
Apple has published a thesis that the reasoning model will not be actually human. There was an issue over other researchers rebelled that there was an issue with the experiment. As well as, accusations of Apple behind AI focused on cutting off the outcomes of other firms.
Apple researchers indicate that the inferred ability of the massive language model (LLM) is currently a fundamental limit.The Illusion of Pondering ‘The paper was published.
This study is an evaluation of how well AI can solve puzzles equivalent to ‘Tower of Hanoi’ and ‘River Crossing’ beyond existing mathematics and coding benchmarks.
The researchers evaluated the problem of the issue by step by step increasing the problem of the issue, targeting representative reasoning models equivalent to open AI ‘O1’ and ‘O3’, Claude ‘3.7 Sonnet Sinking’, ‘Geminai Sinking’, and ‘Deep Chic-R1’. Experiments include the identical level of computer resources.
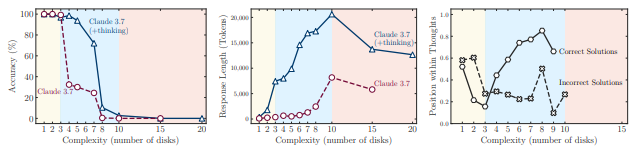
In accordance with the study, in easy tasks, the final LLM learned without reasoning showed more accurate and efficient performance. Nevertheless, as the issue went as much as the intermediate complexity, a model with structural reasoning methods equivalent to an accident chain (COT) began to point out its performance advantage.
But when the complexity exceeds the limit, each the reasoning and the final model didn’t answer. No matter the relief of the computational resources, accuracy plunged to 0%, and the issue solving ability disappeared.
As well as, as the problem of problem increases, a lot of the reasoning models have been in increasingly accident stages, but they’ve shown that the accident process is shorter when the critical point is reached. Although sufficient resources remain, the AI showed an abnormal behavior that looked as if it would stop an accident.
He also confirmed that the explanation for reasoning of the AI model depends greatly on the family. This shows that the model tends to resolve problems based on the familiarity of coaching data, relatively than the actual considering ability.
Apple concluded that “the present reasoning model doesn’t think like a human being, but a type of pattern matching,” he said. Due to this fact, it’s argued that the architecture and performance of the LLM will not be a technique to achieve artificial intelligence (AGI).
Nevertheless, the findings were known, and rebuttal and criticism were poured out.
Essentially the most widely known is the evaluation of an X (Twitter) user called ML researcher Lisan Al Gaib. He insisted that Apple researchers confused token budget failures with failure. In other words, puzzles equivalent to Hanoi’s tower are exponentially large, however the LLM context window is fixed, so even when the correct strategy is created, it’s indicated as an error.
Especially, the subsequent day ‘The Illusion of the Illusion of Pondering ‘A refutation paper appeared. It incorporates the argument that Give’s arguments, in addition to the community, refuted the Apple papers, and that Apple’s experimental design and the methodology used were fundamentally mistaken.
The paper is co -authored by AI researcher Alex Rosen and Antrovic, Claude Operus.
Some indicate that Apple papers were published in keeping with the World Developer Conference (WWDC).
It’s criticized that Apple, who lags behind AI studies and has not made a change within the event, was urgent to scale back the performance of other firms’ reasoning models.
By Park Chan, reporter cpark@aitimes.com