
Option B – Gemini API via Google AI Studio 🔽
Requirement:
Gen AI SDK environment variables:
GOOGLE_GENAI_USE_VERTEXAI="False"GOOGLE_API_KEY=""
Learn more about getting a Gemini API key from Google AI Studio.
💡 You’ll be able to store your environment configuration outside of the source code:
| Environment | Method |
|---|---|
| IDE | .env file (or equivalent) |
| Colab | Colab Secrets (🗝️ icon in left panel, see code below) |
| Colab Enterprise | Google Cloud project and site are mechanically defined |
| Vertex AI Workbench | Google Cloud project and site are mechanically defined |
Define the next environment detection functions. You may as well define your configuration manually if needed. 🔽
import os
import sys
from collections.abc import Callable
from google import genai
# Manual setup (leave unchanged if setup is environment-defined)
# @markdown **Which API: Vertex AI or Google AI Studio?**
GOOGLE_GENAI_USE_VERTEXAI = True # @param {type: "boolean"}
# @markdown **Option A - Google Cloud project [+location]**
GOOGLE_CLOUD_PROJECT = "" # @param {type: "string"}
GOOGLE_CLOUD_LOCATION = "global" # @param {type: "string"}
# @markdown **Option B - Google AI Studio API key**
GOOGLE_API_KEY = "" # @param {type: "string"}
def check_environment() -> bool:
check_colab_user_authentication()
return check_manual_setup() or check_vertex_ai() or check_colab() or check_local()
def check_manual_setup() -> bool:
return check_define_env_vars(
GOOGLE_GENAI_USE_VERTEXAI,
GOOGLE_CLOUD_PROJECT.strip(), # May need been pasted with line return
GOOGLE_CLOUD_LOCATION,
GOOGLE_API_KEY,
)
def check_vertex_ai() -> bool:
# Workbench and Colab Enterprise
match os.getenv("VERTEX_PRODUCT", ""):
case "WORKBENCH_INSTANCE":
pass
case "COLAB_ENTERPRISE":
if not running_in_colab_env():
return False
case _:
return False
return check_define_env_vars(
True,
os.getenv("GOOGLE_CLOUD_PROJECT", ""),
os.getenv("GOOGLE_CLOUD_REGION", ""),
"",
)
def check_colab() -> bool:
if not running_in_colab_env():
return False
# Colab Enterprise was checked before, so that is Colab only
from google.colab import auth as colab_auth # type: ignore
colab_auth.authenticate_user()
# Use Colab Secrets (🗝️ icon in left panel) to store the environment variables
# Secrets are private, visible only to you and the notebooks that you just select
# - Vertex AI: Store your settings as secrets
# - Google AI: Directly import your Gemini API key from the UI
vertexai, project, location, api_key = get_vars(get_colab_secret)
return check_define_env_vars(vertexai, project, location, api_key)
def check_local() -> bool:
vertexai, project, location, api_key = get_vars(os.getenv)
return check_define_env_vars(vertexai, project, location, api_key)
def running_in_colab_env() -> bool:
# Colab or Colab Enterprise
return "google.colab" in sys.modules
def check_colab_user_authentication() -> None:
if running_in_colab_env():
from google.colab import auth as colab_auth # type: ignore
colab_auth.authenticate_user()
def get_colab_secret(secret_name: str, default: str) -> str:
from google.colab import userdata # type: ignore
try:
return userdata.get(secret_name)
except Exception as e:
return default
def get_vars(getenv: Callable[[str, str], str]) -> tuple[bool, str, str, str]:
# Limit getenv calls to the minimum (may trigger UI confirmation for secret access)
vertexai_str = getenv("GOOGLE_GENAI_USE_VERTEXAI", "")
if vertexai_str:
vertexai = vertexai_str.lower() in ["true", "1"]
else:
vertexai = bool(getenv("GOOGLE_CLOUD_PROJECT", ""))
project = getenv("GOOGLE_CLOUD_PROJECT", "") if vertexai else ""
location = getenv("GOOGLE_CLOUD_LOCATION", "") if project else ""
api_key = getenv("GOOGLE_API_KEY", "") if not project else ""
return vertexai, project, location, api_key
def check_define_env_vars(
vertexai: bool,
project: str,
location: str,
api_key: str,
) -> bool:
match (vertexai, bool(project), bool(location), bool(api_key)):
case (True, True, _, _):
# Vertex AI - Google Cloud project [+location]
location = location or "global"
define_env_vars(vertexai, project, location, "")
case (True, False, _, True):
# Vertex AI - API key
define_env_vars(vertexai, "", "", api_key)
case (False, _, _, True):
# Google AI Studio - API key
define_env_vars(vertexai, "", "", api_key)
case _:
return False
return True
def define_env_vars(vertexai: bool, project: str, location: str, api_key: str) -> None:
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = str(vertexai)
os.environ["GOOGLE_CLOUD_PROJECT"] = project
os.environ["GOOGLE_CLOUD_LOCATION"] = location
os.environ["GOOGLE_API_KEY"] = api_key
def check_configuration(client: genai.Client) -> None:
service = "Vertex AI" if client.vertexai else "Google AI Studio"
print(f"Using the {service} API", end="")
if client._api_client.project:
print(f' with project "{client._api_client.project[:7]}…"', end="")
print(f' in location "{client._api_client.location}"')
elif client._api_client.api_key:
api_key = client._api_client.api_key
print(f' with API key "{api_key[:5]}…{api_key[-5:]}"', end="")
print(f" (in case of error, ensure that it was created for {service})")🤖 Gen AI SDK
To send Gemini requests, create a google.genai client:
from google import genai
check_environment()
client = genai.Client()Check your configuration:
check_configuration(client)Using the Vertex AI API with project "lpdemo-…" in location "europe-west9"🧠 Gemini model
Gemini comes in numerous versions.
Let’s start with Gemini 2.0 Flash, because it offers each high performance and low latency:
GEMINI_2_0_FLASH = "gemini-2.0-flash"
💡 We select Gemini 2.0 Flash intentionally. The Gemini 2.5 model family is mostly available and much more capable, but we would like to experiment and understand Gemini’s core multimodal behavior. If we complete our challenge with 2.0, this must also work with newer models.
⚙️ Gemini configuration
Gemini may be utilized in other ways, starting from factual to creative mode. The issue we’re trying to resolve is a data extraction use case. We would like results as factual and deterministic as possible. For this, we will change the content generation parameters.
We’ll set the temperature, top_p, and seed parameters to attenuate randomness:
temperature=0.0top_p=0.0seed=42(arbitrary fixed value)
🎞️ Video sources
Listed below are the predominant video sources that Gemini can analyze:
| source | URI | Vertex AI | Google AI Studio |
|---|---|---|---|
| Google Cloud Storage | gs://bucket/path/to/video.* |
✅ | |
| Web URL | https://path/to/video.* |
✅ | |
| YouTube | https://www.youtube.com/watch?v=YOUTUBE_ID |
✅ | ✅ |
⚠️ Essential notes
- Our video test suite primarily uses public YouTube videos. That is for simplicity.
- When analyzing YouTube sources, Gemini receives raw audio/video streams with none additional metadata, exactly as if processing the corresponding video files from Cloud Storage.
- YouTube does offer caption/subtitle/transcript features (user-provided or auto-generated). Nevertheless, these features deal with word-level speech-to-text and are limited to 40+ languages. Gemini doesn’t receive any of this data and also you’ll see that a multimodal transcription with Gemini provides additional advantages.
- Moreover, our challenge also involves identifying speakers and extracting speaker data, a novel recent capability.
🛠️ Helpers
Define our helper functions and data 🔽
import enum
from dataclasses import dataclass
from datetime import timedelta
import IPython.display
import tenacity
from google.genai.errors import ClientError
from google.genai.types import (
FileData,
FinishReason,
GenerateContentConfig,
GenerateContentResponse,
Part,
VideoMetadata,
)
class Model(enum.Enum):
# Generally Available (GA)
GEMINI_2_0_FLASH = "gemini-2.0-flash"
GEMINI_2_5_FLASH = "gemini-2.5-flash"
GEMINI_2_5_PRO = "gemini-2.5-pro"
# Default model
DEFAULT = GEMINI_2_0_FLASH
# Default configuration for more deterministic outputs
DEFAULT_CONFIG = GenerateContentConfig(
temperature=0.0,
top_p=0.0,
seed=42, # Arbitrary fixed value
)
YOUTUBE_URL_PREFIX = "https://www.youtube.com/watch?v="
CLOUD_STORAGE_URI_PREFIX = "gs://"
def url_for_youtube_id(youtube_id: str) -> str:
return f"{YOUTUBE_URL_PREFIX}{youtube_id}"
class Video(enum.Enum):
pass
class TestVideo(Video):
# For testing purposes, video duration is statically laid out in the enum name
# Suffix (ISO 8601 based): _PT[H][M][S]
# Google DeepMind | The Podcast | Season 3 Trailer | 59s
GDM_PODCAST_TRAILER_PT59S = url_for_youtube_id("0pJn3g8dfwk")
# Google Maps | Walk within the footsteps of Jane Goodall | 2min 42s
JANE_GOODALL_PT2M42S = "gs://cloud-samples-data/video/JaneGoodall.mp4"
# Google DeepMind | AlphaFold | The making of a scientific breakthrough | 7min 54s
GDM_ALPHAFOLD_PT7M54S = url_for_youtube_id("gg7WjuFs8F4")
# Brut | French reportage | 8min 28s
BRUT_FR_DOGS_WATER_LEAK_PT8M28S = url_for_youtube_id("U_yYkb-ureI")
# Google DeepMind | The Podcast | AI for science | 54min 23s
GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S = url_for_youtube_id("nQKmVhLIGcs")
# Google I/O 2025 | Developer Keynote | 1h 10min 03s
GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S = url_for_youtube_id("GjvgtwSOCao")
# Google Cloud | Next 2025 | Opening Keynote | 1h 40min 03s
GOOGLE_CLOUD_NEXT_PT1H40M03S = url_for_youtube_id("Md4Fs-Zc3tg")
# Google I/O 2025 | Keynote | 1h 56min 35s
GOOGLE_IO_KEYNOTE_PT1H56M35S = url_for_youtube_id("o8NiE3XMPrM")
class ShowAs(enum.Enum):
DONT_SHOW = enum.auto()
TEXT = enum.auto()
MARKDOWN = enum.auto()
@dataclass
class VideoSegment:
start: timedelta
end: timedelta
def generate_content(
prompt: str,
video: Video | None = None,
video_segment: VideoSegment | None = None,
model: Model | None = None,
config: GenerateContentConfig | None = None,
show_as: ShowAs = ShowAs.TEXT,
) -> None:
prompt = prompt.strip()
model = model or Model.DEFAULT
config = config or DEFAULT_CONFIG
model_id = model.value
if video:
if not (video_part := get_video_part(video, video_segment)):
return
contents = [video_part, prompt]
caption = f"{video.name} / {model_id}"
else:
contents = prompt
caption = f"{model_id}"
print(f" {caption} ".center(80, "-"))
for attempt in get_retrier():
with attempt:
response = client.models.generate_content(
model=model_id,
contents=contents,
config=config,
)
display_response_info(response)
display_response(response, show_as)
def get_video_part(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
) -> Part | None:
video_uri: str = video.value
if not client.vertexai:
video_uri = convert_to_https_url_if_cloud_storage_uri(video_uri)
if not video_uri.startswith(YOUTUBE_URL_PREFIX):
print("Google AI Studio API: Only YouTube URLs are currently supported")
return None
file_data = FileData(file_uri=video_uri, mime_type="video/*")
video_metadata = get_video_part_metadata(video_segment, fps)
return Part(file_data=file_data, video_metadata=video_metadata)
def get_video_part_metadata(
video_segment: VideoSegment | None = None,
fps: float | None = None,
) -> VideoMetadata:
def offset_as_str(offset: timedelta) -> str:
return f"{offset.total_seconds()}s"
if video_segment:
start_offset = offset_as_str(video_segment.start)
end_offset = offset_as_str(video_segment.end)
else:
start_offset = None
end_offset = None
return VideoMetadata(start_offset=start_offset, end_offset=end_offset, fps=fps)
def convert_to_https_url_if_cloud_storage_uri(uri: str) -> str:
if uri.startswith(CLOUD_STORAGE_URI_PREFIX):
return f"https://storage.googleapis.com/{uri.removeprefix(CLOUD_STORAGE_URI_PREFIX)}"
else:
return uri
def get_retrier() -> tenacity.Retrying:
return tenacity.Retrying(
stop=tenacity.stop_after_attempt(7),
wait=tenacity.wait_incrementing(start=10, increment=1),
retry=should_retry_request,
reraise=True,
)
def should_retry_request(retry_state: tenacity.RetryCallState) -> bool:
if not retry_state.final result:
return False
err = retry_state.final result.exception()
if not isinstance(err, ClientError):
return False
print(f"❌ ClientError {err.code}: {err.message}")
retry = False
match err.code:
case 400 if err.message shouldn't be None and " try again " in err.message:
# Workshop: project accessing Cloud Storage for the primary time (service agent provisioning)
retry = True
case 429:
# Workshop: temporary project with 1 QPM quota
retry = True
print(f"🔄 Retry: {retry}")
return retry
def display_response_info(response: GenerateContentResponse) -> None:
if usage_metadata := response.usage_metadata:
if usage_metadata.prompt_token_count:
print(f"Input tokens : {usage_metadata.prompt_token_count:9,d}")
if usage_metadata.candidates_token_count:
print(f"Output tokens : {usage_metadata.candidates_token_count:9,d}")
if usage_metadata.thoughts_token_count:
print(f"Thoughts tokens: {usage_metadata.thoughts_token_count:9,d}")
if not response.candidates:
print("❌ No `response.candidates`")
return
if (finish_reason := response.candidates[0].finish_reason) != FinishReason.STOP:
print(f"❌ {finish_reason = }")
if not response.text:
print("❌ No `response.text`")
return
def display_response(
response: GenerateContentResponse,
show_as: ShowAs,
) -> None:
if show_as == ShowAs.DONT_SHOW:
return
if not (response_text := response.text):
return
response_text = response.text.strip()
print(" start of response ".center(80, "-"))
match show_as:
case ShowAs.TEXT:
print(response_text)
case ShowAs.MARKDOWN:
display_markdown(response_text)
print(" end of response ".center(80, "-"))
def display_markdown(markdown: str) -> None:
IPython.display.display(IPython.display.Markdown(markdown))
def display_video(video: Video) -> None:
video_url = convert_to_https_url_if_cloud_storage_uri(video.value)
assert video_url.startswith("https://")
video_width = 600
if video_url.startswith(YOUTUBE_URL_PREFIX):
youtube_id = video_url.removeprefix(YOUTUBE_URL_PREFIX)
ipython_video = IPython.display.YouTubeVideo(youtube_id, width=video_width)
else:
ipython_video = IPython.display.Video(video_url, width=video_width)
display_markdown(f"### Video ([source]({video_url}))")
IPython.display.display(ipython_video) 🧪 Prototyping
🌱 Natural behavior
Before diving any deeper, it’s interesting to see how Gemini responds to easy instructions, to develop some intuition about its natural behavior.
Let’s first see what we get with minimalistic prompts and a brief English video.
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
display_video(video)
prompt = "Transcribe the video's audio with time information."
generate_content(prompt, video)
Video (source)
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,708
Output tokens : 421
------------------------------ start of response -------------------------------
[00:00:00] Do I even have to call you Sir Demis now?
[00:00:01] Oh, you do not.
[00:00:02] Absolutely not.
[00:00:04] Welcome to Google DeepMind the podcast with me, your host Professor Hannah Fry.
[00:00:06] We would like to take you to the center of where these ideas are coming from.
[00:00:12] We would like to introduce you to the people who find themselves leading the design of our collective future.
[00:00:19] Getting the security right might be, I'd say, one of the necessary challenges of our time.
[00:00:25] I need protected and capable.
[00:00:27] I need a bridge that won't collapse.
[00:00:30] just give these scientists a superpower that they'd not imagined earlier.
[00:00:34] autonomous vehicles.
[00:00:35] It's hard to fathom that if you're working on a search engine.
[00:00:38] We may even see entirely recent genre or entirely recent types of art come up.
[00:00:42] There could also be a brand new word that shouldn't be music, painting, photography, movie making, and that AI can have helped us create it.
[00:00:48] You actually need AGI to give you the option to see into the mysteries of the universe.
[00:00:51] Yes, quantum mechanics, string theory, well, and the character of reality.
[00:00:55] Ow.
[00:00:57] the magic of AI.
------------------------------- end of response --------------------------------Results:
- Gemini naturally outputs an inventory of
[time] transcriptlines. - That’s Speech-to-Text in a single line!
- It looks like we will answer “1️⃣ What was said and when?”.
Now, what about “2️⃣ Who’re the speakers?”
prompt = "List the speakers identifiable within the video."
generate_content(prompt, video)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,705
Output tokens : 46
------------------------------ start of response -------------------------------
Listed below are the speakers identifiable within the video:
* Professor Hannah Fry
* Demis Hassabis
* Anca Dragan
* Pushmeet Kohli
* Jeff Dean
* Douglas Eck
------------------------------- end of response --------------------------------Results:
- Gemini can consolidate the names visible on title cards in the course of the video.
- That’s OCR + entity extraction in a single line!
- “2️⃣ Who’re the speakers?” looks solved too!
⏩ Not so fast!
The natural next step is to leap to the ultimate instructions, to resolve our problem once and for all.
prompt = """
Transcribe the video's audio including speaker names (use "?" if not found).
Format example:
[00:02] John Doe - Hello Alice!
"""
generate_content(prompt, video)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,732
Output tokens : 378
------------------------------ start of response -------------------------------
Here is the audio transcription of the video:
[00:00] ? - Do I even have to call you Sir Demis now?
[00:01] Demis Hassabis - Oh, you do not. Absolutely not.
[00:04] Professor Hannah Fry - Welcome to Google DeepMind the podcast with me, your host, Professor Hannah Fry.
[00:06] Professor Hannah Fry - We would like to take you to the center of where these ideas are coming from. We would like to introduce you to the people who find themselves leading the design of our collective future.
[00:19] Anca Dragan - Getting the security right might be, I'd say, one of the necessary challenges of our time. I need protected and capable. I need a bridge that won't collapse.
[00:29] Pushmeet Kohli - Just give these scientists a superpower that they'd not imagined earlier.
[00:34] Jeff Dean - Autonomous vehicles. It's hard to fathom that if you're working on a search engine.
[00:38] Douglas Eck - We may even see entirely recent genre or entirely recent types of art come up. There could also be a brand new word that shouldn't be music, painting, photography, movie making, and that AI can have helped us create it.
[00:48] Professor Hannah Fry - You actually need AGI to give you the option to see into the mysteries of the universe.
[00:51] Demis Hassabis - Yes, quantum mechanics, string theory, well, and the character of reality.
[00:55] Professor Hannah Fry - Ow!
[00:57] Douglas Eck - The magic of AI.
------------------------------- end of response --------------------------------This is sort of correct. The primary segment isn’t attributed to the host (who is barely introduced a bit later), but all the things else looks correct.
Nonetheless, these usually are not real-world conditions:
- The video may be very short (lower than a minute)
- The video can also be relatively easy (speakers are clearly introduced with on-screen title cards)
Let’s try with this 8-minute (and more complex) video:
generate_content(prompt, TestVideo.GDM_ALPHAFOLD_PT7M54S)Output 🔽
------------------- GDM_ALPHAFOLD_PT7M54S / gemini-2.0-flash -------------------
Input tokens : 134,177
Output tokens : 2,689
------------------------------ start of response -------------------------------
[00:02] ? - We have discovered more concerning the world than another civilization before us.
[00:08] ? - But we have now been stuck on this one problem.
[00:11] ? - How do proteins fold up?
[00:13] ? - How do proteins go from a string of amino acids to a compact shape that acts as a machine and drives life?
[00:22] ? - If you discover about proteins, it is rather exciting.
[00:25] ? - You might consider them as little biological nano machines.
[00:28] ? - They're essentially the basic constructing blocks that power all the things living on this planet.
[00:34] ? - If we will reliably predict protein structures using AI, that might change the best way we understand the natural world.
[00:46] ? - Protein folding is one among these holy grail type problems in biology.
[00:50] Demis Hassabis - We have at all times hypothesized that AI needs to be helpful to make these kinds of massive scientific breakthroughs more quickly.
[00:58] ? - After which I'll probably be taking a look at little tunings which may make a difference.
[01:02] ? - It needs to be making a histogram on and a background skill.
[01:04] ? - We have been working on our system AlphaFold really hard now for over two years.
[01:08] ? - Somewhat than having to do painstaking experiments, in the long run biologists might give you the option to as an alternative depend on AI methods to directly predict structures quickly and efficiently.
[01:17] Kathryn Tunyasuvunakool - Generally speaking, biologists are inclined to be quite skeptical of computational work, and I feel that skepticism is healthy and I respect it, but I feel very enthusiastic about what AlphaFold can achieve.
[01:28] Andrew Senior - CASP is after we, we are saying, look, DeepMind is doing protein folding.
[01:31] Andrew Senior - That is how good we're, and perhaps it's higher than everybody else, perhaps it's not.
[01:37] ? - We decided to enter CASP competition since it represented the Olympics of protein folding.
[01:44] John Moult - CASP, we began to attempt to speed up the answer to the protein folding problem.
[01:50] John Moult - Once we began CASP in 1994, I definitely was naive about how hard this was going to be.
[01:58] ? - It was very cumbersome to try this since it took an extended time.
[02:01] ? - Let's have a look at what, what, what are we doing still to enhance?
[02:03] ? - Typically 100 different groups from world wide take part in CASP, and we take a set of 100 proteins and we ask the groups to send us what they think the structures appear to be.
[02:15] ? - We will reach 57.9 GDT on CASP 12 ground truth.
[02:19] John Jumper - CASP has a metric on which you will probably be scored, which is that this GDT metric.
[02:25] John Jumper - On a scale of zero to 100, you'll expect a GDT over 90 to be an answer to the issue.
[02:33] ? - If we do achieve this, this has incredible medical relevance.
[02:37] Pushmeet Kohli - The implications are immense, from how diseases progress, how you'll be able to discover recent drugs.
[02:45] Pushmeet Kohli - It's countless.
[02:46] ? - I desired to make a, a extremely easy system and the outcomes have been surprisingly good.
[02:50] ? - The team got some results with a brand new technique, not only is it more accurate, however it's much faster than the old system.
[02:56] ? - I feel we'll substantially exceed what we're doing at once.
[02:59] ? - This can be a game, game changer, I feel.
[03:01] John Moult - In CASP 13, something very significant had happened.
[03:06] John Moult - For the primary time, we saw the effective application of artificial intelligence.
[03:11] ? - We have advanced the cutting-edge in the sector, in order that's incredible, but we still got an extended solution to go before we have solved it.
[03:18] ? - The shapes were now roughly correct for lots of the proteins, but the main points, exactly where each atom sits, which is actually what we might call an answer, we're not yet there.
[03:29] ? - It doesn't help if you may have the tallest ladder if you're going to the moon.
[03:33] ? - We hit a little bit little bit of a brick wall, um, since we won CASP, then it was back to the drafting board and like what are our recent ideas?
[03:41] ? - Um, after which it's taken a little bit while, I'd say, for them to get back to where they were, but with the brand new ideas.
[03:51] ? - They'll go further, right?
[03:52] ? - So, um, in order that's a extremely necessary moment.
[03:55] ? - I've seen that moment so repeatedly now, but I do know what meaning now, and I do know that is the time now to press.
[04:02] ? - We'd like to double down and go as fast as possible from here.
[04:05] ? - I feel we have no time to lose.
[04:07] ? - So the intention is to enter CASP again.
[04:09] ? - CASP is deeply stressful.
[04:12] ? - There's something weird occurring with, um, the educational since it is learning something that is correlated with GDT, however it's not calibrated.
[04:18] ? - I feel barely uncomfortable.
[04:20] ? - We needs to be learning this, you already know, within the blink of a watch.
[04:23] ? - The technology advancing outside DeepMind can also be doing incredible work.
[04:27] Richard Evans - And there is at all times the likelihood one other team has come somewhere on the market field that we do not even learn about.
[04:32] ? - Someone asked me, well, should we panic now?
[04:33] ? - After all, we should always have been panicking before.
[04:35] ? - It does appear to do higher, but still doesn't do quite in addition to the perfect model.
[04:39] ? - Um, so it looks like there's room for improvement.
[04:42] ? - There's at all times a risk that you have missed something, and that is why blind assessments like CASP are so necessary to validate whether our results are real.
[04:49] ? - Obviously, I'm excited to see how CASP 14 goes.
[04:51] ? - My expectation is we get our heads down, we deal with the complete goal, which is to resolve the entire problem.
[05:14] ? - We were prepared for CASP to start out on April fifteenth because that is when it was originally scheduled to start out, and it has been delayed by a month because of coronavirus.
[05:24] ? - I actually miss everyone.
[05:25] ? - No, I struggled a little bit bit just sort of moving into a routine, especially, uh, my wife, she got here down with the, the virus.
[05:32] ? - I mean, luckily it didn't prove too serious.
[05:34] ? - CASP began on Monday.
[05:37] Demis Hassabis - Can I just check this diagram you have came, John, this one where we ask ground truth.
[05:40] Demis Hassabis - Is that this one we have done badly on?
[05:42] ? - We're actually quite good on this region.
[05:43] ? - For those who imagine that we hadn't have said it got here around this manner, but had put it in.
[05:47] ? - Yeah, and that as an alternative.
[05:48] ? - Yeah.
[05:49] ? - One in all the toughest proteins we have gotten in CASP to this point is a SARS-CoV-2 protein, uh, called Orf8.
[05:55] ? - Orf8 is a coronavirus protein.
[05:57] ? - We tried really hard to enhance our prediction, like really, really hard, probably probably the most time that we have now ever spent on a single goal.
[06:05] ? - So we're about two-thirds of the best way through CASP, and we have gotten three answers back.
[06:11] ? - We now have a ground truth for Orf8, which is one among the coronavirus proteins.
[06:17] ? - And it seems we did very well in predicting that.
[06:20] Demis Hassabis - Amazing job, everyone, the entire team.
[06:23] Demis Hassabis - It has been an incredible effort.
[06:24] John Moult - Here what we saw in CASP 14 was a bunch delivering atomic accuracy off the bat, essentially solving what in our world is 2 problems.
[06:34] John Moult - How do you look to seek out the correct solution, after which how do you recognize you have got the correct solution if you're there?
[06:41] ? - All right, are we, are we mostly here?
[06:46] ? - I will read an email.
[06:48] ? - Uh, I got this from John Moult.
[06:50] ? - Now I'll just read it.
[06:51] ? - It says, John, as I expect you already know, your group has performed amazingly well in CASP 14, each relative to other groups and in absolute model accuracy.
[07:02] ? - Congratulations on this work.
[07:05] ? - It is actually outstanding.
[07:07] Demis Hassabis - AlphaFold represents an enormous step forward that I hope will really speed up drug discovery and help us to higher understand disease.
[07:13] John Moult - It's pretty mind-blowing.
[07:16] John Moult - You understand, these results were, for me, having worked on this problem so long, after many, many stops and starts and can this ever get there, suddenly it is a solution.
[07:28] John Moult - We have solved the issue.
[07:29] John Moult - This provides you such excitement concerning the way science works, about how you'll be able to never see exactly and even roughly what is going on to occur next.
[07:37] John Moult - There are at all times these surprises, and that actually, as a scientist, is what keeps you going.
[07:41] John Moult - What is going on to be the following surprise?
------------------------------- end of response --------------------------------This falls apart: Most segments don’t have any identified speaker!
As we are attempting to resolve a brand new complex problem, LLMs haven’t been trained on any known solution. This is probably going why direct instructions don’t yield the expected answer.
At this stage:
- We would conclude that we will’t solve the issue with real-world videos.
- Persevering by trying increasingly more elaborate prompts for this unsolved problem might lead to a waste of time.
Let’s take a step back and take into consideration what happens under the hood…
⚛️ Under the hood
Modern LLMs are mostly built upon the Transformer architecture, a brand new neural network design detailed in a 2017 paper by Google researchers titled Attention Is All You Need. The paper introduced the self-attention mechanism, a key innovation that fundamentally modified the best way machines process language.
🪙 Tokens
Tokens are the LLM constructing blocks. We will consider a token to represent a bit of knowledge.
Examples of Gemini multimodal tokens (with default parameters):
| content | tokens | details |
|---|---|---|
hello |
1 | 1 token for common words/sequences |
passionately |
2 | passion•ately |
passionnément |
3 | passion•né•ment (same adverb in French) |
| image | 258 | per image (or per tile depending on image resolution) |
| audio without timecodes | 25 / second | handled by the audio tokenizer |
| video without audio | 258 / frame | handled by the video tokenizer at 1 frame per second |
MM:SS timecode |
5 | audio chunk or video frame temporal reference |
H:MM:SS timecode |
7 | similarly, for content longer than 1 hour |
🎞️ Sampling frame rate
By default, video frames are sampled at 1 frame per second (1 FPS). These frames are included within the context with their corresponding timecodes.
You should utilize a custom sampling frame rate with the Part.video_metadata.fps parameter:
| video type | change | fps range |
|---|---|---|
| static, slow | decrease the frame rate | 0.0 < fps < 1.0 |
| dynamic, fast | increase the frame rate | 1.0 < fps <= 24.0 |
💡 For
1.0 < fps, Gemini was trained to knowMM:SS.sssandH:MM:SS.ssstimecodes.
🔍 Media resolution
By default, each sampled frame is represented with 258 tokens.
You'll be able to specify a medium or low media resolution with the GenerateContentConfig.media_resolution parameter:
| media_resolution for video inputs | tokens/ frame | profit |
|---|---|---|
MEDIA_RESOLUTION_MEDIUM (default) |
258 | higher precision, allows more detailed understanding |
MEDIA_RESOLUTION_LOW |
66 | faster and cheaper inference, allows longer videos |
💡 The “media resolution” may be seen because the “image token resolution”: the variety of tokens used to represent a picture.
🧮 Probabilities all the best way down
The power of LLMs to speak in flawless natural language may be very impressive, however it’s easy to get carried away and make incorrect assumptions.
Take into accout how LLMs work:
- An LLM is trained on an enormous tokenized dataset, which represents its knowledge (its long-term memory)
- In the course of the training, its neural network learns token patterns
- If you send a request to an LLM, your inputs are transformed into tokens (tokenization)
- To reply your request, the LLM predicts, token by token, the following likely tokens
- Overall, LLMs are exceptional statistical token prediction machines that appear to mimic how some parts of our brain work
This has just a few consequences:
- LLM outputs are only statistically likely follow-ups to your inputs
- LLMs show some types of reasoning: they'll match complex patterns but don't have any actual deep understanding
- LLMs don't have any consciousness: they're designed to generate tokens and can achieve this based in your instructions
- Order matters: Tokens which might be generated first will influence tokens which might be generated next
For the following step, some methodical prompt crafting might help…
🏗️ Prompt crafting
🪜 Methodology
Prompt crafting, also called prompt engineering, is a comparatively recent field. It involves designing and refining text instructions to guide LLMs towards generating desired outputs. Like writing, it's each an art and a science, a skill that everybody can develop with practice.
We will find countless reference materials about prompt crafting. Some prompts may be very long, complex, and even scary. Crafting prompts with a high-performing LLM like Gemini is far simpler. Listed below are three key adjectives to take note:
- iterative
- precise
- concise
Iterative
Prompt crafting is often an iterative process. Listed below are some recommendations:
- Craft your prompt step-by-step
- Keep track of your successive iterations
- At every iteration, ensure that to measure what’s working versus what’s not
- For those who reach a regression, backtrack to a successful iteration
Precise
Precision is essential:
- Use words as specific as possible
- Words with multiple meanings can introduce variability, so use precise expressions
- Precision will influence probabilities in your favor
Concise
Concision has additional benefits:
- A brief prompt is simpler for us developers to know (and maintain!)
- The longer your prompt is, the more likely you might be to introduce inconsistencies and even contradictions, which leads to variable interpretations of your instructions
- Test and trust the LLM’s knowledge: this data acts as an implicit context and may make your prompt shorter and clearer
Overall, though this will likely seem contradictory, should you take the time to be iterative, precise, and concise, you might be likely to save lots of a variety of time.
💡 If you need to explore this topic, try Prompting strategies (Google Cloud reference) and Prompt engineering (68-page PDF by Lee Boonstra).
📚 Terminology
We’re not experts in video transcription (yet!) but we would like Gemini to behave as one. Consequently, we’d like to jot down prompts as specific as possible for this use case. While LLMs process instructions based on their training knowledge, they may share this data with us.
We will learn quite a bit by directly asking Gemini:
prompt = """
What's the terminology used for video transcriptions?
Please show a typical output example.
"""
generate_content(prompt, show_as=ShowAs.MARKDOWN)Output 🔽
------------------------------- gemini-2.0-flash -------------------------------
Input tokens : 18
Output tokens : 1,814
------------------------------ start of response -------------------------------## Terminology Used for Video Transcriptions
Here's a breakdown of common terminology used when discussing video transcriptions:
* **Transcription:** The overall term for converting audio or video content into text.
* **Video Transcription:** Specifically refers to transcribing the audio portion of a video.
* **Verbatim Transcription:** A transcription that features every spoken word, including filler words ("um," "ah"), false starts, stutters, and background noises (if relevant). It goals for a highly accurate representation of the spoken word.
* **Clean Verbatim Transcription (or Edited Transcription):** A transcription that removes filler words, false starts, and stutters to create a more readable and polished text. It focuses on conveying the meaning clearly.
* **Intelligent Verbatim Transcription:** A middle ground between verbatim and clean verbatim. It removes some filler words and stutters but retains elements that contribute to the speaker's style or the context of the conversation.
* **Summary Transcription:** A transient overview of the video's content, highlighting the predominant points.
* **Timecoding (or Timestamping):** Adding timestamps to the transcription to point when each section of text was spoken within the video. That is crucial for accessibility and navigation.
* **Speaker Identification:** Identifying and labeling different speakers within the video.
* **Captioning (or Subtitling):** Creating text versions of the video's audio which might be displayed on the screen, often synchronized with the video. Captions are sometimes used for accessibility (for deaf or hard-of-hearing viewers) and for viewers preferring to read along.
* **Closed Captions:** Captions that may be turned on or off by the viewer.
* **Open Captions:** Captions which might be permanently embedded within the video and can't be turned off.
* **SRT (SubRip Subtitle):** A typical file format for storing captions and subtitles.
* **VTT (Video Text Tracks):** A more modern file format for captions and subtitles, often used with HTML5 video.
* **Burned-in Captions:** Captions which might be permanently embedded into the video file.
* **Transcriber:** The person or software that performs the transcription.
* **Accuracy Rate:** The proportion of words transcribed appropriately.
* **Turnaround Time:** The time it takes to finish the transcription.
## Typical Output Example
For instance we have now a brief video clip of an interview. Here's how various kinds of transcriptions might look:
**Scenario:** A brief clip of an interview with a chef discussing their recent restaurant.
**1. Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the show!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It's, uh, great to be here.
00:00:06 --> 00:00:12 Interviewer: So, tell us a little bit bit about your recent restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Well, um, it's, it has been a dream of mine for, like, years, you already know? To, like, open a spot that actually focuses on, um, seasonal ingredients.
00:00:20 --> 00:00:25 Interviewer: And what sort of cuisine can people expect?
00:00:25 --> 00:00:32 Chef: We're doing, uh, modern American, but with, like, an actual emphasis on, uh, local farms and, you already know, sustainable practices.
```
**2. Clean Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the show!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It's great to be here.
00:00:06 --> 00:00:12 Interviewer: So, tell us a little bit bit about your recent restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Well, it has been a dream of mine for years to open a spot that actually focuses on seasonal ingredients.
00:00:20 --> 00:00:25 Interviewer: And what sort of cuisine can people expect?
00:00:25 --> 00:00:32 Chef: We're doing modern American, but with an actual emphasis on local farms and sustainable practices.
```
**3. Intelligent Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the show!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It's great to be here.
00:00:06 --> 00:00:12 Interviewer: So, tell us a little bit bit about your recent restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Well, it has been a dream of mine for, like, years, you already know? To open a spot that actually focuses on seasonal ingredients.
00:00:20 --> 00:00:25 Interviewer: And what sort of cuisine can people expect?
00:00:25 --> 00:00:32 Chef: We're doing modern American, but with, like, an actual emphasis on local farms and, you already know, sustainable practices.
```
**4. Summary Transcription:**
```
Chef discusses their recent restaurant, "The Golden Spoon," which focuses on seasonal ingredients and modern American cuisine with an emphasis on local farms and sustainable practices.
```
**5. SRT File (for Captions):**
```
1
00:00:00,000 --> 00:00:03,000
Interviewer: So, Chef, welcome to the show!
2
00:00:03,000 --> 00:00:06,000
Chef: Thanks for having me. It's great to be here.
3
00:00:06,000 --> 00:00:12,000
Interviewer: So, tell us a little bit bit about your recent restaurant, "The Golden Spoon."
4
00:00:12,000 --> 00:00:20,000
Chef: Well, it has been a dream of mine for years to open a spot that actually focuses on seasonal ingredients.
5
00:00:20,000 --> 00:00:25,000
Interviewer: And what sort of cuisine can people expect?
6
00:00:25,000 --> 00:00:32,000
Chef: We're doing modern American, but with an actual emphasis on local farms and sustainable practices.
```
**Key Differences:**
* **Verbatim:** Captures every detail, including imperfections in speech.
* **Clean Verbatim:** Focuses on clarity and readability by removing unnecessary elements.
* **Intelligent Verbatim:** A balance between accuracy and readability.
* **Summary:** Provides a concise overview.
* **SRT:** A structured file format for displaying captions synchronized with the video.
The most effective form of transcription is determined by the particular needs of the project. For legal or research purposes, a verbatim transcription may be crucial. For general accessibility or marketing purposes, a clean verbatim or intelligent verbatim transcription is commonly preferred. Summary transcriptions are useful for quickly understanding the content of a video. SRT files are essential for adding captions to videos.------------------------------- end of response --------------------------------Up to now, we’ve seen the next:
- We didn’t manage to get the complete transcription with identified speakers abruptly
- Order matters (because a generated token influences the possibilities for subsequent tokens)
To tackle our challenge, we want Gemini to infer from the next multimodal information:
- text (our instructions + what could also be written within the video)
- audio cues (all the things said or audible within the video’s audio)
- visual cues (all the things visible within the video)
- time (when things occur)
That is kind of a combination of knowledge types!
As video transcription is an information extraction use case, if we expect concerning the outcome as a database, our final goal may be seen because the generation of two related tables (transcripts and speakers). If we write it down, our initial three sub-problems now look decoupled:
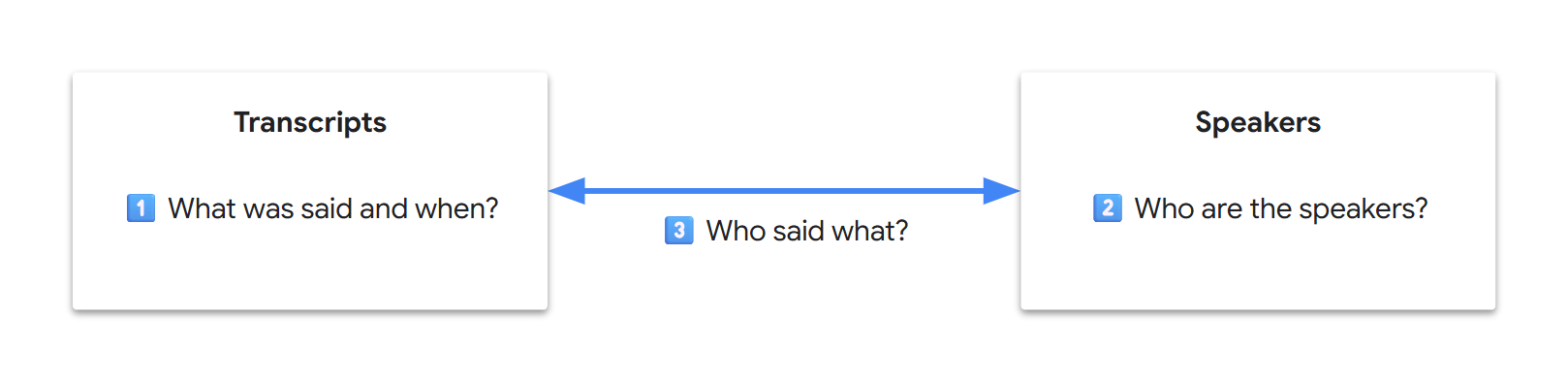
💡 In computer science, data decoupling enhances data locality, often yielding improved performance across areas akin to cache utilization, data access, semantic understanding, or system maintenance. Throughout the LLM Transformer architecture, core performance relies heavily on the eye mechanism. Nonetheless, the eye pool is finite and tokens compete for attention. Researchers sometimes check with “attention dilution” for long-context, million-token-scale benchmarks. While we cannot directly debug LLMs as users, intuitively, data decoupling may improve the model’s focus, resulting in a greater attention span.
Since Gemini is incredibly good with patterns, it could mechanically generate identifiers to link our tables. As well as, since we eventually want an automatic workflow, we will start reasoning when it comes to data and fields:

Let’s call this approach “tabular extraction”, split our instructions into two tasks (tables), still in a single request, and arrange them in a meaningful order…
💬 Transcripts
To begin with, let’s deal with getting the audio transcripts:
- Gemini has proven to be natively good at audio transcription
- This requires less inference than image evaluation
- It's central and independent information
💡 Generating an output that starts with correct answers should help to realize an overall correct output.
We’ve also seen what a typical transcription entry can appear to be:
00:02 speaker_1: Welcome!But, instantly, there may be some ambiguities in our multimodal use case:
- What's a speaker?
- Is it someone we see/hear?
- What if the person visible within the video shouldn't be the one speaking?
- What if the person speaking isn't seen within the video?
How will we unconsciously discover who's speaking in a video?
- First, probably by identifying different voices on the fly?
- Then, probably by consolidating additional audio and visual cues?
Can Gemini understand voice characteristics?
prompt = """
Using only the video's audio, list the next audible characteristics:
- Voice tones
- Voice pitches
- Languages
- Accents
- Speaking styles
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(prompt, video, show_as=ShowAs.MARKDOWN)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,730
Output tokens : 168
------------------------------ start of response -------------------------------Okay, here's a breakdown of the audible characteristics within the video's audio:
- **Voice Tones:** The tones range from conversational and friendly to more serious and thoughtful. There are also moments of pleasure and humor.
- **Voice Pitches:** There's a mixture of high and low pitches, depending on the speaker. The feminine speakers are inclined to have higher pitches, while the male speakers have lower pitches.
- **Languages:** The first language is English.
- **Accents:** There are a number of accents, including British, American, and possibly others which might be harder to pinpoint without more context.
- **Speaking Styles:** The speaking styles vary from formal and skilled (like in an interview setting) to more casual and conversational. Some speakers are more articulate and precise, while others are more relaxed.------------------------------- end of response --------------------------------What a couple of French video?
video = TestVideo.BRUT_FR_DOGS_WATER_LEAK_PT8M28S
generate_content(prompt, video, show_as=ShowAs.MARKDOWN)-------------- BRUT_FR_DOGS_WATER_LEAK_PT8M28S / gemini-2.0-flash --------------
Input tokens : 144,055
Output tokens : 147
------------------------------ start of response -------------------------------Here's a breakdown of the audible characteristics within the video, based on the audio:
* **Languages:** Primarily French.
* **Accents:** French accents are present, with some variations depending on the speaker.
* **Voice Tones:** The voice tones vary depending on the speaker and the context. Some are conversational and informative, while others are more enthusiastic and inspiring, especially when interacting with the dogs.
* **Voice Pitches:** The voice pitches vary depending on the speaker and the context.
* **Speaking Styles:** The speaking styles vary depending on the speaker and the context. Some are conversational and informative, while others are more enthusiastic and inspiring, especially when interacting with the dogs.------------------------------- end of response --------------------------------⚠️ We have now to be cautious here: responses can consolidate multimodal information and even general knowledge. For instance, if an individual is legendary, their name is more than likely a part of the LLM’s knowledge. In the event that they are known to be from the UK, a possible inference is that they've a British accent. For this reason we made our prompt more specific by including “using only the video’s audio”.
💡 For those who conduct more tests, for instance on private audio files (i.e., not a part of common knowledge and with no additional visual cues), you’ll see that Gemini’s audio tokenizer performs exceptionally well and extracts semantic speech information!
After just a few iterations, we will arrive at a transcription prompt specializing in the audio and voices:
prompt = """
Task:
- Watch the video and listen fastidiously to the audio.
- Discover each unique voice using a `voice` ID (1, 2, 3, etc.).
- Transcribe the video's audio verbatim with voice diarization.
- Include the `start` timecode (MM:SS) for every speech segment.
- Output a JSON array where each object has the next fields:
- `start`
- `text`
- `voice`
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(prompt, video, show_as=ShowAs.MARKDOWN)Output 🔽
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,800
Output tokens : 635
------------------------------ start of response -------------------------------[
{
"start": "00:00",
"text": "Do I have to call you Sir Demis now?",
"voice": 1
},
{
"start": "00:01",
"text": "Oh, you don't. Absolutely not.",
"voice": 2
},
{
"start": "00:03",
"text": "Welcome to Google Deep Mind the podcast with me, your host Professor Hannah Fry.",
"voice": 1
},
{
"start": "00:06",
"text": "We want to take you to the heart of where these ideas are coming from. We want to introduce you to the people who are leading the design of our collective future.",
"voice": 1
},
{
"start": "00:19",
"text": "Getting the safety right is probably, I'd say, one of the most important challenges of our time. I want safe and capable.",
"voice": 3
},
{
"start": "00:26",
"text": "I want a bridge that will not collapse.",
"voice": 3
},
{
"start": "00:30",
"text": "just give these scientists a superpower that they had not imagined earlier.",
"voice": 4
},
{
"start": "00:34",
"text": "autonomous vehicles. It's hard to fathom that when you're working on a search engine.",
"voice": 5
},
{
"start": "00:38",
"text": "We may see entirely new genre or entirely new forms of art come up. There may be a new word that is not music, painting, photography, movie making, and that AI will have helped us create it.",
"voice": 6
},
{
"start": "00:48",
"text": "You really want AGI to be able to peer into the mysteries of the universe.",
"voice": 1
},
{
"start": "00:51",
"text": "Yes, quantum mechanics, string theory, well, and the nature of reality.",
"voice": 2
},
{
"start": "00:55",
"text": "Ow.",
"voice": 1
},
{
"start": "00:56",
"text": "the magic of AI.",
"voice": 6
}
]------------------------------- end of response --------------------------------That is looking good! And should you test these instructions on more complex videos, you’ll get similarly promising results.
Notice how the prompt reuses cherry-picked terms from the terminology previously provided by Gemini, while aiming for precision and concision:
verbatimis unambiguous (unlike “spoken words”)1, 2, 3, etc.is an ellipsis (Gemini can infer the pattern)timecodeis restricted (timestamphas more meanings)MM:SSclarifies the timecode format
💡 Gemini 2.0 was trained to know the particular
MM:SStimecode format. Gemini 2.5 also supports theH:MM:SSformat for longer videos. For the most recent updates, check with the video understanding documentation.
We’re halfway there. Let’s complete our database generation with a second task…
🧑 Speakers
The second task is pretty straightforward: we would like to extract speaker information right into a second table. The 2 tables are logically linked by the voice ID.
After just a few iterations, we will reach a two-task prompt like the next:
prompt = """
Generate a JSON object with keys `task1_transcripts` and `task2_speakers` for the next tasks.
**Task 1 - Transcripts**
- Watch the video and listen fastidiously to the audio.
- Discover each unique voice using a `voice` ID (1, 2, 3, etc.).
- Transcribe the video's audio verbatim with voice diarization.
- Include the `start` timecode (MM:SS) for every speech segment.
- Output a JSON array where each object has the next fields:
- `start`
- `text`
- `voice`
**Task 2 - Speakers**
- For every `voice` ID from Task 1, extract information concerning the corresponding speaker.
- Use visual and audio cues.
- If a speaker's name can't be found, use a matter mark (`?`) as the worth.
- Output a JSON array where each object has the next fields:
- `voice`
- `name`
JSON:
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(prompt, video, show_as=ShowAs.MARKDOWN)Output 🔽
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,920
Output tokens : 806
------------------------------ start of response -------------------------------{
"task1_transcripts": [
{
"start": "00:00",
"text": "Do I have to call you Sir Demis now?",
"voice": 1
},
{
"start": "00:01",
"text": "Oh, you don't. Absolutely not.",
"voice": 2
},
{
"start": "00:04",
"text": "Welcome to Google Deep Mind the podcast with me, your host Professor Hannah Fry.",
"voice": 1
},
{
"start": "00:06",
"text": "We want to take you to the heart of where these ideas are coming from. We want to introduce you to the people who are leading the design of our collective future.",
"voice": 1
},
{
"start": "00:19",
"text": "Getting the safety right is probably, I'd say, one of the most important challenges of our time. I want safe and capable.",
"voice": 3
},
{
"start": "00:26",
"text": "I want a bridge that will not collapse.",
"voice": 3
},
{
"start": "00:30",
"text": "That just give these scientists a superpower that they had not imagined earlier.",
"voice": 4
},
{
"start": "00:34",
"text": "autonomous vehicles. It's hard to fathom that when you're working on a search engine.",
"voice": 5
},
{
"start": "00:38",
"text": "We may see entirely new genre or entirely new forms of art come up. There may be a new word that is not music, painting, photography, movie making, and that AI will have helped us create it.",
"voice": 6
},
{
"start": "00:48",
"text": "You really want AGI to be able to peer into the mysteries of the universe.",
"voice": 1
},
{
"start": "00:51",
"text": "Yes, quantum mechanics, string theory, well, and the nature of reality.",
"voice": 2
},
{
"start": "00:55",
"text": "Ow.",
"voice": 1
},
{
"start": "00:56",
"text": "the magic of AI.",
"voice": 6
}
],
"task2_speakers": [
{
"voice": 1,
"name": "Professor Hannah Fry"
},
{
"voice": 2,
"name": "Demis Hassabis"
},
{
"voice": 3,
"name": "Anca Dragan"
},
{
"voice": 4,
"name": "Pushmeet Kohli"
},
{
"voice": 5,
"name": "Jeff Dean"
},
{
"voice": 6,
"name": "Douglas Eck"
}
]
}------------------------------- end of response --------------------------------Test this prompt on more complex videos: it’s still looking good!
🚀 Finalization
🧩 Structured output
We’ve iterated towards a precise and concise prompt. Now, we will deal with Gemini’s response:
- The response is obvious text containing fenced code blocks
- As a substitute, we’d like a structured output, to receive consistently formatted responses
- Ideally, we’d also wish to avoid having to parse the response, which could be a maintenance burden
Getting structured outputs is an LLM feature also called “controlled generation”. Since we’ve already crafted our prompt when it comes to data tables and JSON fields, that is now a formality.
In our request, we will add the next parameters:
response_mime_type="application/json"response_schema="YOUR_JSON_SCHEMA"(docs)
In Python, this gets even easier:
- Use the
pydanticlibrary - Reflect your output structure with classes derived from
pydantic.BaseModel
We will simplify the prompt by removing the output specification parts:
Generate a JSON object with keys `task1_transcripts` and `task2_speakers` for the next tasks.
…
- Output a JSON array where each object has the next fields:
- `start`
- `text`
- `voice`
…
- Output a JSON array where each object has the next fields:
- `voice`
- `name`… to maneuver them to matching Python classes as an alternative:
import pydantic
class Transcript(pydantic.BaseModel):
start: str
text: str
voice: int
class Speaker(pydantic.BaseModel):
voice: int
name: str
class VideoTranscription(pydantic.BaseModel):
task1_transcripts: list[Transcript] = pydantic.Field(default_factory=list)
task2_speakers: list[Speaker] = pydantic.Field(default_factory=list)… and request a structured response:
response = client.models.generate_content(
# …
config=GenerateContentConfig(
# …
response_mime_type="application/json",
response_schema=VideoTranscription,
# …
),
)Finally, retrieving the objects from the response can also be direct:
if isinstance(response.parsed, VideoTranscription):
video_transcription = response.parsed
else:
video_transcription = VideoTranscription() # Empty transcriptionThe interesting features of this approach are the next:
- The prompt focuses on the logic and the classes deal with the output
- It’s easier to update and maintain typed classes
- The JSON schema is mechanically generated by the Gen AI SDK from the category provided in
response_schemaand dispatched to Gemini - The response is mechanically parsed by the Gen AI SDK and deserialized into the corresponding Python objects
⚠️ For those who keep output specifications in your prompt, ensure there are not any contradictions between the prompt and the schema (e.g., same field names and order), as this may negatively impact the standard of the responses.
💡 It’s possible to have more structural information directly within the schema (e.g., detailed field definitions). See Controlled generation.
✨ Implementation
Let’s finalize our code. As well as, now that we have now a stable prompt, we will even enrich our solution to extract each speaker’s company, position, and role_in_video:
Final code 🔽
import re
import pydantic
from google.genai.types import MediaResolution, ThinkingConfig
SamplingFrameRate = float
VIDEO_TRANSCRIPTION_PROMPT = """
**Task 1 - Transcripts**
- Watch the video and listen fastidiously to the audio.
- Discover each unique voice using a `voice` ID (1, 2, 3, etc.).
- Transcribe the video's audio verbatim with voice diarization.
- Include the `start` timecode ({timecode_spec}) for every speech segment.
**Task 2 - Speakers**
- For every `voice` ID from Task 1, extract information concerning the corresponding speaker.
- Use visual and audio cues.
- If a bit of knowledge can't be found, use a matter mark (`?`) as the worth.
"""
NOT_FOUND = "?"
class Transcript(pydantic.BaseModel):
start: str
text: str
voice: int
class Speaker(pydantic.BaseModel):
voice: int
name: str
company: str
position: str
role_in_video: str
class VideoTranscription(pydantic.BaseModel):
task1_transcripts: list[Transcript] = pydantic.Field(default_factory=list)
task2_speakers: list[Speaker] = pydantic.Field(default_factory=list)
def get_generate_content_config(model: Model, video: Video) -> GenerateContentConfig:
media_resolution = get_media_resolution_for_video(video)
thinking_config = get_thinking_config(model)
return GenerateContentConfig(
temperature=DEFAULT_CONFIG.temperature,
top_p=DEFAULT_CONFIG.top_p,
seed=DEFAULT_CONFIG.seed,
response_mime_type="application/json",
response_schema=VideoTranscription,
media_resolution=media_resolution,
thinking_config=thinking_config,
)
def get_video_duration(video: Video) -> timedelta | None:
# For testing purposes, video duration is statically laid out in the enum name
# Suffix (ISO 8601 based): _PT[H][M][S]
# For production,
# - fetch durations dynamically or store them individually
# - take note of video VideoMetadata.start_offset & VideoMetadata.end_offset
= r"_PT(?:(d+)H)?(?:(d+)M)?(?:(d+)S)?$"
if not (match := re.search(, video.name)):
print(f"⚠️ No duration info in {video.name}. Will use defaults.")
return None
h_str, m_str, s_str = match.groups()
return timedelta(
hours=int(h_str) if h_str shouldn't be None else 0,
minutes=int(m_str) if m_str shouldn't be None else 0,
seconds=int(s_str) if s_str shouldn't be None else 0,
)
def get_media_resolution_for_video(video: Video) -> MediaResolution | None:
if not (video_duration := get_video_duration(video)):
return None # Default
# For testing purposes, this relies on video duration, as our short videos are inclined to be more detailed
less_than_five_minutes = video_duration < timedelta(minutes=5)
if less_than_five_minutes:
media_resolution = MediaResolution.MEDIA_RESOLUTION_MEDIUM
else:
media_resolution = MediaResolution.MEDIA_RESOLUTION_LOW
return media_resolution
def get_sampling_frame_rate_for_video(video: Video) -> SamplingFrameRate | None:
sampling_frame_rate = None # Default (1 FPS for current models)
# [Optional] Define a custom FPS: 0.0 < sampling_frame_rate <= 24.0
return sampling_frame_rate
def get_timecode_spec_for_model_and_video(model: Model, video: Video) -> str:
timecode_spec = "MM:SS" # Default
match model:
case Model.GEMINI_2_0_FLASH: # Supports MM:SS
pass
case Model.GEMINI_2_5_FLASH | Model.GEMINI_2_5_PRO: # Support MM:SS and H:MM:SS
duration = get_video_duration(video)
one_hour_or_more = duration shouldn't be None and timedelta(hours=1) <= duration
if one_hour_or_more:
timecode_spec = "MM:SS or H:MM:SS"
case _:
assert False, "Add timecode format for new model"
return timecode_spec
def get_thinking_config(model: Model) -> ThinkingConfig | None:
# Examples of considering configurations (Gemini 2.5 models)
match model:
case Model.GEMINI_2_5_FLASH: # Considering disabled
return ThinkingConfig(thinking_budget=0, include_thoughts=False)
case Model.GEMINI_2_5_PRO: # Minimum considering budget and no summarized thoughts
return ThinkingConfig(thinking_budget=128, include_thoughts=False)
case _:
return None # Default
def get_video_transcription_from_response(
response: GenerateContentResponse,
) -> VideoTranscription:
if not isinstance(response.parsed, VideoTranscription):
print("❌ Couldn't parse the JSON response")
return VideoTranscription() # Empty transcription
return response.parsed
def get_video_transcription(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
prompt: str | None = None,
model: Model | None = None,
) -> VideoTranscription:
model = model or Model.DEFAULT
model_id = model.value
fps = fps or get_sampling_frame_rate_for_video(video)
video_part = get_video_part(video, video_segment, fps)
if not video_part: # Unsupported source, return an empty transcription
return VideoTranscription()
if prompt is None:
timecode_spec = get_timecode_spec_for_model_and_video(model, video)
prompt = VIDEO_TRANSCRIPTION_PROMPT.format(timecode_spec=timecode_spec)
contents = [video_part, prompt.strip()]
config = get_generate_content_config(model, video)
print(f" {video.name} / {model_id} ".center(80, "-"))
response = None
for attempt in get_retrier():
with attempt:
response = client.models.generate_content(
model=model_id,
contents=contents,
config=config,
)
display_response_info(response)
assert isinstance(response, GenerateContentResponse)
return get_video_transcription_from_response(response) Test it:
def test_structured_video_transcription(video: Video) -> None:
transcription = get_video_transcription(video)
print("-" * 80)
print(f"Transcripts : {len(transcription.task1_transcripts):3d}")
print(f"Speakers : {len(transcription.task2_speakers):3d}")
for speaker in transcription.task2_speakers:
print(f"- {speaker}")
test_structured_video_transcription(TestVideo.GDM_PODCAST_TRAILER_PT59S)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,917
Output tokens : 989
--------------------------------------------------------------------------------
Transcripts : 13
Speakers : 6
- voice=1 name='Professor Hannah Fry' company='Google DeepMind' position='Host' role_in_video='Host'
- voice=2 name='Demis Hassabis' company='Google DeepMind' position='Co-Founder & CEO' role_in_video='Interviewee'
- voice=3 name='Anca Dragan' company='?' position='Director, AI Safety & Alignment' role_in_video='Interviewee'
- voice=4 name='Pushmeet Kohli' company='?' position='VP Science & Strategic Initiatives' role_in_video='Interviewee'
- voice=5 name='Jeff Dean' company='?' position='Chief Scientist' role_in_video='Interviewee'
- voice=6 name='Douglas Eck' company='?' position='Senior Research Director' role_in_video='Interviewee'📊 Data visualization
We began prototyping in natural language, crafted a prompt, and generated a structured output. Since reading raw data may be cumbersome, we will now present video transcriptions in a more visually appealing way.
Here’s a possible orchestrator function:
def transcribe_video(video: Video, …) -> None:
display_video(video)
transcription = get_video_transcription(video, …)
display_speakers(transcription)
display_transcripts(transcription)Let’s add some data visualization functions 🔽
import itertools
from collections.abc import Callable, Iterator
from pandas import DataFrame, Series
from pandas.io.formats.style import Styler
from pandas.io.formats.style_render import CSSDict
BGCOLOR_COLUMN = "bg_color" # Hidden column to store row background colours
def yield_known_speaker_color() -> Iterator[str]:
PAL_40 = ("#669DF6", "#EE675C", "#FCC934", "#5BB974")
PAL_30 = ("#8AB4F8", "#F28B82", "#FDD663", "#81C995")
PAL_20 = ("#AECBFA", "#F6AEA9", "#FDE293", "#A8DAB5")
PAL_10 = ("#D2E3FC", "#FAD2CF", "#FEEFC3", "#CEEAD6")
PAL_05 = ("#E8F0FE", "#FCE8E6", "#FEF7E0", "#E6F4EA")
return itertools.cycle([*PAL_40, *PAL_30, *PAL_20, *PAL_10, *PAL_05])
def yield_unknown_speaker_color() -> Iterator[str]:
GRAYS = ["#80868B", "#9AA0A6", "#BDC1C6", "#DADCE0", "#E8EAED", "#F1F3F4"]
return itertools.cycle(GRAYS)
def get_color_for_voice_mapping(speakers: list[Speaker]) -> dict[int, str]:
known_speaker_color = yield_known_speaker_color()
unknown_speaker_color = yield_unknown_speaker_color()
mapping: dict[int, str] = {}
for speaker in speakers:
if speaker.name != NOT_FOUND:
color = next(known_speaker_color)
else:
color = next(unknown_speaker_color)
mapping[speaker.voice] = color
return mapping
def get_table_styler(df: DataFrame) -> Styler:
def join_styles(styles: list[str]) -> str:
return ";".join(styles)
table_css = [
"color: #202124",
"background-color: #BDC1C6",
"border: 0",
"border-radius: 0.5rem",
"border-spacing: 0px",
"outline: 0.5rem solid #BDC1C6",
"margin: 1rem 0.5rem",
]
th_css = ["background-color: #E8EAED"]
th_td_css = ["text-align:left", "padding: 0.25rem 1rem"]
table_styles = [
CSSDict(selector="", props=join_styles(table_css)),
CSSDict(selector="th", props=join_styles(th_css)),
CSSDict(selector="th,td", props=join_styles(th_td_css)),
]
return df.style.set_table_styles(table_styles).hide()
def change_row_bgcolor(row: Series) -> list[str]:
style = f"background-color:{row[BGCOLOR_COLUMN]}"
return [style] * len(row)
def display_table(yield_rows: Callable[[], Iterator[list[str]]]) -> None:
data = yield_rows()
df = DataFrame(columns=next(data), data=data)
styler = get_table_styler(df)
styler.apply(change_row_bgcolor, axis=1)
styler.hide([BGCOLOR_COLUMN], axis="columns")
html = styler.to_html()
IPython.display.display(IPython.display.HTML(html))
def display_speakers(transcription: VideoTranscription) -> None:
def sanitize_field(s: str, symbol_if_unknown: str) -> str:
return symbol_if_unknown if s == NOT_FOUND else s
def yield_rows() -> Iterator[list[str]]:
yield ["voice", "name", "company", "position", "role_in_video", BGCOLOR_COLUMN]
color_for_voice = get_color_for_voice_mapping(transcription.task2_speakers)
for speaker in transcription.task2_speakers:
yield [
str(speaker.voice),
sanitize_field(speaker.name, NOT_FOUND),
sanitize_field(speaker.company, NOT_FOUND),
sanitize_field(speaker.position, NOT_FOUND),
sanitize_field(speaker.role_in_video, NOT_FOUND),
color_for_voice.get(speaker.voice, "red"),
]
display_markdown(f"### Speakers ({len(transcription.task2_speakers)})")
display_table(yield_rows)
def display_transcripts(transcription: VideoTranscription) -> None:
def yield_rows() -> Iterator[list[str]]:
yield ["start", "speaker", "transcript", BGCOLOR_COLUMN]
color_for_voice = get_color_for_voice_mapping(transcription.task2_speakers)
speaker_for_voice = {
speaker.voice: speaker for speaker in transcription.task2_speakers
}
previous_voice = None
for transcript in transcription.task1_transcripts:
current_voice = transcript.voice
speaker_label = ""
if speaker := speaker_for_voice.get(current_voice, None):
if speaker.name != NOT_FOUND:
speaker_label = speaker.name
elif speaker.position != NOT_FOUND:
speaker_label = f"[voice {current_voice}][{speaker.position}]"
elif speaker.role_in_video != NOT_FOUND:
speaker_label = f"[voice {current_voice}][{speaker.role_in_video}]"
if not speaker_label:
speaker_label = f"[voice {current_voice}]"
yield [
transcript.start,
speaker_label if current_voice != previous_voice else '"',
transcript.text,
color_for_voice.get(current_voice, "red"),
]
previous_voice = current_voice
display_markdown(f"### Transcripts ({len(transcription.task1_transcripts)})")
display_table(yield_rows)
def transcribe_video(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
prompt: str | None = None,
model: Model | None = None,
) -> None:
display_video(video)
transcription = get_video_transcription(video, video_segment, fps, prompt, model)
display_speakers(transcription)
display_transcripts(transcription)✅ Challenge accomplished
🎬 Short video
This video is a trailer for the Google DeepMind podcast. It includes a fast-paced montage of 6 interviews. The multimodal transcription is great:
transcribe_video(TestVideo.GDM_PODCAST_TRAILER_PT59S)Video (source)
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Input tokens : 16,917
Output tokens : 989Speakers (6)

Transcripts (13)

🎬 Narrator-only video
This video is a documentary that takes viewers on a virtual tour of the Gombe National Park in Tanzania. There’s no visible speaker. Jane Goodall is appropriately detected because the narrator, her name is extracted from the credits:
transcribe_video(TestVideo.JANE_GOODALL_PT2M42S)Video (source)
------------------- JANE_GOODALL_PT2M42S / gemini-2.0-flash --------------------
Input tokens : 46,324
Output tokens : 717Speakers (1)

Transcripts (14)

💡 Over the past few years, I even have usually used this video to check specialized ML models and it consistently resulted in various kinds of errors. Gemini’s transcription, including punctuation, is ideal.
🎬 French video
This French reportage combines on-the-ground footage of a specialized team that uses trained dogs to detect leaks in underground drinking water pipes. The recording takes place entirely outdoors in a rural setting. The interviewed staff are introduced with on-screen text overlays. The audio, captured survive location, includes ambient noise. There are also some off-screen or unidentified speakers. This video is relatively complex. The multimodal transcription provides excellent results with no false positives:
transcribe_video(TestVideo.BRUT_FR_DOGS_WATER_LEAK_PT8M28S)Video (source)
-------------- BRUT_FR_DOGS_WATER_LEAK_PT8M28S / gemini-2.0-flash --------------
Input tokens : 46,514
Output tokens : 4,924Speakers (14)

Transcripts (61)

💡 Our prompt was crafted and tested with English videos, but works without modification with this French video. It must also work for videos in these 100+ different languages.
💡 In a multilingual solution, we'd ask to translate our transcriptions into any of those 100+ languages and even perform text cleanup. This may be done in a second request, because the multimodal transcription is complex enough by itself.
💡 Gemini’s audio tokenizer detects greater than speech. For those who attempt to list non-speech sounds on audio tracks only (to make sure the response doesn’t profit from any visual cues), you’ll see it could detect sounds akin to “dog bark”, “music”, “sound effect”, “footsteps”, “laughter”, “applause”…
💡 In our data visualization tables, coloured rows are inference positives (speakers identified by the model), while gray rows correspond to negatives (unidentified speakers). This makes it easier to know the outcomes. Because the prompt we crafted favors accuracy over recall, coloured rows are generally correct, and grey rows correspond either to unnamed/unidentifiable speakers (true negatives) or to speakers that ought to have been identified (false negatives).
🎬 Complex video
This Google DeepMind video is kind of complex:
- It is extremely edited and really dynamic
- Speakers are sometimes off-screen and other people may be visible as an alternative
- The researchers are sometimes in groups and it’s not at all times obvious who’s speaking
- Some video shots were taken 2 years apart: the identical speakers can sound and look different!
Gemini 2.0 Flash generates a superb transcription despite the complexity. Nevertheless, it's more likely to list duplicate speakers because of the video type. Gemini 2.5 Pro provides a deeper inference and manages to consolidate the speakers:
transcribe_video(
TestVideo.GDM_ALPHAFOLD_PT7M54S,
model=Model.GEMINI_2_5_PRO,
)Video (source)
-------------------- GDM_ALPHAFOLD_PT7M54S / gemini-2.5-pro --------------------
Input tokens : 43,354
Output tokens : 4,861
Thoughts tokens: 80Speakers (11)

Transcripts (81)

🎬 Long transcription
The overall length of the transcribed text can quickly reach the utmost variety of output tokens. With our current JSON response schema, we will reach 8,192 output tokens (supported by Gemini 2.0) with transcriptions of ~25min videos. Gemini 2.5 models support as much as 65,536 output tokens (8x more) and allow us to transcribe longer videos.
For this 54-minute panel discussion, Gemini 2.5 Pro uses only ~30-35% of the input/output token limits:
transcribe_video(
TestVideo.GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S,
model=Model.GEMINI_2_5_PRO,
)Video (source)
------------ GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S / gemini-2.5-pro -------------
Input tokens : 297,153
Output tokens : 22,896
Thoughts tokens: 65Speakers (14)

Transcripts (593)

💡 On this long video, the five panelists are appropriately transcribed, diarized, and identified. Within the second half of the video, unseen attendees ask inquiries to the panel. They're appropriately identified as audience members and, though their names and firms are never written on the screen, Gemini appropriately extracts and even consolidates the data from the audio cues.
🎬 1h+ video
In the most recent Google I/O keynote video (1h 10min):
- ~30-35%% of the token limit is used (383k/1M in, 20/64k out)
- The dozen speakers are nicely identified, including the demo “AI Voices” (“Gemini” and “Casey”)
- Speaker names are extracted from slanted text on the background screen for the live keynote speakers (e.g., Josh Woodward at 0:07) and from lower-third on-screen text within the DolphinGemma reportage (e.g., Dr. Denise Herzing at 1:05:28)
transcribe_video(
TestVideo.GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S,
model=Model.GEMINI_2_5_PRO,
)Video (source)
-------------- GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S / gemini-2.5-pro ---------------
Input tokens : 382,699
Output tokens : 19,772
Thoughts tokens: 75Speakers (14)

Transcripts (201)

🎬 40 speaker video
On this 1h 40min Google Cloud Next keynote video:
- ~50-70% of the token limit is used (547k/1M in, 45/64k out)
- 40 distinct voices are diarized
- 29 speakers are identified, connected to their 21 respective corporations or divisions
- The transcription takes as much as 8 minutes (roughly 4 minutes with video tokens cached), which is 13 to 23 times faster than watching the whole video without pauses.
transcribe_video(
TestVideo.GOOGLE_CLOUD_NEXT_PT1H40M03S,
model=Model.GEMINI_2_5_PRO,
)Video (source)
---------------- GOOGLE_CLOUD_NEXT_PT1H40M03S / gemini-2.5-pro -----------------
Input tokens : 546,590
Output tokens : 45,398
Thoughts tokens: 74Speakers (40)

Transcripts (853)

⚖️ Strengths & weaknesses
👍 Strengths
Overall, Gemini is able to generating excellent transcriptions that surpass human-generated ones in these features:
- Consistency of the transcription
- Perfect grammar and punctuation
- Impressive semantic understanding
- No typos or transcription system mistakes
- Exhaustivity (every audible word is transcribed)
💡 As you already know, a single incorrect/missing word (and even letter) can completely change the meaning. These strengths help ensure high-quality transcriptions and reduce the chance of misunderstandings.
If we compare YouTube’s user-provided transcriptions (sometimes by skilled caption vendors) to our auto-generated ones, we will observe some significant differences. Listed below are some examples from the last test:
| timecode | ❌ user-provided | ✅ our transcription |
|---|---|---|
| 9:47 | research and models | research and model |
| 13:32 | used by 100,000 businesses | used by over 100,000 businesses |
| 18:19 | infrastructure core layer | infrastructure core for AI |
| 20:21 | hardware system | hardware generation |
| 23:42 | I do deployed ML models | Toyota deployed ML models |
| 34:17 | Vertex video | Vertex Media |
| 41:11 | speed up app development | speed up application coding and development |
| 42:15 | performance and proven insights | performance improvement insights |
| 50:20 | across the milt agent ecosystem | across the multi-agent ecosystem |
| 52:50 | Salesforce, and Dun | Salesforce, or Dun |
| 1:22:28 | please almost | Please welcome |
| 1:31:07 | organizations, like I say Charles | organizations like Charles |
| 1:33:23 | multiple public LOMs | multiple public LLMs |
| 1:33:54 | Gemini’s Agent tech AI | Gemini’s agentic AI |
| 1:34:24 | mitigated outsider risk | mitigated insider risk |
| 1:35:58 | from end point, viral, networks | from endpoint, firewall, networks |
| 1:38:45 | We at Google are | We at Google Cloud are |
👎 Weaknesses
The present prompt shouldn't be perfect though. It focuses first on the audio for transcription after which on all cues for speaker data extraction. Though Gemini natively ensures a really high consolidation from the context, the prompt can show these unintended effects:
- Sensitivity to speakers’ pronunciation or accent
- Misspellings for correct nouns
- Inconsistencies between transcription and perfectly identified speaker name
Listed below are examples from the identical test:
| timecode | ✅ user-provided | ❌ our transcription |
|---|---|---|
| 3:31 | Bosun | Boson |
| 3:52 | Imagen | Imagine |
| 3:52 | Veo | VO |
| 11:15 | Berman | Burman |
| 25:06 | Huang | Wang |
| 38:58 | Allegiant Stadium | Allegiance Stadium |
| 1:29:07 | Snyk | Sneak |
We’ll stop our exploration here and leave it as an exercise, but listed here are possible ways to repair these errors, so as of simplicity/cost:
- Update the prompt to make use of visual cues for correct nouns, akin to
- Enrich the prompt with a further preliminary table to extract the correct nouns and use them explicitly within the context
- Add available video context metadata within the prompt
- Split the prompt into two successive requests
📈 Suggestions & optimizations
🔧 Model selection
Each model can differ when it comes to performance, speed, and value.
Here’s a practical summary based on the model specifications, our video test suite, and the present prompt:
| Model | Performance | Speed | Cost | Max. input tokens | Max. output tokens | Video type |
|---|---|---|---|---|---|---|
| Gemini 2.0 Flash | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | 1,048,576 = 1M |
8,192 = 8k |
Standard video, as much as 25min |
| Gemini 2.5 Flash | ⭐⭐ | ⭐⭐ | ⭐⭐ | 1,048,576 = 1M |
65,536 = 64k |
Standard video, 25min+ |
| Gemini 2.5 Pro | ⭐⭐⭐ | ⭐ | ⭐ | 1,048,576 = 1M |
65,536 = 64k |
Complex video or 1h+ video |
🔧 Video segment
You don’t at all times need to research videos from start to complete. You'll be able to indicate a video segment with start and/or end offsets within the VideoMetadata structure.
In this instance, Gemini will only analyze the 30:00-50:00 segment of the video:
video_metadata = VideoMetadata(
start_offset="1800.0s",
end_offset="3000.0s",
…
)🔧 Media resolution
In our test suite, the videos are fairly standard. We got excellent results by utilizing a “low” media resolution (“medium” being the default), specified with the GenerateContentConfig.media_resolution parameter.
💡 This provides faster and cheaper inferences, while also enabling the evaluation of 3x longer videos.
We used a straightforward heuristic based on video duration, but you may need to make it dynamic on a per-video basis:
def get_media_resolution_for_video(video: Video) -> MediaResolution | None:
if not (video_duration := get_video_duration(video)):
return None # Default
# For testing purposes, this relies on video duration, as our short videos are inclined to be more detailed
less_than_five_minutes = video_duration < timedelta(minutes=5)
if less_than_five_minutes:
media_resolution = MediaResolution.MEDIA_RESOLUTION_MEDIUM
else:
media_resolution = MediaResolution.MEDIA_RESOLUTION_LOW
return media_resolution⚠️ For those who select a “low” media resolution and experience an apparent lack of understanding, you may be losing necessary details within the sampled video frames. This is straightforward to repair: switch back to the default media resolution.
🔧 Sampling frame rate
The default sampling frame rate of 1 FPS worked high-quality in our tests. It is advisable to customize it for every video:
SamplingFrameRate = float
def get_sampling_frame_rate_for_video(video: Video) -> SamplingFrameRate | None:
sampling_frame_rate = None # Default (1 FPS for current models)
# [Optional] Define a custom FPS: 0.0 < sampling_frame_rate <= 24.0
return sampling_frame_rate💡 You'll be able to mix the parameters. On this extreme example, assuming the input video has a 24fps frame rate, all frames will probably be sampled for a 10s segment:
video_metadata = VideoMetadata(
start_offset="42.0s",
end_offset="52.0s",
fps=24.0,
)⚠️ For those who use a better sampling rate, this multiplies the variety of frames (and tokens) accordingly, increasing latency and value. As
10s × 24fps = 240 frames = 4×60s × 1fps, this 10-second evaluation at 24 FPS is similar to a 4-minute default evaluation at 1 FPS.
🎯 Precision vs recall
The prompt can influence the precision and recall of our data extractions, especially when using explicit versus implicit wording. For those who want more qualitative results, favor precision using explicit wording; should you want more quantitative results, favor recall using implicit wording:
| wording | favors | generates less | LLM behavior |
|---|---|---|---|
| explicit | precision | false positives | relies more (or only) on the provided context |
| implicit | recall | false negatives | relies on the general context, infers more, and may use its training knowledge |
Listed below are examples that may result in subtly different results:
| wording | verbs | qualifiers |
|---|---|---|
| explicit | “extract”, “quote” | “stated”, “direct”, “exact”, “verbatim” |
| implicit | “discover”, “deduce” | “found”, “indirect”, “possible”, “potential” |
💡 Different models may behave in another way for a similar prompt. Particularly, more performant models might sound more “confident” and make more implicit inferences or consolidations.
💡 For example, on this AlphaFold video, on the 04:57 timecode, “Spring 2020” is first displayed as context. Then, a brief declaration from “The Prime Minister” is heard within the background (“You need to stay at home”) without another hints. When asked to “discover” (relatively than “extract”) the speaker, Gemini is more likely to infer more and attribute the voice to “Boris Johnson”. There’s absolutely no explicit mention of Boris Johnson; his identity is appropriately inferred from the context (“UK”, “Spring 2020”, and “The Prime Minister”).
🏷️ Metadata
In our current tests, Gemini only uses audio and frame tokens, tokenized from sources on Google Cloud Storage or YouTube. If you may have additional video metadata, this could be a goldmine; try so as to add it to your prompt and enrich the video context for higher results upfront.
Potentially helpful metadata:
- Video description: This could provide a greater understanding of where and when the video was shot.
- Speaker info: This may help auto-correct names which might be only heard and never obvious to spell.
- Entity info: Overall, this may help improve transcriptions for custom or private data.
💡 For YouTube videos, no additional metadata or transcript is fetched. Gemini only receives the raw audio and video streams. You'll be able to check this yourself by comparing your results with YouTube’s automatic captioning (no punctuation, audio only) or user-provided transcripts (cleaned up), when available.
💡 For those who know your video concerns a team or an organization, adding internal data within the context may help correct or complete the requested speaker names (provided there are not any homonyms in the identical context), corporations, and job titles.
💡 On this French reportage, within the 06:16-06:31 video shot, there are two dogs: Arnold and Rio. “Arnold” is clearly audible, repeated thrice, and appropriately transcribed. “Rio” known as just once, audible for a fraction of a second in a loud environment, and the audio transcription can vary. Providing the names of the entire team (owners & dogs, even in the event that they usually are not all within the video) may help in transcribing this short name consistently.
💡 It must also be possible to ground the outcomes with Google Search, Google Maps, or your personal RAG system. See Grounding overview.
🔬 Debugging & evidence
Iterating through successive prompts and debugging LLM outputs may be difficult, especially when trying to know the explanations for the outcomes.
It’s possible to ask Gemini to supply evidence within the response. In our video transcription solution, we could request a timecoded “evidence” for every speaker’s identified name, company, or role. This permits linking results to their sources, discovering and understanding unexpected insights, checking potential false positives…
💡 Within the tested videos, when trying to know where the insights got here from, requesting evidence yielded very insightful explanations, for instance:
- Person names could possibly be extracted from various sources (video conference captions, badges, unseen participants introducing themselves when asking questions in a conference panel…)
- Company names could possibly be found from text on uniforms, backpacks, vehicles…
💡 In a document data extraction solution, we could request to supply an “excerpt” as evidence, including page number, chapter number, or another relevant location information.
🐘 Verbose JSON
The JSON format is currently probably the most common solution to generate structured outputs with LLMs. Nevertheless, JSON is a relatively verbose data format, as field names are repeated for every object. For instance, an output can appear to be the next, with many repeated underlying tokens:
{
"task1_transcripts": [
{ "start": "00:02", "text": "We've…", "voice": 1 },
{ "start": "00:07", "text": "But we…", "voice": 1 }
// …
],
"task2_speakers": [
{
"voice": 1,
"name": "John Moult",
"company": "University of Maryland",
"position": "Co-Founder, CASP",
"role_in_video": "Expert"
},
// …
{
"voice": 3,
"name": "Demis Hassabis",
"company": "DeepMind",
"position": "Founder and CEO",
"role_in_video": "Team Leader"
}
// …
]
}To optimize output size, an interesting possibility is to ask Gemini to generate an XML block containing a CSV for every of your tabular extractions. The sphere names are specified once within the header, and by utilizing tab separators, for instance, we will achieve more compact outputs like the next:
start text voice
00:02 We have… 1
00:07 But we… 1
…
voice name company position role_in_video
1 John Moult University of Maryland Co-Founder, CASP Expert
…
3 Demis Hassabis DeepMind Founder and CEO Team Leader
…
💡 Gemini excels at patterns and formats. Depending in your needs, be at liberty to experiment with JSON, XML, CSV, YAML, and any custom structured formats. It’s likely that the industry will evolve to permit much more elaborate structured outputs.
🐿️ Context caching
Context caching optimizes the price and the latency of repeated requests using the identical base inputs.
There are two ways requests can profit from context caching:
- Implicit caching: By default, upon the primary request, input tokens are cached, to speed up responses for subsequent requests with the identical base inputs. That is fully automated and no code change is required.
- Explicit caching: You place specific inputs into the cache and reuse this cached content as a base in your requests. This provides full control but requires managing the cache manually.
Example of implicit caching 🔽
model_id = "gemini-2.0-flash"
video_file_data = FileData(
file_uri="gs://bucket/path/to/my-video.mp4",
mime_type="video/mp4",
)
video = Part(file_data=video_file_data)
prompt_1 = "List the people visible within the video."
prompt_2 = "Summarize what happens to John Smith."
# ✅ Request A1: static data (video) placed first
response = client.models.generate_content(
model=model_id,
contents=,
)
# ✅ Request A2: likely cache hit for the video tokens
response = client.models.generate_content(
model=model_id,
contents=,
)💡 Implicit caching may be disabled on the project level (see data governance).
Implicit caching is prefix-based, so it only works should you put static data first and variable data last.
Example of requests stopping implicit caching 🔽
# ❌ Request B1: variable input placed first
response = client.models.generate_content(
model=model_id,
contents=[prompt_1, video],
)
# ❌ Request B2: no cache hit
response = client.models.generate_content(
model=model_id,
contents=[prompt_2, video],
)💡 This explains why the data-plus-instructions input order is preferred, for performance (not LLM-related) reasons.
Cost-wise, the input tokens retrieved with a cache hit profit from a 75% discount in the next cases:
- Implicit caching: With all Gemini models, cache hits are mechanically discounted (with none control on the cache).
- Explicit caching: With all Gemini models and supported models in Model Garden, you control your cached inputs and their lifespans to make sure cache hits.
Example of explicit caching 🔽
from google.genai.types import (
Content,
CreateCachedContentConfig,
FileData,
GenerateContentConfig,
Part,
)
model_id = "gemini-2.0-flash-001"
# Input video
video_file_data = FileData(
file_uri="gs://cloud-samples-data/video/JaneGoodall.mp4",
mime_type="video/mp4",
)
video_part = Part(file_data=video_file_data)
video_contents = [Content(role="user", parts=[video_part])]
# Video explicitly put in cache, with time-to-live (TTL) before automatic deletion
cached_content = client.caches.create(
model=model_id,
config=CreateCachedContentConfig(
ttl="1800s",
display_name="video-cache",
contents=video_contents,
),
)
if cached_content.usage_metadata:
print(f"Cached tokens: {cached_content.usage_metadata.total_token_count or 0:,}")
# Cached tokens: 46,171
# ✅ Video tokens are cached (standard tokenization rate + storage cost for TTL duration)
cache_config = GenerateContentConfig(cached_content=cached_content.name)
# Request #1
response = client.models.generate_content(
model=model_id,
contents="List the people mentioned within the video.",
config=cache_config,
)
if response.usage_metadata:
print(f"Input tokens : {response.usage_metadata.prompt_token_count or 0:,}")
print(f"Cached tokens: {response.usage_metadata.cached_content_token_count or 0:,}")
# Input tokens : 46,178
# Cached tokens: 46,171
# ✅ Cache hit (75% discount)
# Request #i (inside the TTL period)
# …
# Request #n (inside the TTL period)
response = client.models.generate_content(
model=model_id,
contents="List all of the timecodes when Jane Goodall is mentioned.",
config=cache_config,
)
if response.usage_metadata:
print(f"Input tokens : {response.usage_metadata.prompt_token_count or 0:,}")
print(f"Cached tokens: {response.usage_metadata.cached_content_token_count or 0:,}")
# Input tokens : 46,182
# Cached tokens: 46,171
# ✅ Cache hit (75% discount)💡 Explicit caching needs a selected model version (like
…-001in this instance) to make sure the cache stays valid and shouldn't be affected by a model update.
ℹ️ Learn more about Context caching.
⏳ Batch prediction
If you might want to process a big volume of videos and don’t need synchronous responses, you should use a single batch request and reduce your cost.
💡 Batch requests for Gemini models get a 50% discount compared to plain requests.
ℹ️ Learn more about Batch prediction.
♾️ To production… and beyond
A couple of additional notes:
- The present prompt shouldn't be perfect and may be improved. It has been preserved in its current state as an instance its development starting with Gemini 2.0 Flash and a straightforward video test suite.
- The Gemini 2.5 models are more capable and intrinsically provide a greater video understanding. Nevertheless, the present prompt has not been optimized for them. Writing optimal prompts for various models is one other challenge.
- For those who test transcribing your personal videos, especially various kinds of videos, it's possible you'll run into recent or specific issues. They'll probably be addressed by enriching the prompt.
- Future models will likely support more output features. This could allow for richer structured outputs and for easier prompts.
- As models continue to learn, it’s also possible that multimodal video transcription will grow to be a one-liner prompt.
- Gemini’s image and audio tokenizers are truly impressive and enable many other use cases. To totally grasp the extent of the probabilities, you'll be able to run unit tests on images or audio files.
- We constrained our challenge to using a single request, which may dilute the LLM’s attention in such wealthy multimodal contexts. For optimal ends in a large-scale solution, splitting the processing into two steps (i.e., requests) should help Gemini’s attention focus even further. In step one, we’d extract and diarize the audio stream only, which should lead to probably the most precise speech-to-text transcription (perhaps with more voice identifiers than actual speakers, but with a minimal variety of false positives). Within the second step, we’d reinject the transcription to deal with extracting and consolidating speaker data from the video frames. This is able to even be an answer to process very long videos, even those several hours in duration.
🏁 Conclusion
Multimodal video transcription, which requires the complex synthesis of audio and visual data, is a real challenge for ML practitioners, without mainstream solutions. A standard approach, involving an elaborate pipeline of specialised models, can be engineering-intensive with none guarantee of success. In contrast, Gemini proved to be a flexible toolbox for reaching a strong and simple solution based on a single prompt:

We managed to handle this complex problem with the next techniques:
- Prototyping with open prompts to develop intuition about Gemini’s natural strengths
- Considering how LLMs work under the hood
- Crafting increasingly specific prompts using a tabular extraction strategy
- Generating structured outputs to maneuver towards production-ready code
- Adding data visualization for easier interpretation of responses and smoother iterations
- Adapting default parameters to optimize the outcomes
- Conducting more tests, iterating, and even enriching the extracted data
These principles should apply to many other data extraction domains and let you solve your personal complex problems. Rejoice and completely satisfied solving!