
On this planet of machine learning, we obsess over model architectures, training pipelines, and hyper-parameter tuning, yet often overlook a fundamental aspect: how our features live and breathe throughout their lifecycle. From in-memory calculations that vanish after each prediction to the challenge of reproducing exact feature values months later, the best way we handle features could make or break our ML systems’ reliability and scalability.
Who Should Read This
- ML engineers evaluating their feature management approach
- Data scientists experiencing training-serving skew issues
- Technical leads planning to scale their ML operations
- Teams considering Feature Store implementation
Starting Point: The invisible approach
Many ML teams, especially those of their early stages or without dedicated ML engineers, start with what I call “the invisible approach” to feature engineering. It’s deceptively easy: fetch raw data, transform it in-memory, and create features on the fly. The resulting dataset, while functional, is basically a black box of short-lived calculations — features that exist just for a moment before vanishing after each prediction or training run.
While this approach might sound to get the job done, it’s built on shaky ground. As teams scale their ML operations, models that performed brilliantly in testing suddenly behave unpredictably in production. Features that worked perfectly during training mysteriously produce different values in live inference. When stakeholders ask why a particular prediction was made last month, teams find themselves unable to reconstruct the precise feature values that led to that call.
Core Challenges in Feature Engineering
These pain points aren’t unique to any single team; they represent fundamental challenges that each growing ML team eventually faces.
- Observability
Without materialized features, debugging becomes a detective mission. Imagine trying to know why a model made a particular prediction months ago, only to search out that the features behind that call have long since vanished. Features observability also enables continuous monitoring, allowing teams to detect deterioration or concerning trends of their feature distributions over time. - Time limit correctness
When features utilized in training don’t match those generated during inference, resulting in the notorious training-serving skew. This isn’t nearly data accuracy — it’s about ensuring your model encounters the identical feature computations in production because it did during training. - Reusability
Repeatedly computing the identical features across different models becomes increasingly wasteful. When feature calculations involve heavy computational resources, this inefficiency isn’t just an inconvenience — it’s a big drain on resources.
Evolution of Solutions
Approach 1: On-Demand Feature Generation
The only solution starts where many ML teams begin: creating features on demand for immediate use in prediction. Raw data flows through transformations to generate features, that are used for inference, and only then — after predictions are already made — are these features typically saved to parquet files. While this method is easy, with teams often selecting parquet files because they’re easy to create from in-memory data, it comes with limitations. The approach partially solves observability since features are saved, but analyzing these features later becomes difficult — querying data across multiple parquet files requires specific tools and careful organization of your saved files.
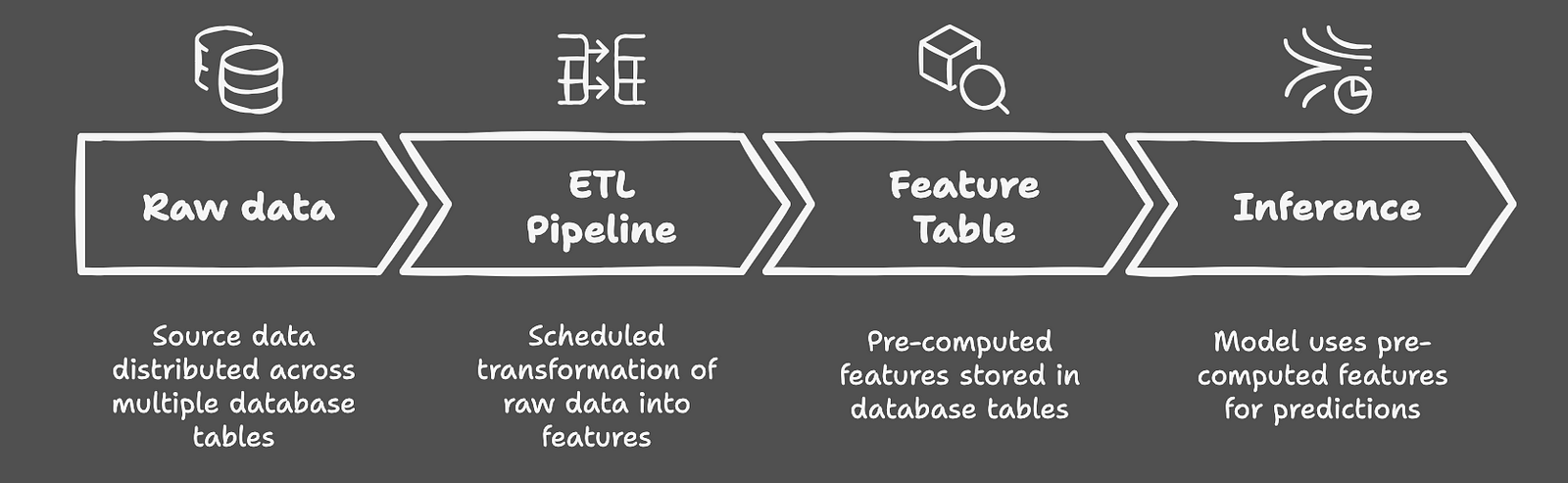
Approach 2: Feature Table Materialization
As teams evolve, many transition to what’s commonly discussed online as an alternative choice to full-fledged feature stores: feature table materialization. This approach leverages existing data warehouse infrastructure to rework and store features before they’re needed. Consider it as a central repository where features are consistently calculated through established ETL pipelines, then used for each training and inference. This solution elegantly addresses point-in-time correctness and observability — your features are all the time available for inspection and consistently generated. Nevertheless, it shows its limitations when coping with feature evolution. As your model ecosystem grows, adding recent features, modifying existing ones, or managing different versions becomes increasingly complex — especially on account of constraints imposed by database schema evolution.
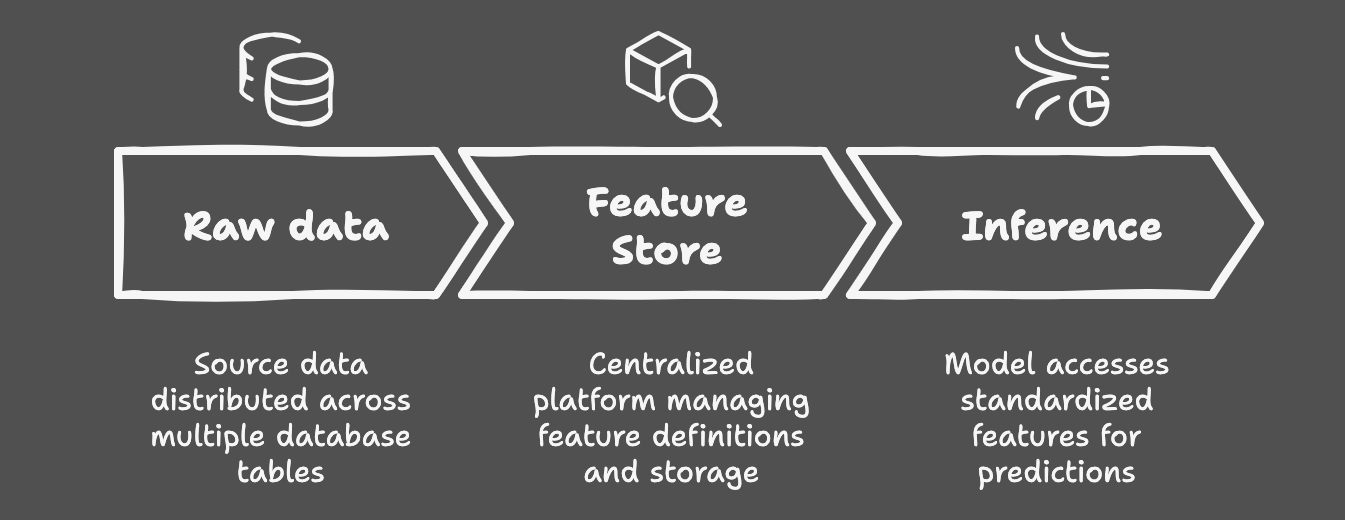
Approach 3: Feature Store
On the far end of the spectrum lies the feature store — typically a part of a comprehensive ML platform. These solutions offer the total package: feature versioning, efficient online/offline serving, and seamless integration with broader ML workflows. They’re the equivalent of a well-oiled machine, solving our core challenges comprehensively. Features are version-controlled, easily observable, and inherently reusable across models. Nevertheless, this power comes at a big cost: technological complexity, resource requirements, and the necessity for dedicated ML Engineering expertise.
Making the Right Selection
Contrary to what trending ML blog posts might suggest, not every team needs a feature store. In my experience, feature table materialization often provides the sweet spot — especially when your organization already has robust ETL infrastructure. The bottom line is understanding your specific needs: in case you’re managing multiple models that share and continuously modify features, a feature store may be well worth the investment. But for teams with limited model interdependence or those still establishing their ML practices, simpler solutions often provide higher return on investment. Sure, you follow on-demand feature generation — if debugging race conditions at 2 AM is your idea of a superb time.
The choice ultimately comes right down to your team’s maturity, resource availability, and specific use cases. Feature stores are powerful tools, but like several sophisticated solution, they require significant investment in each human capital and infrastructure. Sometimes, the pragmatic path of feature table materialization, despite its limitations, offers one of the best balance of capability and complexity.
Remember: success in ML feature management isn’t about selecting essentially the most sophisticated solution, but finding the best fit in your team’s needs and capabilities. The bottom line is to truthfully assess your needs, understand your limitations, and select a path that allows your team to construct reliable, observable, and maintainable ML systems.