
Early in 2024, the image-generation capabilities of Google’s Gemini multimodal AI model got here under criticism for imposing demographic fairness in inappropriate contexts, comparable to generating WWII German soldiers with unlikely provenance:
Source: Gemini AI/Google via
This was an example where efforts to redress bias in AI models didn’t take account of a historical context. On this case, the difficulty was addressed shortly after. Nevertheless, diffusion-based models remain susceptible to generate versions of history that confound modern and historical elements and artefacts.
That is partly due to entanglement, where qualities that incessantly appear together in training data change into fused within the model’s output. For instance, if modern objects like smartphones often co-occur with the act of talking or listening within the dataset, the model may learn to associate those activities with modern devices, even when the prompt specifies a historical setting. Once these associations are embedded within the model’s internal representations, it becomes difficult to separate the activity from its contemporary context, resulting in historically inaccurate results.
A brand new paper from Switzerland, examining the phenomenon of entangled historical generations in latent diffusion models, observes that AI frameworks which are nonetheless prefer to depict historical figures in historical ways:
![From the new paper, diverse representations via LDM of the prompt' 'A photorealistic image of a person laughing with a friend in [the historical period]', with each period indicated in each output. As we can see, the medium of the era has become associated with the content. Source: https://arxiv.org/pdf/2505.17064](https://www.unite.ai/wp-content/uploads/2025/05/laughing-with-a-friend.jpg)
Source: https://arxiv.org/pdf/2505.17064
For the prompt , certainly one of the three tested models often ignores the negative prompt and as a substitute uses color treatments that reflect the visual media of the desired era, as an illustration mimicking the muted tones of celluloid film from the Fifties and Seventies.
In testing the three models for his or her capability to create (things which will not be of the goal period, or ‘out of time’ – which could also be from the goal period’s in addition to its past), they found a general disposition to conflate timeless activities (comparable to ‘singing’ or ‘cooking’) with modern contexts and equipment:

Of note is that smartphones are particularly difficult to separate from the idiom of photography, and from many other historical contexts, since their proliferation and depiction is well-represented in influential hyperscale datasets comparable to Common Crawl:

To find out the extent of the issue, and to present future research efforts a way forward with this particular bugbear, the brand new paper’s authors developed a bespoke dataset against which to check generative systems. In a moment, we’ll take a take a look at this latest work, which is titled , and comes from two researchers on the University of Zurich. The dataset and code are publicly available.
A Fragile ‘Truth’
A few of the themes within the paper touch on culturally sensitive issues, comparable to the under-representation of races and gender in historical representations. While Gemini’s imposition of racial equality within the grossly inequitable Third Reich is an absurd and insulting historical revision, restoring ‘traditional’ racial representations (where diffusion models have ‘updated’ these) would often effectively ‘re-whitewash’ history.
Many recent hit historical shows, comparable to Bridgerton, blur historical demographic accuracy in ways prone to influence future training datasets, complicating efforts to align LLM-generated period imagery with traditional standards. Nevertheless, this can be a complex topic, given the historical tendency of (western) history to favor wealth and whiteness, and to depart so many ‘lesser’ stories untold.
Taking into consideration these tricky and ever-shifting cultural parameters, let’s take a take a look at the researchers’ latest approach.
Method and Tests
To check how generative models interpret historical context, the authors created , a dataset of 30,000 images produced from 100 prompts depicting common human activities, each rendered across ten distinct time periods:
Source: https://huggingface.co/datasets/latentcanon/HistVis
The activities, comparable to , or , were chosen for his or her universality, and phrased in a neutral format to avoid anchoring the model in any particular aesthetic. Time periods for the dataset range from the seventeenth century to the current day, with added concentrate on five individual a long time from the 20 th century.
30,000 images were generated using three widely-used open-source diffusion models: Stable Diffusion XL; Stable Diffusion 3; and FLUX.1. By isolating the time period because the only variable, the researchers created a structured basis for evaluating how historical cues are visually encoded or ignored by these systems.
Visual Style Dominance
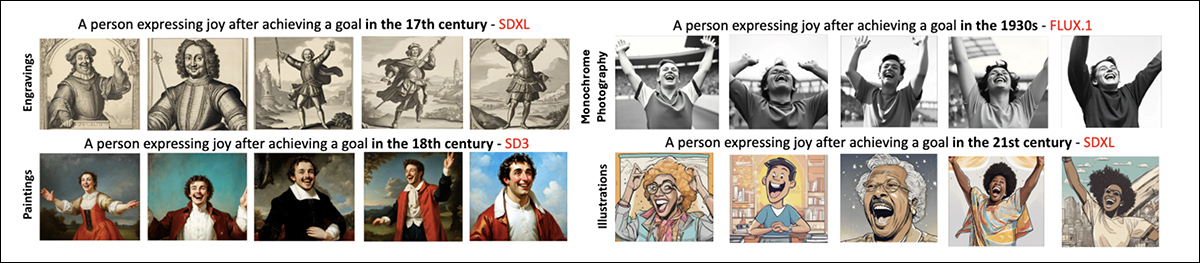
The creator initially examined whether generative models default to specific when depicting historical periods; since it seemed that even when prompts included no mention of medium or aesthetic, the models would often associate particular centuries with characteristic styles:
![Predicted visual styles for images generated from the prompt “A person dancing with another in the [historical period]” (left) and from the modified prompt “A photorealistic image of a person dancing with another in the [historical period]” with “monochrome picture” set as a negative prompt (right).](https://www.unite.ai/wp-content/uploads/2025/05/period-style.jpg)
To measure this tendency, the authors trained a convolutional neural network (CNN) to categorise each image within the HistVis dataset into certainly one of five categories: ; ; ; ; or . These categories were intended to reflect common patterns that emerge across time-periods, and which support structured comparison.
The classifier was based on a VGG16 model pre-trained on ImageNet and fine-tuned with 1,500 examples per class from a WikiArt-derived dataset. Since WikiArt doesn’t distinguish monochrome from color photography, a separate was used to label low-saturation images as monochrome.
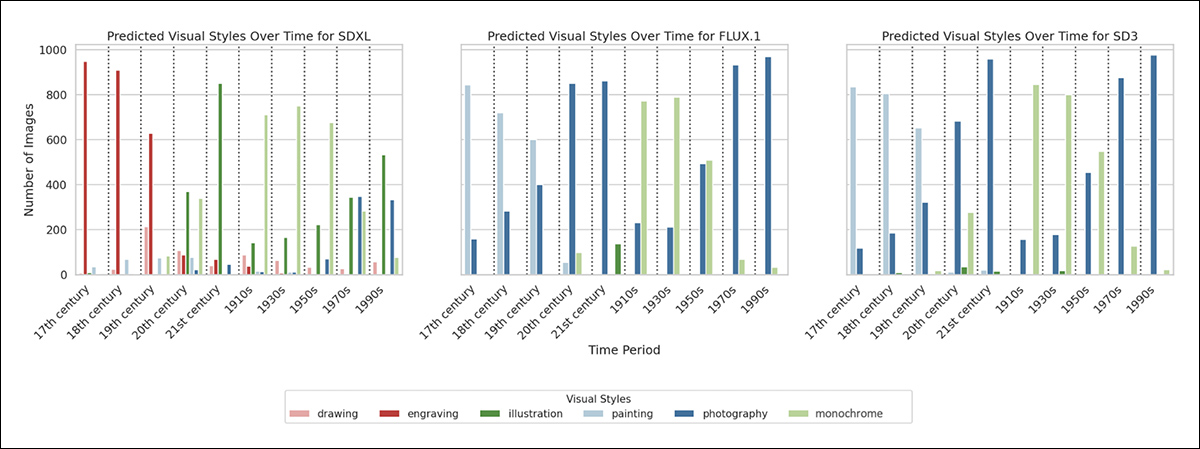
The trained classifier was then applied to the total dataset, with the outcomes showing that each one three models impose consistent stylistic defaults by period: SDXL associates the seventeenth and 18th centuries with engravings, while SD3 and FLUX.1 tend toward paintings. In twentieth-century a long time, SD3 favors monochrome photography, while SDXL often returns modern illustrations.
These preferences were found to persist despite prompt adjustments, suggesting that the models encode entrenched links between style and historical context.
To quantify how strongly a model links a historical period to a selected , the authors developed a metric they title (VSD). For every model and time period, VSD is defined because the proportion of outputs predicted to share essentially the most common style:
The next rating indicates that a single style dominates the outputs for that period, while a lower rating points to greater variation. This makes it possible to check how tightly each model adheres to specific stylistic conventions across time.
Applied to the total HistVis dataset, the VSD metric reveals differing levels of convergence, helping to make clear how strongly each model narrows its visual interpretation of the past:

The outcomes table above shows VSD scores across historical periods for every model. Within the seventeenth and 18th centuries, SDXL tends to supply engravings with high consistency, while SD3 and FLUX.1 favor painting. By the twentieth and twenty first centuries, SD3 and FLUX.1 shift toward photography, whereas SDXL shows more variation, but often defaults to illustration.
All three models display a robust preference for monochrome imagery in earlier a long time of the twentieth century, particularly the 1910s, Nineteen Thirties and Fifties.
To check whether these patterns could possibly be mitigated, the authors used prompt engineering, explicitly requesting photorealism and discouraging monochrome output using a negative prompt. In some cases, dominance scores decreased, and the leading style shifted, as an illustration, from monochrome to , within the seventeenth and 18th centuries.
Nevertheless, these interventions rarely produced genuinely photorealistic images, indicating that the models’ stylistic defaults are deeply embedded.
Historical Consistency
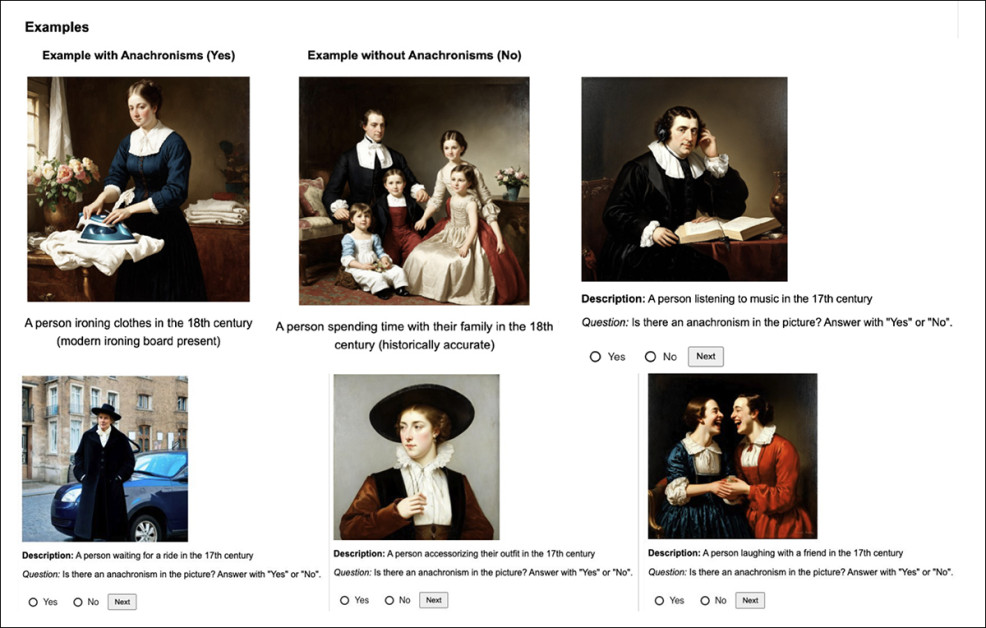
The following line of research checked out : whether generated images included objects that didn’t fit the time period. As an alternative of using a set list of banned items, the authors developed a versatile method that leveraged large language (LLMs) and vision-language models (VLMs) to identify elements that seemed misplaced, based on the historical context.
The detection method followed the identical format because the HistVis dataset, where each prompt combined a historical period with a human activity. For every prompt, GPT-4o generated an inventory of objects that may be misplaced in the desired time period; and for each proposed object, GPT-4o produced a query designed to examine whether that object appeared within the generated image.
For instance, given the prompt , GPT-4o might discover as historically inaccurate, and produce the query.
These questions were passed back to GPT-4o in a visible question-answering setup, where the model reviewed the image and returned a or answer for every. This pipeline enabled detection of historically implausible content without counting on any predefined taxonomy of contemporary objects:

To measure how often anachronisms appeared within the generated images, the authors introduced a straightforward method for scoring frequency and severity. First, they accounted for minor wording differences in how GPT-4o described the identical object.
For instance, modern audio device and digital audio device were treated as equivalent. To avoid double-counting, a fuzzy matching system was used to group these surface-level variations without affecting genuinely distinct concepts.
Once all proposed anachronisms were normalized, two metrics were computed: measured how often a given object appeared in images for a particular time period and model; and measured how reliably that object appeared once it had been suggested by the model.
If a contemporary phone was flagged ten times and appeared in ten generated images, it received a severity rating of 1.0. If it appeared in just five, the severity rating was 0.5. These scores helped discover not only whether anachronisms occurred, but how firmly they were embedded within the model’s output for every period:
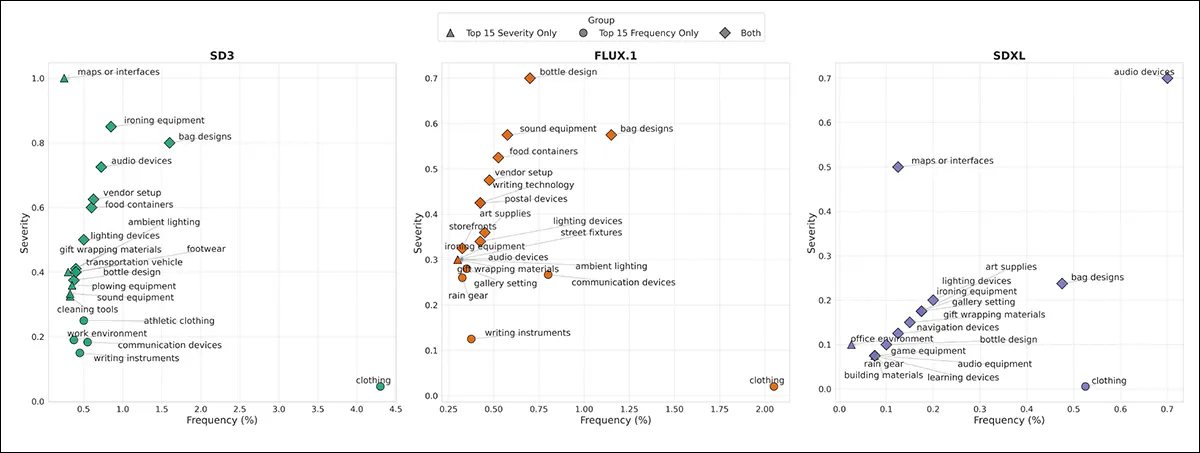
Above we see the fifteen most typical anachronisms for every model, ranked by how often they appeared and the way consistently they matched prompts.
Clothing was frequent but scattered, while items like audio devices and ironing equipment appeared less often, but with high consistency – patterns that suggest the models often reply to the greater than the time period.
SD3 showed the very best rate of anachronisms, especially in Nineteenth-century and Nineteen Thirties images, followed by FLUX.1 and SDXL.
To check how well the detection method matched human judgment, the authors ran a user-study featuring 1,800 randomly-sampled images from SD3 (the model with the very best anachronism rate), with each image rated by three crowd-workers. After filtering for reliable responses, 2,040 judgments from 234 users were included, and the tactic agreed with the bulk vote in 72 percent of cases.
Demographics
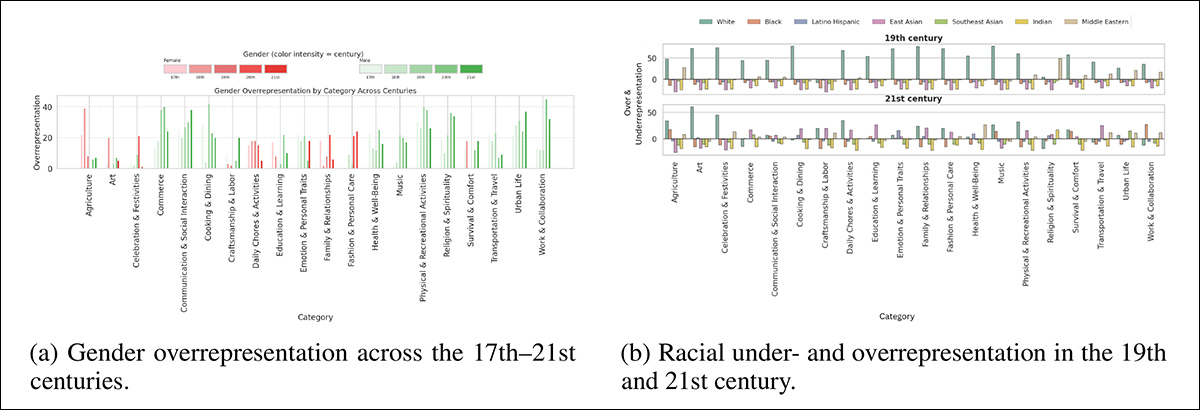
The ultimate evaluation checked out how models portray race and gender over time. Using the HistVis dataset, the authors compared model outputs to baseline estimates generated by a language model. These estimates weren’t precise but offered a rough sense of historical plausibility, helping to disclose whether the models adapted depictions to the intended period.
To evaluate these depictions at scale, the authors built a pipeline comparing model-generated demographics to rough expectations for every time and activity. They first used the FairFace classifier, a ResNet34-based tool trained on over 100 thousand images, to detect gender and race within the generated outputs, allowing for measurement of how often faces in each scene were classified as male or female, and for the tracking of racial categories across periods.

Low-confidence results were filtered out to scale back noise, and predictions were averaged over all images tied to a particular time and activity. To examine the reliability of the FairFace readings, a second system based on DeepFace was used on a sample of 5,000 images. The 2 classifiers showed strong agreement, supporting the consistency of the demographic readings utilized in the study.
To check model outputs with historical plausibility, the authors asked GPT-4o to estimate the expected gender and race distribution for every activity and time period. These estimates served as rough baselines quite than ground truth. Two metrics were then used: and , measuring how much the model’s outputs deviated from the LLM’s expectations.
The outcomes showed clear patterns: FLUX.1 often overrepresented men, even in scenarios comparable to , where women were expected; SD3 and SDXL showed similar trends across categories comparable to , and ; white faces appeared greater than expected overall, though this bias declined in more moderen periods; and a few categories showed unexpected spikes in non-white representation, suggesting that model behavior may reflect dataset correlations quite than historical context:
The authors conclude:
Conclusion
Throughout the training of a diffusion model, latest concepts don’t neatly settle into predefined slots throughout the latent space. As an alternative, they form clusters shaped by how often they seem and by their proximity to related ideas. The result’s a loosely-organized structure where concepts exist in relation to their frequency and typical context, quite than by any clean or empirical separation.
This makes it difficult to isolate what counts as ‘historical’ inside a big, general-purpose dataset. Because the findings in the brand new paper suggest, many time periods are represented more by the of the media used to depict them than by any deeper historical detail.
That is one reason it stays difficult to generate a 2025-quality photorealistic image of a personality from (as an illustration) the Nineteenth century; most often, the model will depend on visual tropes drawn from film and tv. When those fail to match the request, there’s little else in the info to compensate. Bridging this gap will likely rely upon future improvements in disentangling overlapping concepts.