

🤗 Transformers has develop into the default library for data scientists all around the globe to explore cutting-edge NLP models and construct recent NLP features. With over 5,000 pre-trained and fine-tuned models available, in over 250 languages, it’s a wealthy playground, easily accessible whichever framework you’re working in.
While experimenting with models in 🤗 Transformers is straightforward, deploying these large models into production with maximum performance, and managing them into an architecture that scales with usage is a hard engineering challenge for any Machine Learning Engineer.
This 100x performance gain and built-in scalability is why subscribers of our hosted Accelerated Inference API selected to construct their NLP features on top of it. To get to the last 10x of performance boost, the optimizations have to be low-level, specific to the model, and to the goal hardware.
This post shares a few of our approaches squeezing every drop of compute juice for our customers. 🍋
Attending to the primary 10x speedup
The primary leg of the optimization journey is essentially the most accessible, all about using the very best combination of techniques offered by the Hugging Face libraries, independent of the goal hardware.
We use essentially the most efficient methods built into Hugging Face model pipelines to scale back the quantity of computation during each forward pass. These methods are specific to the architecture of the model and the goal task, as an example for a text-generation task on a GPT architecture, we reduce the dimensionality of the eye matrices computation by specializing in the brand new attention of the last token in each pass:
| – | Naive version | Optimized version |
|---|---|---|
| – | 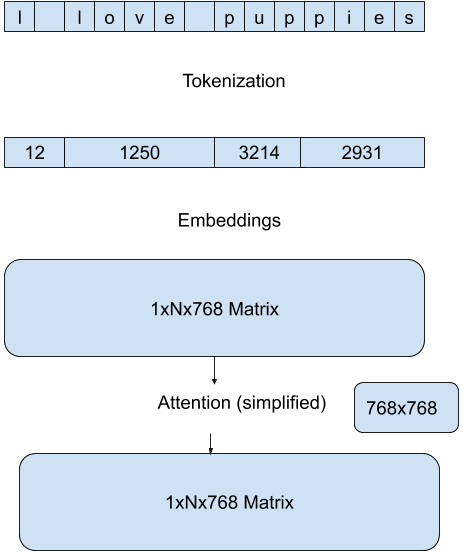 |
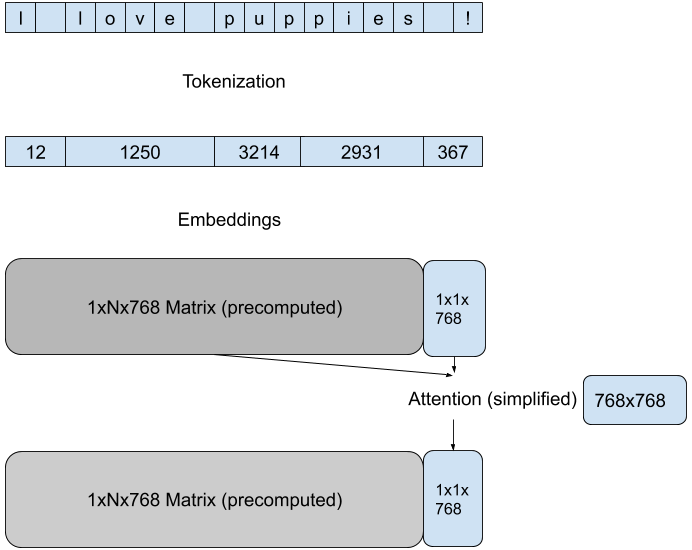 |
Tokenization is commonly a bottleneck for efficiency during inference. We use essentially the most efficient methods from the 🤗 Tokenizers library, leveraging the Rust implementation of the model tokenizer together with smart caching to rise up to 10x speedup for the general latency.
Leveraging the newest features of the Hugging Face libraries, we achieve a reliable 10x speed up in comparison with an out-of-box deployment for a given model/hardware pair. As recent releases of Transformers and Tokenizers typically ship every month, our API customers don’t have to always adapt to recent optimization opportunities, their models just keep running faster.
Compilation FTW: the hard to get 10x
Now that is where it gets really tricky. With a purpose to get the very best possible performance we are going to need to switch the model and compile it targeting the particular hardware for inference. The selection of hardware itself will rely upon each the model (size in memory) and the demand profile (request batching). Even when serving predictions from the identical model, some API customers may profit more from Accelerated CPU inference, and others from Accelerated GPU inference, each with different optimization techniques and libraries applied.
Once the compute platform has been chosen for the use case, we will go to work. Listed here are some CPU-specific techniques that might be applied with a static graph:
- Optimizing the graph (Removing unused flow)
- Fusing layers (with specific CPU instructions)
- Quantizing the operations
Using out-of-box functions from open source libraries (e.g. 🤗 Transformers with ONNX Runtime) won’t produce the very best results, or could end in a big lack of accuracy, particularly during quantization. There is no such thing as a silver bullet, and the very best path is different for every model architecture. But diving deep into the Transformers code and ONNX Runtime documentation, the celebrities might be aligned to attain one other 10x speedup.
Unfair advantage
The Transformer architecture was a decisive inflection point for Machine Learning performance, starting with NLP, and during the last 3 years the speed of improvement in Natural Language Understanding and Generation has been steep and accelerating. One other metric which accelerated accordingly, is the typical size of the models, from the 110M parameters of BERT to the now 175Bn of GPT-3.
This trend has introduced daunting challenges for Machine Learning Engineers when deploying the newest models into production. While 100x speedup is a high bar to achieve, that’s what it takes to serve predictions with acceptable latency in real-time consumer applications.
To achieve that bar, as Machine Learning Engineers at Hugging Face we definitely have an unfair advantage sitting in the identical (virtual) offices because the 🤗 Transformers and 🤗 Tokenizers maintainers 😬. We’re also extremely lucky for the wealthy partnerships we now have developed through open source collaborations with hardware and cloud vendors like Intel, NVIDIA, Qualcomm, Amazon and Microsoft that enable us to tune our models x infrastructure with the newest hardware optimizations techniques.
If you must feel the speed on our infrastructure, start a free trial and we’ll get in contact.
If you must profit from our experience optimizing inference on your individual infrastructure take part in our 🤗 Expert Acceleration Program.