
Illon Musk’s XAI has launched the newest Frontier AI model ‘Gigok-3’ product.
This was trained on the planet’s largest AI data center, Colosus, and surpassed the ‘GPT-4O’ and ‘O3-Mini-High’ of the prevailing open AI, the strongest in the current benchmark. He also unveiled an reasoning agent called ‘Deepsearch’, equivalent to Open AI’s ‘Deep Research’.
XAI unveiled that rock-3 on the X (Twitter) streaming event on the seventeenth.
That Rock-3 is a multi-modal model (LMM) that can’t only do text but in addition image processing, and ▲ The smaller version of ‘Rock-3 Mini’ All 4 versions were released.
Amongst them, the reasoning model will be utilized in ‘Big Brain’ mode for reasoning that asks for ‘thought’ in that rock-3 or in tougher query.
As is thought, the deep book can be released to go looking the Web as a substitute of humans and write advanced answers through reasoning. This can be introduced into XAI’s corporate API with that rock-3 in a number of weeks.
That Rock-3 and Mini will start the service for subscribers of X’s Premium+$ 22. Other features are serviced through a plan of $ 30 per 30 days. Super Galok can use reasoning models and deep documents and offers unlimited image creation.
Specifically, the model trained with 10 GPUs within the Colossus of Memphis. Because of this, Musk predicted that the performance could be great for a number of months ago, and on today, the event emphasized that “Rock-3 is rather more competent than that rock-2.”
And this point was explained as a benchmark results.
To begin with, he scored 52 points in ‘AIME 2025’, which covers mathematics, and won 39 points of GPT-4O. As well as, ‘GPQA’, which tests a doctoral level of scientific knowledge, is 75 points, exceeding 65 points of GPT-4O. Within the coding ability test, it was 57 points, surpassing 40 points of Deep Chic-V3.
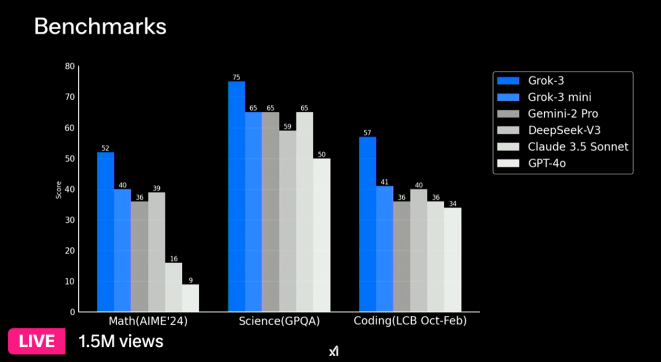
Nevertheless, it will not be known whether the open AI surpasses the update version of the GPT-4O released the day before. Open AI says the brand new GPT-4O has scored on the benchmark.
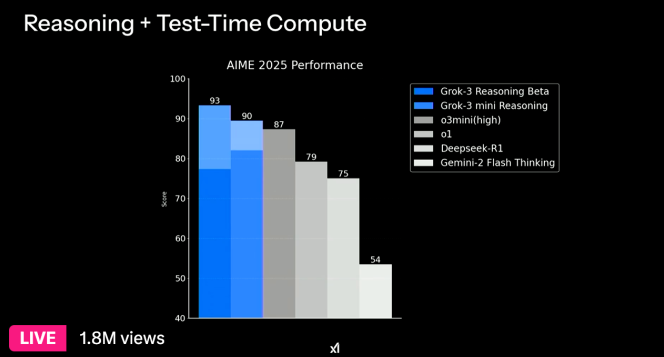
The Rock-3 reasoning model scored 93 points from AIME 2025. Here too, the O1 and O3-Mini-Hi’s 87.3 points and 79.6 points are over 79.6 points. Nevertheless, the rating of O1 and O3-Mini is a rating from AIME 2024, not AIME 2025.
As well as, ‘IM Arena Leader Board’, which ranks as a user preference, is the initial test version of GPT-4O and the newest version of the GPT-4O and the newest version of Geminai 2.0.
In consequence, as Musk said, “The neatest model on Earth,” he’s the perfect model at present. Along with the open AI model, each were ahead of Deep Chic.
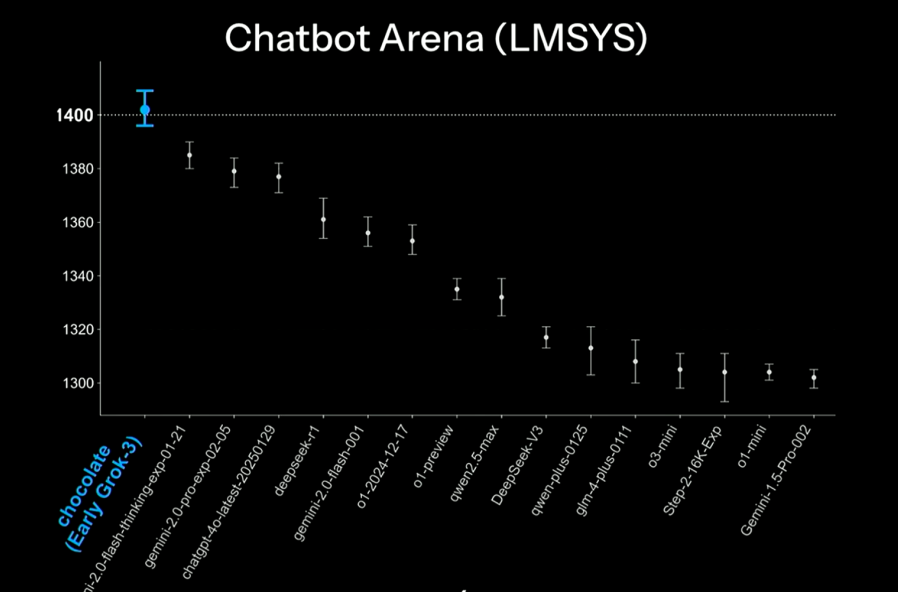
Nevertheless, it didn’t disclose the outcomes of the benchmark called ‘HLE’. On this benchmark, Deep Research, based on ‘O3’ of Open AI, is greater than twice ahead of other models with 26.6%accuracy.
As well as, the API usage fee, which has emerged as an enormous concern on account of deep chic, has not been disclosed.
Meanwhile, Musk also expressed its intention to upgrade that rock-3 to AI voice assistant. “In the following week, voice mode can be added to the app,” he said.
Following that green-1, he said that it would be released in an open source in a number of months. “We often open up the previous version as an open source when the following version is totally released.”
By Dae -jun Lim, reporter ydj@aitimes.com