
LG AI researchers have unveiled tools to discover the copyright problems with datasets used for artificial intelligence (AI) learning. In consequence of inspecting the present use of the utilization, only 21%will be used industrial.
LG AI Research Institute (Director Back Hoon -hoon) published the outcomes of a study on the AI agent system that tracks and analyzes the lifecycle of the training dataset utilized in the AI model on the homepage and uses the dataset to guage the chance aspects using the dataset. . It also unveiled a tool called ‘Nexus’, which may directly handle the outcomes analyzed by the AI agent.
The researcher identified that the event of AI technology indiscriminately utilized learning data, which caused an issue of reducing reliability, infringing unethical or infringing others’ rights.
Nonetheless, major AI learning datasets explained that it is extremely difficult for developers to attach with tens of 1000’s of individual data sources. As well as, since individual sources change fluidly, they should track the general life cycle with a view to understand the issue of the dataset.
To unravel this problem This studyWe developed dataset evaluation technology. The tool that implements it directly nexusall.
Certainly one of the fundamental technologies is that you may routinely analyze the complex parts of the dataset. It routinely detects conflicts, rights relationships, and private information that may occur at each stage, and provides service evaluation results.
As well as, the dataset is recognized as a form during which the dataset and individual information will not be a set of knowledge. Due to this fact, based on the understanding of individual information, the impact that will be on your complete dataset is identified.

The AI agent technology applied to the Nexus relies on the representative model ‘Exa One 3.5’. Specifically, ‘Navigation’ to go looking for web documents connected to the dataset ▲ ‘QA (Query-Answer) that analyzes documents and extracts relevant information ▲’ evaluation that judges the security of knowledge That is the results of combining three models.
For this reason technology, the work is greater than 45 times faster than human experts, and the associated fee could be very low cost at 700/700.
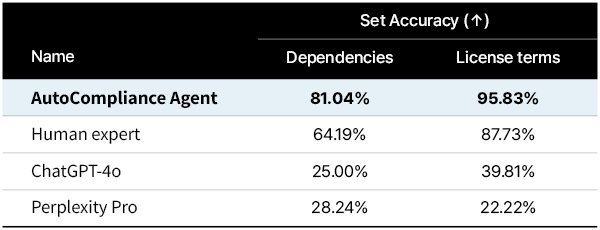
The accuracy can also be known to be very high. In consequence of evaluating 216 of the info sets downloaded greater than 1000 times from the Hugging Face, the dependency identification was 81%and the license identification was 95.8%. It is a figure that goes beyond other large language models (LLM).
In consequence, it’s explained that it may well be used quickly in various fields that require legitimacy review of datasets resembling industrial sites and research institutes.
Actually, the evaluation of legalism checks 18 major items, including authorization, data correction, and private information protection. In consequence, each item is split into seven stages from the safest grade to the very best level.
And consequently of surveying 3612 major datasets with this technology, it found that there was a wide selection of problems. Amongst these, many of the datasets are currently used.
More importantly, only 605 (21.21%) of the 2852 datasets that were judged to be commercially available as a consequence of the interconnection of the dataset were only 605 (21.21%).
The LG AI researcher said the goal is to expand the scope beyond the present 3612 datasets. It isn’t just quantitatively expanded, nevertheless it is to expand qualitatively by identifying correlation.
He also plans to cooperate with the worldwide AI community and experts to develop a world standard. This may confirm the reliability of the AI dataset and make it easier for developers to explore the datasets in line with the project.
Then again, it’s noteworthy that this study will be certainly one of the sensible solutions, with the EU’s AI regulatory law that the disclosure of knowledge sources and copyright issues have emerged because the sharpest problems.
It is because most AI corporations complain that it’s difficult to discover what the datasets they use are included.
By Dae -jun Lim, reporter ydj@aitimes.com