
Apple has released a brand new benchmark tool that measures the actual capabilities of artificial intelligence (AI) in large language models (LLMs). The outcomes of testing major models showed that open source models are far behind closed ones. It is claimed that the performance of open source models has improved lots recently, but the cruel reality is revealed when only the benchmark is replaced.
VentureBeat reported on the twelfth (local time) that Apple researchers have developed a brand new benchmark designed to comprehensively evaluate the actual capabilities of AI assistants.ToolSnadbox’ paperIt was reported that the announcement was made.
Accordingly, the brand new tool focuses on narrowing the gap with actual performance by measuring three key aspects that were ignored in existing LLM assessments.
These include ▲implicit state dependencies between tools, ▲conversational evaluation, and ▲dynamic evaluation strategy for intermediate and final milestones over an arbitrary trajectory.
The authors indicate that “existing benchmarks have focused on easy evaluations through single-turn prompts or web services in non-dynamic situations, making it difficult to reflect accurate performance.”
So the brand new benchmark focuses on accurately measuring performance in real-world scenarios. For instance, you’ll be able to test whether an AI assistant understands that the phone should be turned on before sending a text message. In other words, the AI assistant must know the present state of the system and take appropriate motion.
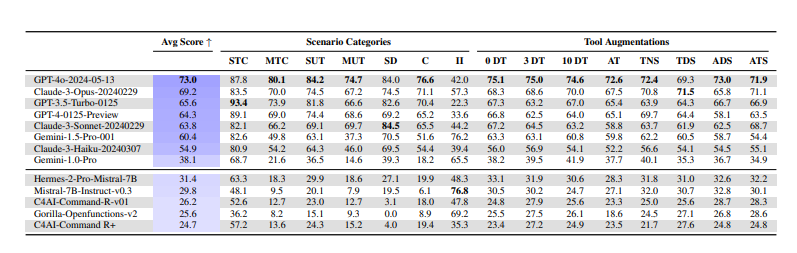
After testing various AI models using ToolSandbox, we found a major performance gap between proprietary and open source models.
‘GPT-4o’ took first place with a median rating of 73, ‘Claude 3 Opus’ got here in second with 69.2, and ‘Gemini 1.5 Pro’ scored 60.4.
However, ‘Mistral 7B’ scored 31.4 points, and ‘Command R’ scored 26.2 points. The newest model, ‘Rama 3.1’, and ‘Qone 2’ weren’t included within the test, but overall, open source scored only half as much as closed source.
“We show that there’s a significant performance gap between open source and proprietary models, and that our tool provides completely latest insights into how LLMs are assessed,” the researchers said.
The study also found that even state-of-the-art SOTA LLMs struggle with complex tasks involving tools equivalent to state dependencies, converting user input to a typical format, and scenarios with insufficient information.
We also found that larger models perform worse than smaller models in certain scenarios, especially those involving state dependencies. This means that model size doesn’t necessarily imply higher performance on complex real-world tasks.
The researchers said they are going to release the tool sandbox via GitHub soon.
Reporter Im Dae-jun ydj@aitimes.com