
Climate change is one in every of the best challenges that we face and reducing emissions of greenhouse gases comparable to carbon dioxide (CO2) is a very important a part of tackling this problem.
Training and deploying machine learning models will emit CO2 as a result of the energy usage of the computing infrastructures which might be used: from GPUs to storage, all of it needs energy to operate and emits CO2 in the method.
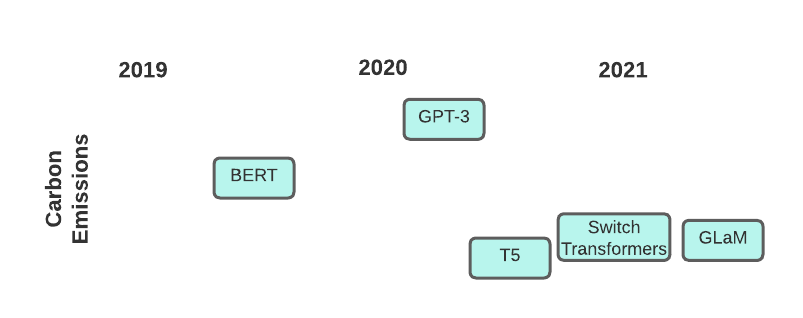
Pictured: Recent Transformer models and their carbon footprints
The quantity of CO2 emitted will depend on various factors comparable to runtime, hardware used, and carbon intensity of the energy source.
Using the tools described below will show you how to each track and report your individual emissions (which is vital to enhance the transparency of our field as an entire!) and select models based on their carbon footprint.
calculate your individual CO2 Emissions routinely with Transformers
Before we start, if you happen to should not have the newest version of the huggingface_hub library in your system, please run the next:
pip install huggingface_hub -U
find low-emission models using the Hugging Face Hub
With the model now uploaded to the Hub, how will you seek for models on the Hub while attempting to be eco-friendly? Well, the huggingface_hub library has a brand new special parameter to perform this search: emissions_threshold. All it is advisable do is specify a minimum or maximum variety of grams, and all models that fall inside that range.
For instance, we will seek for all models that took a maximum of 100 grams to make:
from huggingface_hub import HfApi
api = HfApi()
models = api.list_models(emissions_thresholds=(None, 100), cardData=True)
len(models)
>>> 191
There have been quite just a few! This also helps to seek out smaller models, given they typically didn’t release as much carbon during training.
We are able to take a look at one up near see it does fit our threshold:
model = models[0]
print(f'Model Name: {model.modelId}nCO2 Emitted during training: {model.cardData["co2_eq_emissions"]}')
>>> Model Name: esiebomajeremiah/autonlp-email-classification-657119381
CO2 Emitted during training: 3.516233232503715
Similarly, we will seek for a minimum value to seek out very large models that emitted a whole lot of CO2 during training:
models = api.list_models(emissions_thresholds=(500, None), cardData=True)
len(models)
>>> 10
Now let’s examine exactly how much CO2 one in every of these emitted:
model = models[0]
print(f'Model Name: {model.modelId}nCO2 Emitted during training: {model.cardData["co2_eq_emissions"]}')
>>> Model Name: Maltehb/aelaectra-danish-electra-small-cased
CO2 Emitted during training: 4009.5
That is a whole lot of CO2!
As you may see, in only just a few lines of code we will quickly vet models we should want to use to be certain that we’re being environmentally cognizant!
Report Your Carbon Emissions with transformers
Should you’re using transformers, you may routinely track and report carbon emissions due to the codecarbon integration. Should you’ve installed codecarbon in your machine, the Trainer object will routinely add the CodeCarbonCallback while training, which is able to store carbon emissions data for you as you train.
So, if you happen to run something like this…
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
ds = load_dataset("imdb")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
small_train_dataset = ds["train"].shuffle(seed=42).select(range(1000)).map(tokenize_function, batched=True)
small_eval_dataset = ds["test"].shuffle(seed=42).select(range(1000)).map(tokenize_function, batched=True)
training_args = TrainingArguments(
"codecarbon-text-classification",
num_train_epochs=4,
push_to_hub=True
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
)
trainer.train()
…you may be left with a file throughout the codecarbon-text-classification directory called emissions.csv. This file will keep track of the carbon emissions across different training runs. Then, whenever you’re ready, you may take the emissions from the run you used to coach your final model and include that in its model card. 📝
An example of this data being included at the highest of the model card is shown below:

For more references on the metadata format for co2_eq_emissions see the hub docs.