

Co-written by Teven Le Scao, Patrick Von Platen, Suraj Patil, Yacine Jernite and Victor Sanh.
Every month, we’ll select a subject to give attention to, reading a set of 4 papers recently published on the topic. We are going to then write a brief blog post summarizing their findings and the common trends between them, and questions we had for follow-up work after reading them. The primary topic for January 2021 was Sparsity and Pruning, in February 2021 we addressed Long-Range Attention in Transformers.
Introduction
After the rise of enormous transformer models in 2018 and 2019, two trends have quickly emerged to bring their compute requirements down. First, conditional computation, quantization, distillation, and pruning have unlocked inference of enormous models in compute-constrained environments; we’ve already touched upon this partly in our last reading group post. The research community then moved to scale back the price of pre-training.
Specifically, one issue has been at the middle of the efforts: the quadratic cost in memory and time of transformer models with regard to the sequence length. With a view to allow efficient training of very large models, 2020 saw an onslaught of papers to handle that bottleneck and scale transformers beyond the same old 512- or 1024- sequence lengths that were the default in NLP firstly of the 12 months.
This topic has been a key a part of our research discussions from the beginning, and our own Patrick Von Platen has already dedicated a 4-part series to Reformer. On this reading group, somewhat than attempting to cover every approach (there are such a lot of!), we’ll give attention to 4 principal ideas:
For exhaustive views of the topic, take a look at Efficient Transfomers: A Survey and Long Range Arena.
Summaries
Longformer – The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer addresses the memory bottleneck of transformers by replacing conventional self-attention with a mix of windowed/local/sparse (cf. Sparse Transformers (2019)) attention and global attention that scales linearly with the sequence length. Versus previous long-range transformer models (e.g. Transformer-XL (2019), Reformer (2020), Adaptive Attention Span (2019)), Longformer’s self-attention layer is designed as a drop-in substitute for the usual self-attention, thus making it possible to leverage pre-trained checkpoints for further pre-training and/or fine-tuning on long sequence tasks.
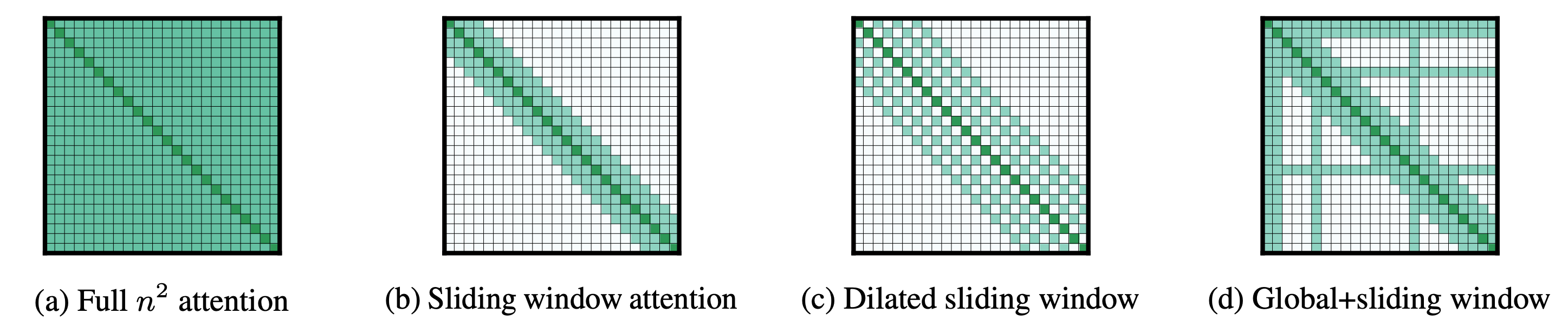
The usual self-attention matrix (Figure a) scales quadratically with the input length:
Longformer uses different attention patterns for autoregressive language modeling, encoder pre-training & fine-tuning, and sequence-to-sequence tasks.
- For autoregressive language modeling, the strongest results are obtained by replacing causal self-attention (a la GPT2) with dilated windowed self-attention (Figure c). With being the sequence length and being the window length, this attention pattern reduces the memory consumption from to , which under the belief that , scales linearly with the sequence length.
- For encoder pre-training, Longformer replaces the bi-directional self-attention (a la BERT) with a mix of local windowed and global bi-directional self-attention (Figure d). This reduces the memory consumption from to with being the variety of tokens which can be attended to globally, which again scales linearly with the sequence length.
- For sequence-to-sequence models, only the encoder layers (a la BART) are replaced with a mix of local and global bi-directional self-attention (Figure d) because for many seq2seq tasks, only the encoder processes very large inputs (e.g. summarization). The memory consumption is thus reduced from to with and being the source (encoder input) and goal (decoder input) lengths respectively. For Longformer Encoder-Decoder to be efficient, it’s assumed that is far greater than .
Predominant findings
- The authors proposed the dilated windowed self-attention (Figure c) and showed that it yields higher results on language modeling in comparison with just windowed/sparse self-attention (Figure b). The window sizes are increased through the layers. This pattern further outperforms previous architectures (similar to Transformer-XL, or adaptive span attention) on downstream benchmarks.
- Global attention allows the knowledge to flow through the entire sequence and applying the worldwide attention to task-motivated tokens (similar to the tokens of the query in QA, CLS token for sentence classification) results in stronger performance on downstream tasks. Using this global pattern, Longformer may be successfully applied to document-level NLP tasks within the transfer learning setting.
- Standard pre-trained models may be adapted to long-range inputs by simply replacing the usual self-attention with the long-range self-attention proposed on this paper after which fine-tuning on the downstream task. This avoids costly pre-training specific to long-range inputs.
Follow-up questions
- The increasing size (throughout the layers) of the dilated windowed self-attention echoes findings in computer vision on increasing the receptive field of stacked CNN. How do these two findings relate? What are the transposable learnings?
- Longformer’s Encoder-Decoder architecture works well for tasks that don’t require an extended goal length (e.g. summarization). Nonetheless, how would it not work for long-range seq2seq tasks which require an extended goal length (e.g. document translation, speech recognition, etc.) especially considering the cross-attention layer of encoder-decoder’s models?
- In practice, the sliding window self-attention relies on many indexing operations to make sure a symmetric query-key weights matrix. Those operations are very slow on TPUs which highlights the query of the applicability of such patterns on other hardware.
Compressive Transformers for Long-Range Sequence Modelling
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap
Transformer-XL (2019) showed that caching previously computed layer activations in a memory can boost performance on language modeling tasks (similar to enwik8). As an alternative of just attending the present input tokens, the model may also attend to the past tokens, with being the memory size of the model. Transformer-XL has a memory complexity of , which shows that memory cost can increase significantly for very large . Hence, Transformer-XL has to eventually discard past activations from the memory when the variety of cached activations gets larger than . Compressive Transformer addresses this problem by adding a further compressed memory to efficiently cache past activations that will have otherwise eventually been discarded. This manner the model can learn higher long-range sequence dependencies accessing significantly more past activations.
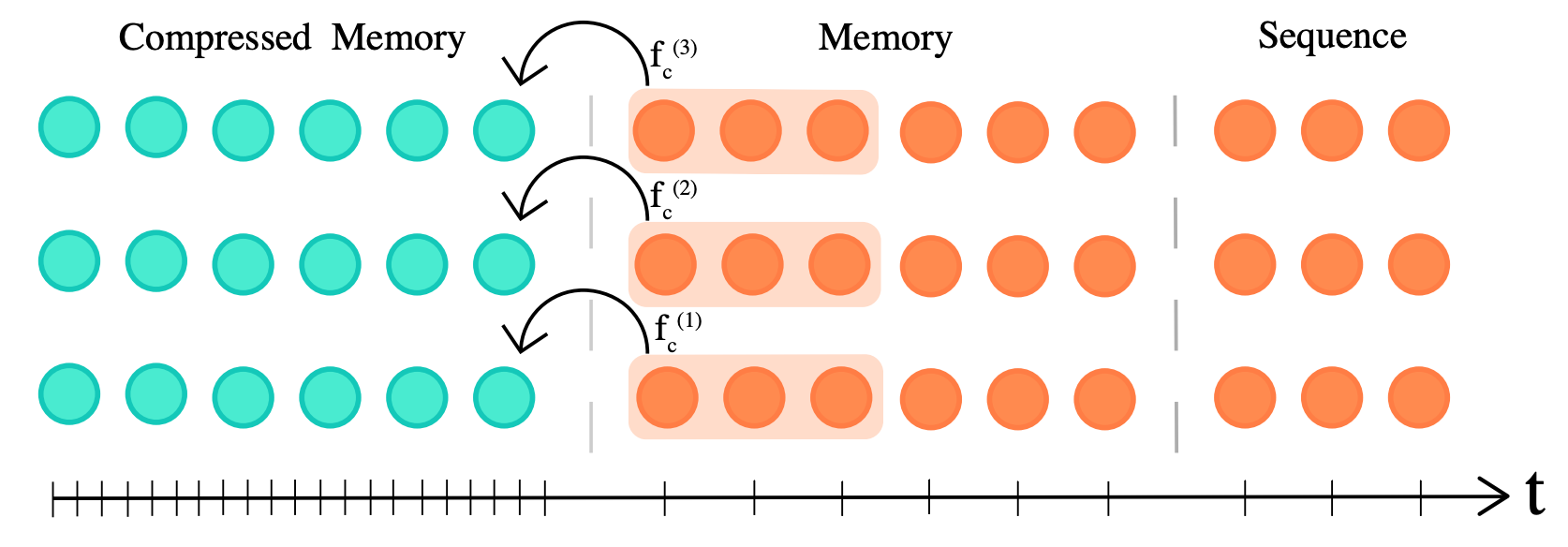
A compression factor (equal to three within the illustration) is chosen to make your mind up the speed at which past activations are compressed. The authors experiment with different compression functions similar to max/mean pooling (parameter-free) and 1D convolution (trainable layer). The compression function is trained with backpropagation through time or local auxiliary compression losses. Along with the present input of length , the model attends to cached activations within the regular memory and compressed memory activations allowing an extended temporal dependency of , with being the variety of attention layers. This increases Transformer-XL’s range by additional tokens and the memory cost amounts to . Experiments are conducted on Reinforcement learning, audio generation, and natural language processing. The authors also introduce a brand new long-range language modeling benchmark called PG19.
Predominant findings
- Compressive Transformer significantly outperforms the state-of-the-art perplexity on language modeling, namely on the enwik8 and WikiText-103 datasets. Specifically, compressed memory plays an important role in modeling rare words occurring on long sequences.
- The authors show that the model learns to preserve salient information by increasingly attending the compressed memory as an alternative of the regular memory, which works against the trend of older memories being accessed less incessantly.
- All compression functions (average pooling, max pooling, 1D convolution) yield similar results confirming that memory compression is an efficient option to store past information.
Follow-up questions
- Compressive Transformer requires a special optimization schedule through which the effective batch size is progressively increased to avoid significant performance degradation for lower learning rates. This effect is just not well understood and calls into more evaluation.
- The Compressive Transformer has many more hyperparameters in comparison with an easy model like BERT or GPT2: the compression rate, the compression function and loss, the regular and compressed memory sizes, etc. It is just not clear whether those parameters generalize well across different tasks (apart from language modeling) or much like the training rate, make the training also very brittle.
- It could be interesting to probe the regular memory and compressed memory to research what kind of data is memorized through the long sequences. Shedding light on probably the most salient pieces of data can inform methods similar to Funnel Transformer which reduces the redundancy in maintaining a full-length token-level sequence.
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
The goal is to scale back the complexity of the self-attention with respect to the sequence length ) from quadratic to linear. This paper makes the statement that the eye matrices are low rank (i.e. they don’t contain price of data) and explores the opportunity of using high-dimensional data compression techniques to construct more memory efficient transformers.
The theoretical foundations of the proposed approach are based on the Johnson-Lindenstrauss lemma. Let’s consider ) points in a high-dimensional space. We would like to project them to a low-dimensional space while preserving the structure of the dataset (i.e. the mutual distances between points) with a margin of error . The Johnson-Lindenstrauss lemma states we will select a small dimension and find an acceptable projection into Rk in polynomial time by simply trying random orthogonal projections.
Linformer projects the sequence length right into a smaller dimension by learning a low-rank decomposition of the eye context matrix. The matrix multiplication of the self-attention may be then cleverly re-written such that no matrix of size must be ever computed and stored.
Standard transformer:
(n * h) (n * n) (n * h)
Linformer:
(n * h) (n * d) (d * n) (n * h)
Predominant findings
- The self-attention matrix is low-rank which means that the majority of its information may be recovered by its first few highest eigenvalues and may be approximated by a low-rank matrix.
- Lot of works give attention to reducing the dimensionality of the hidden states. This paper shows that reducing the sequence length with learned projections could be a strong alternative while shrinking the memory complexity of the self-attention from quadratic to linear.
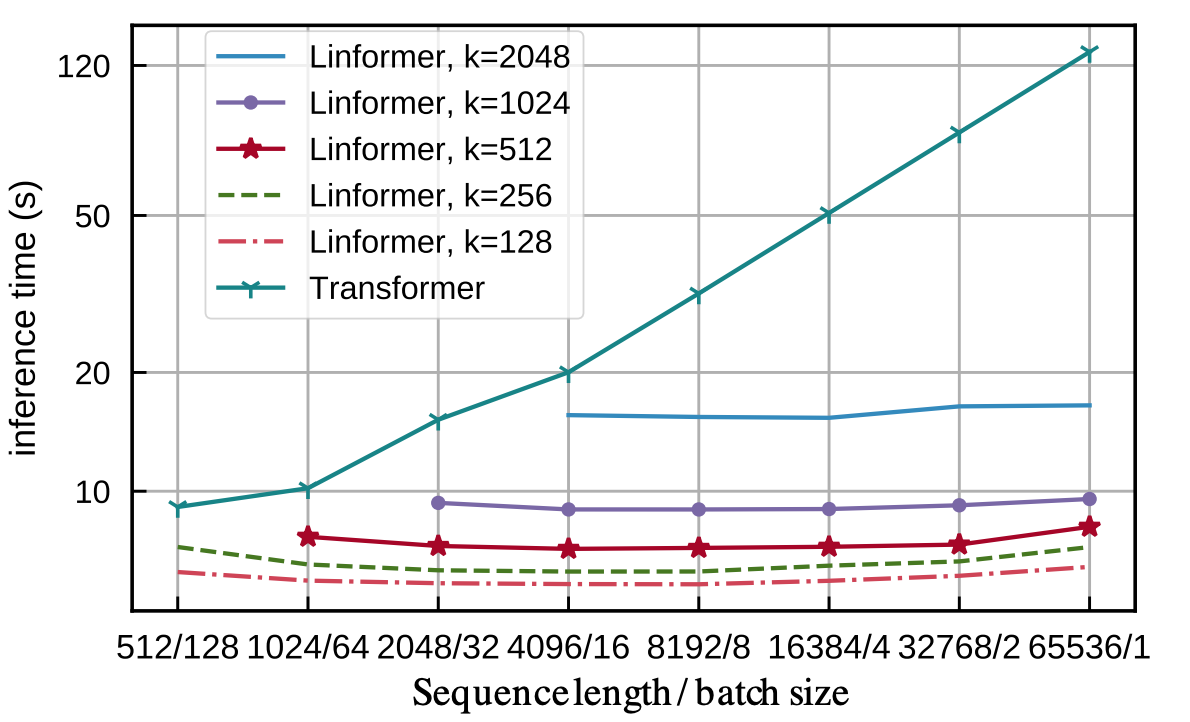
- Increasing the sequence length doesn’t affect the inference speed (time-clock) of Linformer, when transformers have a linear increase. Furthermore, the convergence speed (variety of updates) is just not impacted by Linformer’s self-attention.
Follow-up questions
- Though the projections matrices are shared between layers, the approach presented here is available in contrast with the Johnson-Lindenstrauss that states that random orthogonal projections are sufficient (in polynomial time). Would random projections have worked here? That is harking back to Reformer which uses random projections in locally sensitive hashing to scale back the memory complexity of the self-attention.
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
The goal is (again!) to scale back the complexity of the self-attention with respect to the sequence length ) from quadratic to linear. In contrast to other papers, the authors note that the sparsity and low-rankness priors of the self-attention may not hold in other modalities (speech, protein sequence modeling). Thus the paper explores methods to scale back the memory burden of the self-attention with none priors on the eye matrix.
The authors observe that if we could perform the matrix multiplication through the softmax ( ), we wouldn’t should compute the matrix of size which is the memory bottleneck. They use random feature maps (aka random projections) to approximate the softmax by:
, where is a non-linear suitable function. After which:
Taking inspiration from machine learning papers from the early 2000s, the authors introduce FAVOR+ (Fast Attention Via Orthogonal Random positive (+) Features) a procedure to seek out unbiased or nearly-unbiased estimations of the self-attention matrix, with uniform convergence and low estimation variance.
Predominant findings
- The FAVOR+ procedure may be used to approximate self-attention matrices with high accuracy, with none priors on the shape of the eye matrix, making it applicable as a drop-in substitute of normal self-attention and resulting in strong performances in multiple applications and modalities.
- The very thorough mathematical investigation of how-to and not-to approximate softmax highlights the relevance of principled methods developed within the early 2000s even within the deep learning era.
- FAVOR+ will also be applied to efficiently model other kernelizable attention mechanisms beyond softmax.
Follow-up questions
- Even when the approximation of the eye mechanism is tight, small errors propagate through the transformer layers. This raises the query of the convergence and stability of fine-tuning a pre-trained network with FAVOR+ as an approximation of self-attention.
- The FAVOR+ algorithm is the mix of multiple components. It is just not clear which of those components have probably the most empirical impact on the performance, especially in view of the range of modalities considered on this work.
Reading group discussion
The developments in pre-trained transformer-based language models for natural language understanding and generation are impressive. Making these systems efficient for production purposes has turn out to be a really lively research area. This emphasizes that we still have much to learn and construct each on the methodological and practical sides to enable efficient and general deep learning based systems, particularly for applications that require modeling long-range inputs.
The 4 papers above offer alternative ways to take care of the quadratic memory complexity of the self-attention mechanism, normally by reducing it to linear complexity. Linformer and Longformer each depend on the statement that the self-attention matrix doesn’t contain price of data (the eye matrix is low-rank and sparse). Performer gives a principled method to approximate the softmax-attention kernel (and any kernelizable attention mechanisms beyond softmax). Compressive Transformer offers an orthogonal approach to model long range dependencies based on reoccurrence.
These different inductive biases have implications when it comes to computational speed and generalization beyond the training setup. Specifically, Linformer and Longformer result in different trade-offs: Longformer explicitly designs the sparse attention patterns of the self-attention (fixed patterns) while Linformer learns the low-rank matrix factorization of the self-attention matrix. In our experiments, Longformer is less efficient than Linformer, and is currently highly depending on implementation details. However, Linformer’s decomposition only works for fixed context length (fixed at training) and can’t generalize to longer sequences without specific adaptation. Furthermore, it cannot cache previous activations which may be extremely useful within the generative setup. Interestingly, Performer is conceptually different: it learns to approximate the softmax attention kernel without counting on any sparsity or low-rank assumption. The query of how these inductive biases compare to one another for various quantities of coaching data stays.
All these works highlight the importance of long-range inputs modeling in natural language. Within the industry, it’s common to come across use-cases similar to document translation, document classification or document summarization which require modeling very long sequences in an efficient and robust way. Recently, zero-shot examples priming (a la GPT3) has also emerged as a promising alternative to plain fine-tuning, and increasing the variety of priming examples (and thus the context size) steadily increases the performance and robustness. Finally, it’s common in other modalities similar to speech or protein modeling to come across long sequences beyond the usual 512 time steps.
Modeling long inputs is just not antithetical to modeling short inputs but as an alternative ought to be thought from the attitude of a continuum from shorter to longer sequences. Shortformer, Longformer and BERT provide evidence that training the model on short sequences and steadily increasing sequence lengths result in an accelerated training and stronger downstream performance. This statement is coherent with the intuition that the long-range dependencies acquired when little data is out there can depend on spurious correlations as an alternative of strong language understanding. This echoes some experiments Teven Le Scao has run on language modeling: LSTMs are stronger learners within the low data regime in comparison with transformers and provides higher perplexities on small-scale language modeling benchmarks similar to Penn Treebank.
From a practical standpoint, the query of positional embeddings can be an important methodological aspect with computational efficiency trade-offs. Relative positional embeddings (introduced in Transformer-XL and utilized in Compressive Transformers) are appealing because they will easily be prolonged to yet-unseen sequence lengths, but at the identical time, relative positional embeddings are computationally expensive. On the opposite side, absolute positional embeddings (utilized in Longformer and Linformer) are less flexible for sequences longer than those seen during training, but are computationally more efficient. Interestingly, Shortformer introduces an easy alternative by adding the positional information to the queries and keys of the self-attention mechanism as an alternative of adding it to the token embeddings. The tactic known as position-infused attention and is shown to be very efficient while producing strong results.
@Hugging Face 🤗: Long-range modeling
The Longformer implementation and the associated open-source checkpoints can be found through the Transformers library and the model hub. Performer and Big Bird, which is a long-range model based on sparse attention, are currently within the works as a part of our call for models, an effort involving the community so as to promote open-source contributions. We can be pumped to listen to from you in the event you’ve wondered tips on how to contribute to transformers but didn’t know where to start out!
For further reading, we recommend checking Patrick Platen’s blog on Reformer, Teven Le Scao’s post on Johnson-Lindenstrauss approximation, Efficient Transfomers: A Survey, and Long Range Arena: A Benchmark for Efficient Transformers.
Next month, we’ll cover self-training methods and applications. See you in March!