

Try this tutorial with the Notebook Companion:
![]()
Understanding embeddings
An embedding is a numerical representation of a bit of knowledge, for instance, text, documents, images, audio, etc. The representation captures the semantic meaning of what’s being embedded, making it robust for a lot of industry applications.
Given the text “What’s the primary good thing about voting?”, an embedding of the sentence might be represented in a vector space, for instance, with a listing of 384 numbers (for instance, [0.84, 0.42, …, 0.02]). Since this list captures the meaning, we are able to do exciting things, like calculating the gap between different embeddings to find out how well the meaning of two sentences matches.
Embeddings will not be limited to text! You can even create an embedding of a picture (for instance, a listing of 384 numbers) and compare it with a text embedding to find out if a sentence describes the image. This idea is under powerful systems for image search, classification, description, and more!
How are embeddings generated? The open-source library called Sentence Transformers permits you to create state-of-the-art embeddings from images and text totally free. This blog shows an example with this library.
What are embeddings for?
“[…] when you understand this ML multitool (embedding), you will give you the chance to construct every little thing from serps to suggestion systems to chatbots and an entire lot more. You haven’t got to be a knowledge scientist with ML expertise to make use of them, nor do you would like an enormous labeled dataset.” – Dale Markowitz, Google Cloud.
Once a bit of knowledge (a sentence, a document, a picture) is embedded, the creativity starts; several interesting industrial applications use embeddings. E.g., Google Search uses embeddings to match text to text and text to pictures; Snapchat uses them to “serve the appropriate ad to the appropriate user at the appropriate time“; and Meta (Facebook) uses them for their social search.
Before they may get intelligence from embeddings, these firms needed to embed their pieces of knowledge. An embedded dataset allows algorithms to go looking quickly, sort, group, and more. Nonetheless, it will possibly be expensive and technically complicated. On this post, we use easy open-source tools to point out how easy it will possibly be to embed and analyze a dataset.
Getting began with embeddings
We’ll create a small Steadily Asked Questions (FAQs) engine: receive a question from a user and discover which FAQ is probably the most similar. We’ll use the US Social Security Medicare FAQs.
But first, we want to embed our dataset (other texts use the terms encode and embed interchangeably). The Hugging Face Inference API allows us to embed a dataset using a fast POST call easily.
For the reason that embeddings capture the semantic meaning of the questions, it is feasible to match different embeddings and see how different or similar they’re. Because of this, you may get probably the most similar embedding to a question, which is comparable to finding probably the most similar FAQ. Try our semantic search tutorial for a more detailed explanation of how this mechanism works.
In a nutshell, we’ll:
- Embed Medicare’s FAQs using the Inference API.
- Upload the embedded inquiries to the Hub totally free hosting.
- Compare a customer’s query to the embedded dataset to discover which is probably the most similar FAQ.
1. Embedding a dataset
Step one is choosing an existing pre-trained model for creating the embeddings. We will select a model from the Sentence Transformers library. On this case, let’s use the “sentence-transformers/all-MiniLM-L6-v2” since it’s a small but powerful model. In a future post, we’ll examine other models and their trade-offs.
Log in to the Hub. You could create a write token in your Account Settings. We’ll store the write token in hf_token.
model_id = "sentence-transformers/all-MiniLM-L6-v2"
hf_token = "get your token in http://hf.co/settings/tokens"
To generate the embeddings you should use the https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id} endpoint with the headers {"Authorization": f"Bearer {hf_token}"}. Here’s a function that receives a dictionary with the texts and returns a listing with embeddings.
import requests
api_url = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}"
headers = {"Authorization": f"Bearer {hf_token}"}
The primary time you generate the embeddings, it might take some time (roughly 20 seconds) for the API to return them. We use the retry decorator (install with pip install retry) in order that if on the primary try, output = query(dict(inputs = texts)) doesn’t work, wait 10 seconds and take a look at thrice again. This happens because, on the primary request, the model must be downloaded and installed on the server, but subsequent calls are much faster.
def query(texts):
response = requests.post(api_url, headers=headers, json={"inputs": texts, "options":{"wait_for_model":True}})
return response.json()
The present API doesn’t implement strict rate limitations. As an alternative, Hugging Face balances the masses evenly between all our available resources and favors regular flows of requests. If you want to embed several texts or images, the Hugging Face Accelerated Inference API would speed the inference and allow you to make a choice from using a CPU or GPU.
texts = ["How do I get a replacement Medicare card?",
"What is the monthly premium for Medicare Part B?",
"How do I terminate my Medicare Part B (medical insurance)?",
"How do I sign up for Medicare?",
"Can I sign up for Medicare Part B if I am working and have health insurance through an employer?",
"How do I sign up for Medicare Part B if I already have Part A?",
"What are Medicare late enrollment penalties?",
"What is Medicare and who can get it?",
"How can I get help with my Medicare Part A and Part B premiums?",
"What are the different parts of Medicare?",
"Will my Medicare premiums be higher because of my higher income?",
"What is TRICARE ?",
"Should I sign up for Medicare Part B if I have Veterans' Benefits?"]
output = query(texts)
As a response, you get back a listing of lists. Each list incorporates the embedding of a FAQ. The model, “sentence-transformers/all-MiniLM-L6-v2”, is encoding the input inquiries to 13 embeddings of size 384 each. Let’s convert the list to a Pandas DataFrame of shape (13×384).
import pandas as pd
embeddings = pd.DataFrame(output)
It looks just like this matrix:
[[-0.02388945 0.05525852 -0.01165488 ... 0.00577787 0.03409787 -0.0068891 ]
[-0.0126876 0.04687412 -0.01050217 ... -0.02310316 -0.00278466 0.01047371]
[ 0.00049438 0.11941205 0.00522949 ... 0.01687654 -0.02386115 0.00526433]
...
[-0.03900796 -0.01060951 -0.00738271 ... -0.08390449 0.03768405 0.00231361]
[-0.09598278 -0.06301168 -0.11690582 ... 0.00549841 0.1528919 0.02472013]
[-0.01162949 0.05961934 0.01650903 ... -0.02821241 -0.00116556 0.0010672 ]]
2. Host embeddings totally free on the Hugging Face Hub
🤗 Datasets is a library for quickly accessing and sharing datasets. Let’s host the embeddings dataset within the Hub using the user interface (UI). Then, anyone can load it with a single line of code. You can even use the terminal to share datasets; see the documentation for the steps. Within the notebook companion of this entry, you’ll give you the chance to make use of the terminal to share the dataset. If you ought to skip this section, take a look at the ITESM/embedded_faqs_medicare repo with the embedded FAQs.
First, we export our embeddings from a Pandas DataFrame to a CSV. You may save your dataset in any way you favor, e.g., zip or pickle; you needn’t use Pandas or CSV. Since our embeddings file shouldn’t be large, we are able to store it in a CSV, which is well inferred by the datasets.load_dataset() function we’ll employ in the subsequent section (see the Datasets documentation), i.e., we needn’t create a loading script. We’ll save the embeddings with the name embeddings.csv.
embeddings.to_csv("embeddings.csv", index=False)
Follow the subsequent steps to host embeddings.csv within the Hub.
- Click in your user in the highest right corner of the Hub UI.
- Create a dataset with “Latest dataset.”
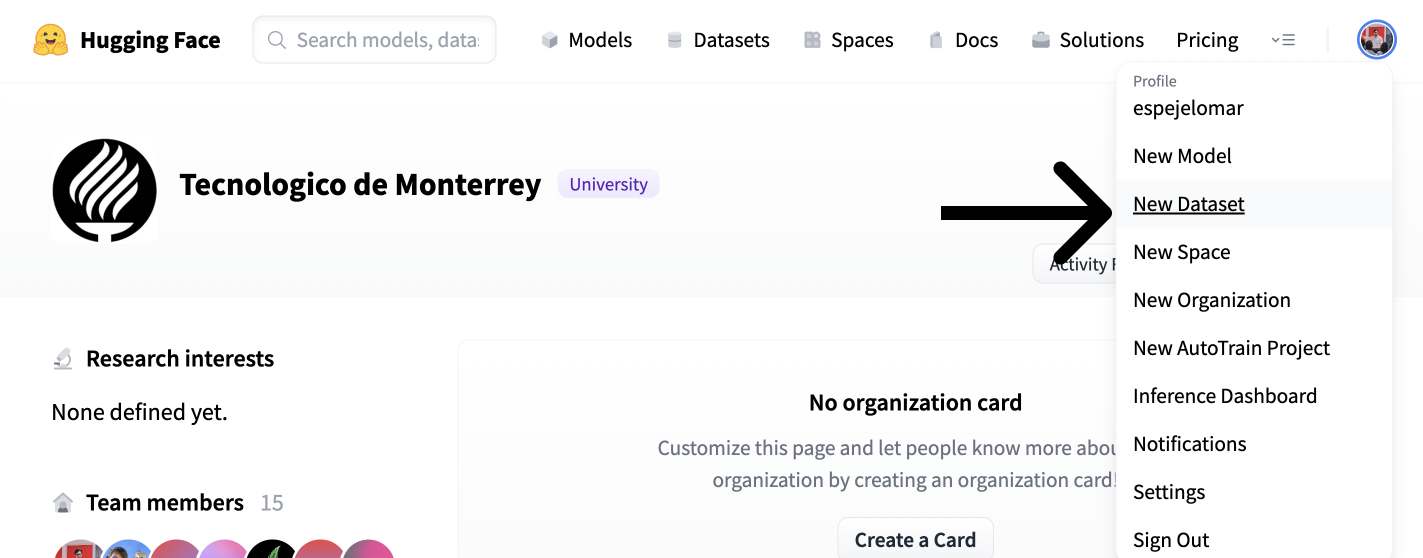
- Select the Owner (organization or individual), name, and license of the dataset. Select if you happen to want it to be private or public. Create the dataset.

- Go to the “Files” tab (screenshot below) and click on “Add file” and “Upload file.”
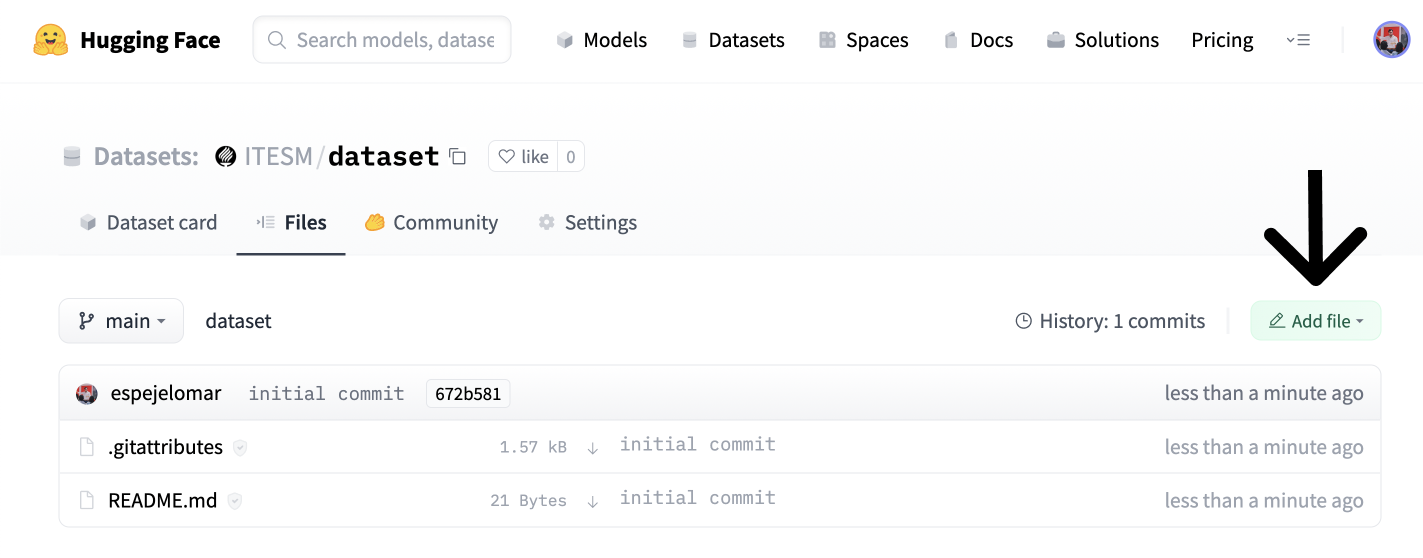
- Finally, drag or upload the dataset, and commit the changes.
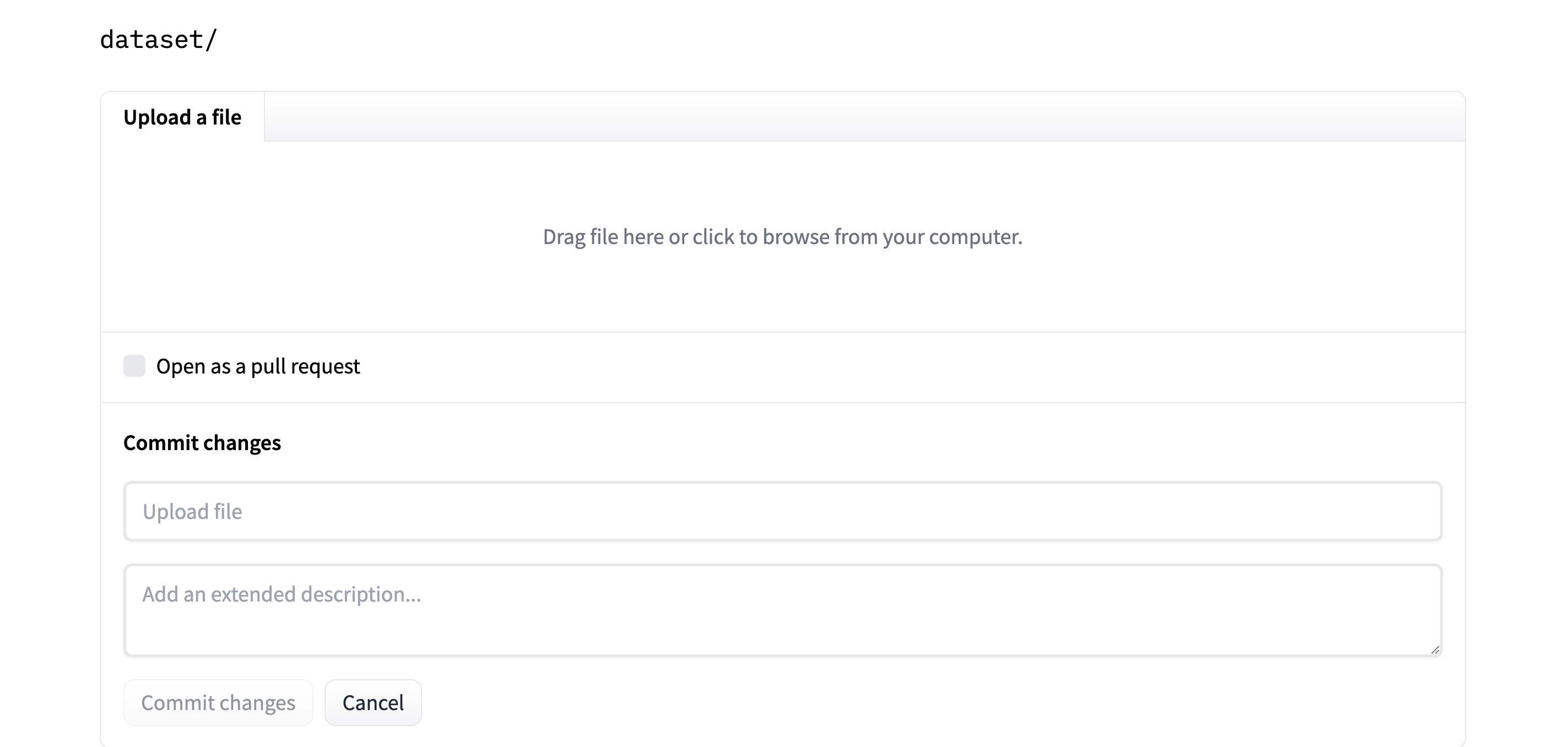
Now the dataset is hosted on the Hub totally free. You (or whoever you ought to share the embeddings with) can quickly load them. Let’s have a look at how.
3. Get probably the most similar Steadily Asked Inquiries to a question
Suppose a Medicare customer asks, “How can Medicare help me?”. We’ll find which of our FAQs could best answer our user query. We’ll create an embedding of the query that may represent its semantic meaning. We then compare it to every embedding in our FAQ dataset to discover which is closest to the query in vector space.
Install the 🤗 Datasets library with pip install datasets. Then, load the embedded dataset from the Hub and convert it to a PyTorch FloatTensor. Note that this shouldn’t be the one approach to operate on a Dataset; for instance, you can use NumPy, Tensorflow, or SciPy (discuss with the Documentation). If you ought to practice with an actual dataset, the ITESM/embedded_faqs_medicare repo incorporates the embedded FAQs, or you should use the companion notebook to this blog.
import torch
from datasets import load_dataset
faqs_embeddings = load_dataset('namespace/repo_name')
dataset_embeddings = torch.from_numpy(faqs_embeddings["train"].to_pandas().to_numpy()).to(torch.float)
We use the query function we defined before to embed the shopper’s query and convert it to a PyTorch FloatTensor to operate over it efficiently. Note that after the embedded dataset is loaded, we could use the add_faiss_index and search methods of a Dataset to discover the closest FAQ to an embedded query using the faiss library. Here’s a nice tutorial of the choice.
query = ["How can Medicare help me?"]
output = query(query)
query_embeddings = torch.FloatTensor(output)
You should use the util.semantic_search function within the Sentence Transformers library to discover which of the FAQs are closest (most similar) to the user’s query. This function uses cosine similarity because the default function to find out the proximity of the embeddings. Nonetheless, you can also use other functions that measure the gap between two points in a vector space, for instance, the dot product.
Install sentence-transformers with pip install -U sentence-transformers, and seek for the five most similar FAQs to the query.
from sentence_transformers.util import semantic_search
hits = semantic_search(query_embeddings, dataset_embeddings, top_k=5)
util.semantic_search identifies how close each of the 13 FAQs is to the shopper query and returns a listing of dictionaries with the highest top_k FAQs. hits looks like this:
[{'corpus_id': 8, 'score': 0.75653076171875},
{'corpus_id': 7, 'score': 0.7418993711471558},
{'corpus_id': 3, 'score': 0.7252674102783203},
{'corpus_id': 9, 'score': 0.6735571622848511},
{'corpus_id': 10, 'score': 0.6505177617073059}]
The values in corpus_id allow us to index the list of texts we defined in the primary section and get the five most similar FAQs:
print([texts[hits[0][i]['corpus_id']] for i in range(len(hits[0]))])
Listed below are the 5 FAQs that come closest to the shopper’s query:
['How can I get help with my Medicare Part A and Part B premiums?',
'What is Medicare and who can get it?',
'How do I sign up for Medicare?',
'What are the different parts of Medicare?',
'Will my Medicare premiums be higher because of my higher income?']
This list represents the 5 FAQs closest to the shopper’s query. Nice! We used here PyTorch and Sentence Transformers as our primary numerical tools. Nonetheless, we could have defined the cosine similarity and rating functions by ourselves using tools comparable to NumPy and SciPy.
Additional resources to continue to learn
If you ought to know more concerning the Sentence Transformers library:
Thanks for reading!