
Studies have shown that the quantity of labor that the bogus intelligence (AI) system can handle doubles every seven months. Specifically, the recent acceleration and this trend concluded that AI could be answerable for a month after a number of years.
METR, a non -profit organization in the US, is on the 18th (local time) ‘Measurement of AI capability to finish a protracted taskThe paper was published in the net archive.
It is a benchmark for quantifying AI’s abilities based on human abilities. The AI model often calculates the work that could be performed at a 50%success rate as a time for humans to finish. In other words, it shows how well the AI model can handle a posh problem that an individual can solve for a very long time.
The researchers chosen greater than 170 actual tasks within the fields of coding, cyber security, general reasoning, and machine learning, after which measured the time it took for a human skilled programmer to finish it.
Then we tested the work capability of the AI model. Because of this, ‘GPT-2’, launched by Open AI in 2019, didn’t perform all of the tasks that human experts take a couple of minute.
Because of this of measuring the Task-Completion Time Horizon, which was released from 2019 to this 12 months, the performance of the AI model doubled every seven months.
Specifically, in 2024, exponential increased exponentially, and the newest models doubled every three months. Specifically, the state -of -the -art model ‘Claude 3.7 Sonnet’ released by Antropic in February has accomplished 50%of the 59 -minute work. It’s because the AI Agent’s ability has been greatly improved.
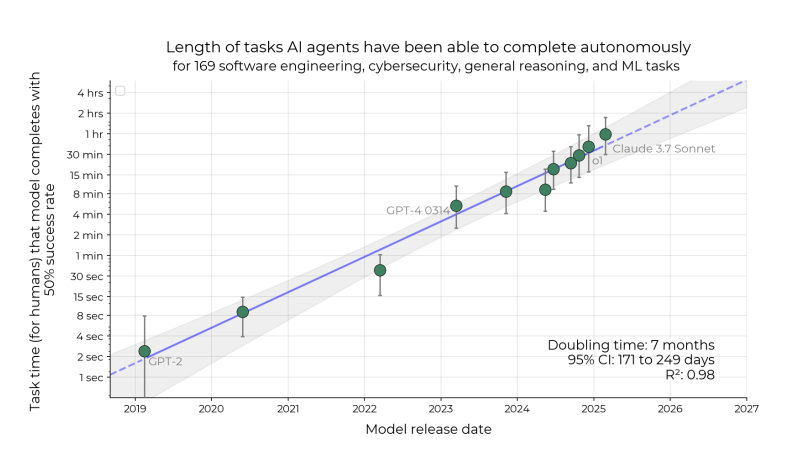
METR expects this speed to handle human work in 2029, which takes a few month. In other words, AI can conduct a monthly academic research or start -up work.
In fact, increasing the work success rate to 80%reduces the time range of labor that AI can handle. Nonetheless, the general increase trend is comparable to 50%. As well as, he said that he focused on improving awareness during his work, akin to logical reasoning, tools, and error modifications, in addition to physical amounts to define what could be handled.
Joshua Ganss, a professor on the University of Toronto, said, “The estimation is attractive, but it surely shouldn’t be very useful to clarify the complexity, akin to how AI is definitely used.”
Nonetheless, this study may complement among the problems in recent times. In other words, the benchmark is now narrow and the primary place is changing resulting from the advance of the model, but this method can express the long -term trend.
Ben West, co -author, said, “The leading AI model has achieved superhuman ends in many benchmarks, however the economic impact was relatively small.” “But the perfect model on this study was about 40 minutes, and there’s little achievement that humans could make economically during this time.”
METR said it’s going to proceed to check the AI system with humans.
By Dae -jun Lim, reporter ydj@aitimes.com