
A recent paper from LG AI Research suggests that supposedly ‘open’ datasets used for training AI models could also be offering a false sense of security – finding that almost 4 out of 5 AI datasets labeled as ‘commercially usable’ actually contain hidden legal risks.
Such risks range from the inclusion of undisclosed copyrighted material to restrictive licensing terms buried deep in a dataset’s dependencies. If the paper’s findings are accurate, firms counting on public datasets may have to reconsider their current AI pipelines, or risk legal exposure downstream.
The researchers propose a radical and potentially controversial solution: AI-based compliance agents able to scanning and auditing dataset histories faster and more accurately than human lawyers.
The paper states:
Examining 2,852 popular datasets that appeared commercially usable based on their individual licenses, the researchers’ automated system found that only 605 (around 21%) were actually legally protected for commercialization once all their components and dependencies were traced
The latest paper is titled , and comes from eight researchers at LG AI Research.
Rights and Wrongs
The authors highlight the challenges faced by firms pushing forward with AI development in an increasingly uncertain legal landscape – as the previous academic ‘fair use’ mindset around dataset training gives solution to a fractured environment where legal protections are unclear and protected harbor isn’t any longer guaranteed.
As one publication identified recently, firms have gotten increasingly defensive concerning the sources of their training data. Writer Adam Buick comments*:
Transparency generally is a disingenuous term – or just a mistaken one; as an illustration, Adobe’s flagship Firefly generative model, trained on stock data that Adobe had the rights to use, supposedly offered customers reassurances concerning the legality of their use of the system. Later, some evidence emerged that the Firefly data pot had develop into ‘enriched’ with potentially copyrighted data from other platforms.
As we discussed earlier this week, there are growing initiatives designed to guarantee license compliance in datasets, including one that can only scrape YouTube videos with flexible Creative Commons licenses.
The issue is that the licenses in themselves could also be erroneous, or granted in error, as the brand new research seems to point.
Examining Open Source Datasets
It’s difficult to develop an evaluation system corresponding to the authors’ Nexus when the context is continually shifting. Subsequently the paper states that the NEXUS Data Compliance framework system relies on ‘ various precedents and legal grounds at this cut-off date’.
NEXUS utilizes an AI-driven agent called for automated data compliance. AutoCompliance is comprised of three key modules: a navigation module for web exploration; a question-answering (QA) module for information extraction; and a scoring module for legal risk assessment.
. Source: https://arxiv.org/pdf/2503.02784
These modules are powered by fine-tuned AI models, including the EXAONE-3.5-32B-Instruct model, trained on synthetic and human-labeled data. AutoCompliance also uses a database for caching results to reinforce efficiency.
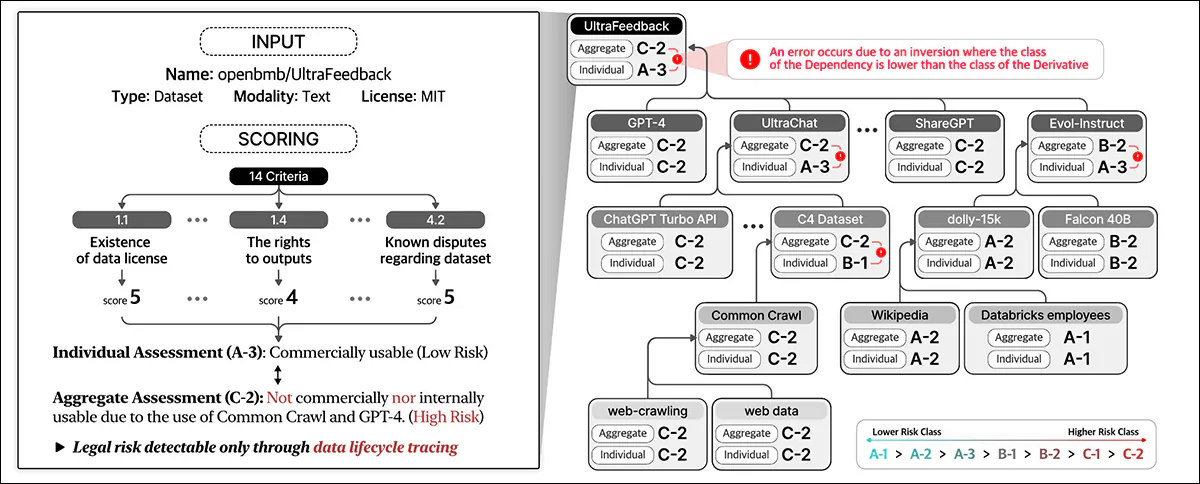
AutoCompliance starts with a user-provided dataset URL and treats it as the basis entity, looking for its license terms and dependencies, and recursively tracing linked datasets to construct a license dependency graph. Once all connections are mapped, it calculates compliance scores and assigns risk classifications.
The Data Compliance framework outlined in the brand new work identifies various† entity types involved in the information lifecycle, including , which form the core input for AI training; , that are used to rework and utilize the information; and , which facilitate data handling.
The system holistically assesses legal risks by considering these various entities and their interdependencies, moving beyond rote evaluation of the datasets’ licenses to incorporate a broader ecosystem of the components involved in AI development.
Training and Metrics
The authors extracted the URLs of the highest 1,000 most-downloaded datasets at Hugging Face, randomly sub-sampling 216 items to constitute a test set.
The EXAONE model was fine-tuned on the authors’ custom dataset, with the navigation module and question-answering module using synthetic data, and the scoring module using human-labeled data.
Ground-truth labels were created by five legal experts trained for at the least 31 hours in similar tasks. These human experts manually identified dependencies and license terms for 216 test cases, then aggregated and refined their findings through discussion.
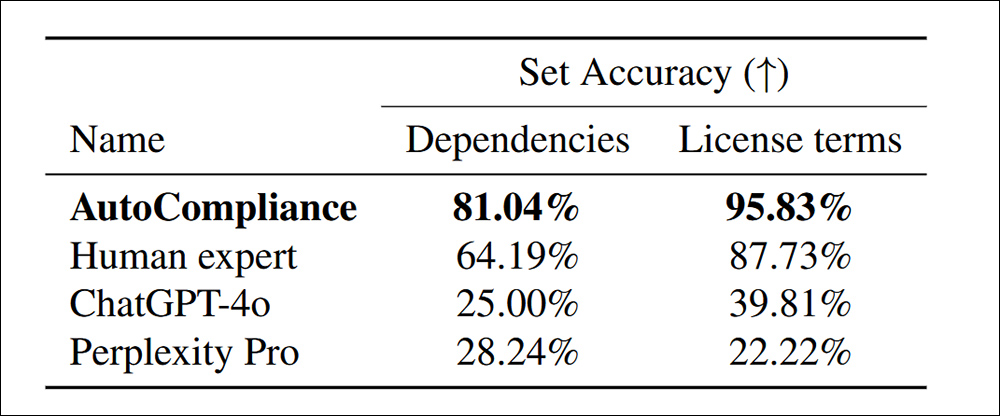
With the trained, human-calibrated AutoCompliance system tested against ChatGPT-4o and Perplexity Pro, notably more dependencies were discovered inside the license terms:
The paper states:
When it comes to efficiency, the AutoCompliance approach took just 53.1 seconds to run, in contrast to 2,418 seconds for equivalent human evaluation on the identical tasks.
Further, the evaluation run cost $0.29 USD, in comparison with $207 USD for the human experts. It needs to be noted, nonetheless, that this relies on renting a GCP a2-megagpu-16gpu node monthly at a rate of $14,225 per thirty days – signifying that this sort of cost-efficiency is said primarily to a large-scale operation.
Dataset Investigation
For the evaluation, the researchers chosen 3,612 datasets combining the three,000 most-downloaded datasets from Hugging Face with 612 datasets from the 2023 Data Provenance Initiative.
The paper states:
Copyrighted datasets can only be redistributed with legal authority, which can come from a license, copyright law exceptions, or contract terms. Unauthorized redistribution can result in legal consequences, including copyright infringement or contract violations. Subsequently clear identification of non-compliance is important.
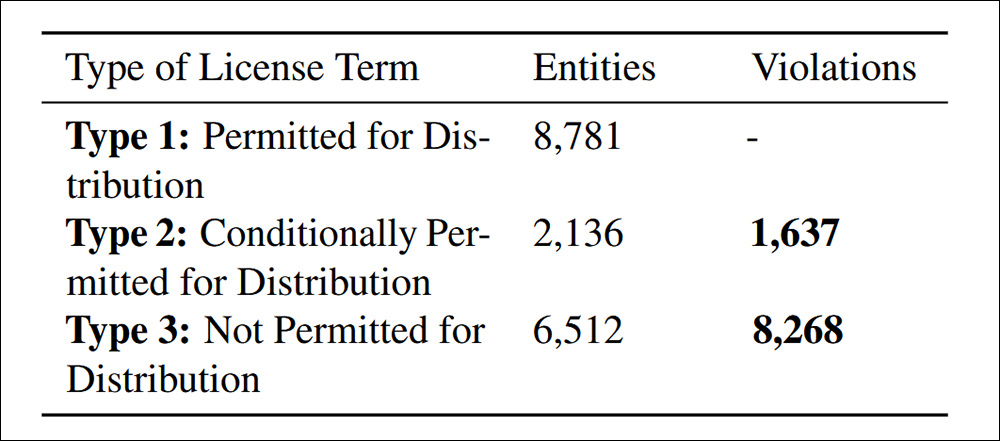
The study found 9,905 cases of non-compliant dataset redistribution, split into two categories: 83.5% were explicitly prohibited under licensing terms, making redistribution a transparent legal violation; and 16.5% involved datasets with conflicting license conditions, where redistribution was allowed in theory but which didn’t meet required terms, creating downstream legal risk.
The authors concede that the danger criteria proposed in NEXUS aren’t universal and will vary by jurisdiction and AI application, and that future improvements should concentrate on adapting to changing global regulations while refining AI-driven legal review.
Conclusion
It is a prolix and largely unfriendly paper, but addresses perhaps the most important retarding think about current industry adoption of AI – the likelihood that apparently ‘open’ data will later be claimed by various entities, individuals and organizations.
Under DMCA, violations can legally entail massive fines on a basis. Where violations can run into the hundreds of thousands, as within the cases discovered by the researchers, the potential legal liability is really significant.
Moreover, firms that might be proven to have benefited from upstream data cannot (as usual) claim ignorance as an excuse, at the least within the influential US market. Neither do they currently have any realistic tools with which to penetrate the labyrinthine implications buried in supposedly open-source dataset license agreements.
The issue in formulating a system corresponding to NEXUS is that it might be difficult enough to calibrate it on a per-state basis contained in the US, or a per-nation basis contained in the EU; the prospect of making a very global framework (a form of ‘Interpol for dataset provenance’) is undermined not only by the conflicting motives of the varied governments involved, however the indisputable fact that each these governments and the state of their current laws on this regard are continually changing.
*
†