

![]()
1. Introduction:
Natural language generation (i.e. text generation) is one in all the core tasks in natural language processing (NLP). On this blog, we introduce the present state-of-the-art decoding method, Contrastive Search, for neural text generation. Contrastive search is originally proposed in “A Contrastive Framework for Neural Text Generation” [1] ([Paper][Official Implementation]) at NeurIPS 2022. Furthermore, on this follow-up work, “Contrastive Search Is What You Need For Neural Text Generation” [2] ([Paper] [Official Implementation]), the authors further display that contrastive search can generate human-level text using off-the-shelf language models across 16 languages.
[Remark] For users who usually are not conversant in text generation, please refer more details to this blog post.
2. Hugging Face 🤗 Demo of Contrastive Search:
Contrastive Search is now available on 🤗 transformers, each on PyTorch and TensorFlow. You’ll be able to interact with the examples shown on this blog post using your framework of alternative in this Colab notebook, which is linked at the highest. We’ve got also built this awesome demo which directly compares contrastive search with other popular decoding methods (e.g. beam search, top-k sampling [3], and nucleus sampling [4]).
3. Environment Installation:
Before running the experiments in the next sections, please install the update-to-date version of transformers as
pip install torch
pip install "transformers==4.24.0"
4. Problems of Existing Decoding Methods:
Decoding methods may be divided into two categories: (i) deterministic methods and (ii) stochastic methods. Let’s discuss each!
4.1. Deterministic Methods:
Deterministic methods, e.g. greedy search and beam search, generate text by choosing the text continuation with the very best likelihood measured by the language model. Nonetheless, as widely discussed in previous studies [3][4], deterministic methods often result in the issue of model degeneration, i.e., the generated text is unnatural and comprises undesirable repetitions.
Below, let’s examine an example of generated text from greedy search using GPT-2 model.
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
output = model.generate(input_ids, max_length=128)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output:
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a number one AI research company, with a give attention to deep learning and deep
learning-based systems.
The corporate's research is targeted on the event of deep learning-based systems that
can learn from large amounts of information, and that may be used to unravel real-world problems.
DeepMind's research can be utilized by the UK government to develop latest technologies for the
UK's National Health Service.
DeepMind's research can be utilized by the UK government to develop latest technologies for the
UK's National Health Service.
DeepMind's research can be utilized by the UK government to develop latest technologies
----------------------------------------------------------------------------------------------------
[Remark] From the result generated by greedy search, we are able to see obvious pattern of repetitions.
4.2. Stochastic Methods:
To deal with the problems posed by deterministic methods, stochastic methods generate text by introducing randomness through the decoding process. Two widely-used stochastic methods are (i) top-k sampling [3] and (ii) nucleus sampling (also called top-p sampling) [4].
Below, we illustrate an example of generated text by nucleus sampling (p=0.95) using the GPT-2 model.
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=128, top_p=0.95, top_k=0)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output:
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a number one provider of AI-based research, development, and delivery of
AI solutions for security, infrastructure, machine learning, communications, and so forth."
'AI is just not journalism'
Worse still was the message its researchers hoped would reach the world's media — that it
was not likely research, but slightly a get-rich-quick scheme to take advantage of living forces'
ignorance.
"The thing is, we all know that folks don't consciously assess the worth of the others'
information. They understand they'll get the identical on their very own."
One example? Given the small print of today
----------------------------------------------------------------------------------------------------
[Remark] While nucleus sampling can generate text freed from repetitions, the semantic coherence of the generated text is just not well-maintained. For example, the generated phrase ‘AI is just not journalism’ is incoherent with respect to the given prefix, i.e. ‘DeepMind Company’.
We note that this semantic inconsistency problem can partially be remedied by lowering the temperature. Nonetheless, reducing the temperature brings nucleus sampling closer to greedy search, which may be seen as a trade-off between greedy search and nucleus sampling. Generally, it’s difficult to seek out a prompt and model-independent temperature that avoids each the pitfalls of greedy search and nucleus sampling.
5. Contrastive Search:
On this section, we introduce a brand new decoding method, Contrastive Search, in details.
5.1. Decoding Objective:
Given the prefix text , the collection of the output token follows
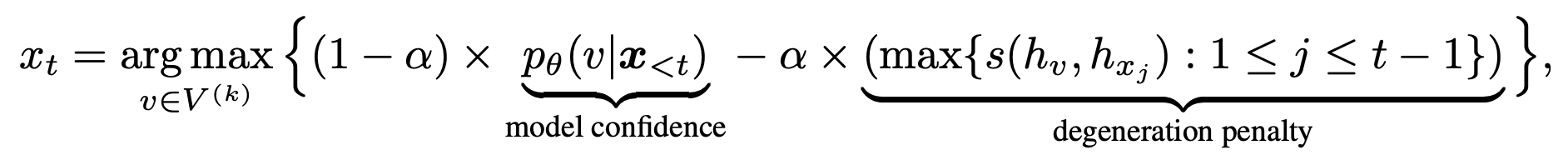
where is the set of top-k predictions from the language model’s probability distribution . The primary term, i.e. model confidence, is the probability of the candidate predicted by the language model. The second term, degeneration penalty, measures how discriminative of with respect to the previous context and the function computes the cosine similarity between the token representations. More specifically, the degeneration penalty is defined as the utmost cosine similarity between the token representation of , i.e. , and that of all tokens within the context . Here, the candidate representation is computed by the language model given the concatenation of and . Intuitively, a bigger degeneration penalty of means it’s more similar (within the representation space) to the context, due to this fact more likely resulting in the issue of model degeneration. The hyperparameter regulates the importance of those two components. When , contrastive search degenerates to the vanilla greedy search.
[Remark] When generating output, contrastive search jointly considers (i) the probability predicted by the language model to take care of the semantic coherence between the generated text and the prefix text; and (ii) the similarity with respect to the previous context to avoid model degeneration.
5.2. Generating Text with Contrastive Search:
Below, we use the identical prefix text (i.e. “DeepMind Company is”) as in Section 4.1 and 4.2, and generate the text with contrastive search (k=4 and ). To totally display the superior capability of contrastive search, we let the language model generate a long document with 512 tokens as
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = 'gpt2-large'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model.eval()
prefix_text = r'DeepMind Company is'
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=512)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
The arguments are as follows:
--top_k: The hyperparameter in contrastive search.--penalty_alpha: The hyperparameter in contrastive search.
Model Output:
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a frontrunner in artificial intelligence (AI). We've got a protracted history of working
with corporations akin to Google, Facebook, Amazon, and Microsoft to construct products that improve
people's lives, and today we're excited to announce that DeepMind's AlphaGo program has won the
game of Go, becoming the primary program to defeat an expert Go player.
The victory is a testament to the facility of deep learning, and to the incredible work of our
research team, which has been on the forefront of AI research for the past five years. AlphaGo
is one of the advanced Go programs ever created, and its performance is a very important step
towards the goal of human-level AI.
"That is the culmination of a decade of exertions," said Andy Ng, co-founder and CTO of DeepMind.
"We're thrilled to have achieved this milestone and sit up for continuing to develop AI that
may be utilized in a wide selection of applications and to assist people live higher lives."
DeepMind's work on Go began in 2010, when it began to coach a neural network to play Go using
tens of millions of games played by top Go players world wide. Since then, the team has refined the
algorithm, adding increasingly more layers of reinforcement learning to make it higher at recognizing
patterns and making decisions based on those patterns. Up to now yr and a half, the team has
made significant progress in the sport, winning a record-tying 13 games in a row to maneuver into the
top 4 of the world rankings.
"The sport of Go is a fancy game by which players must be very careful to not overextend their
territory, and that is something that now we have been in a position to improve over and all over again," said
Dr. Demis Hassabis, co-founder and Chief Scientific Officer of DeepMind. "We're very happy with our
team's work, and we hope that it would encourage others to take the following step of their research and
apply the identical techniques to other problems."
Along with the win in Go, DeepMind has also developed an AI system that may learn to play a
number of various games, including poker, Go, and chess. This AI system, called Tarsier, was
developed in partnership with Carnegie Mellon University and the University of California,
Berkeley, and is getting used to show computer vision and machine learning to discover objects in
images and recognize speech in natural language. Tarsier has been trained to play the sport of Go
and other games on a
----------------------------------------------------------------------------------------------------
[Remark] We see that the generated text is of exceptionally top quality. All the document is grammatically fluent in addition to semantically coherent. Meanwhile, the generated text also well maintains its factually correctness. For example, in the primary paragraph, it elaborates “AlphaGo” because the “first program to defeat an expert Go player”.
5.3. Visual Demonstration of Contrastive Search:
To higher understand how contrastive search works, we offer a visible comparison between greedy search (Section 4.1) and contrastive search. Specifically, we visualize the token similarity matrix of the generated text from greedy search and contrastive search, respectively. The similarity between two tokens is defined because the cosine similarity between their token representations (i.e. the hidden states of the last transformer layer). The outcomes of greedy search (top) and contrastive search (bottom) are shown within the Figure below.
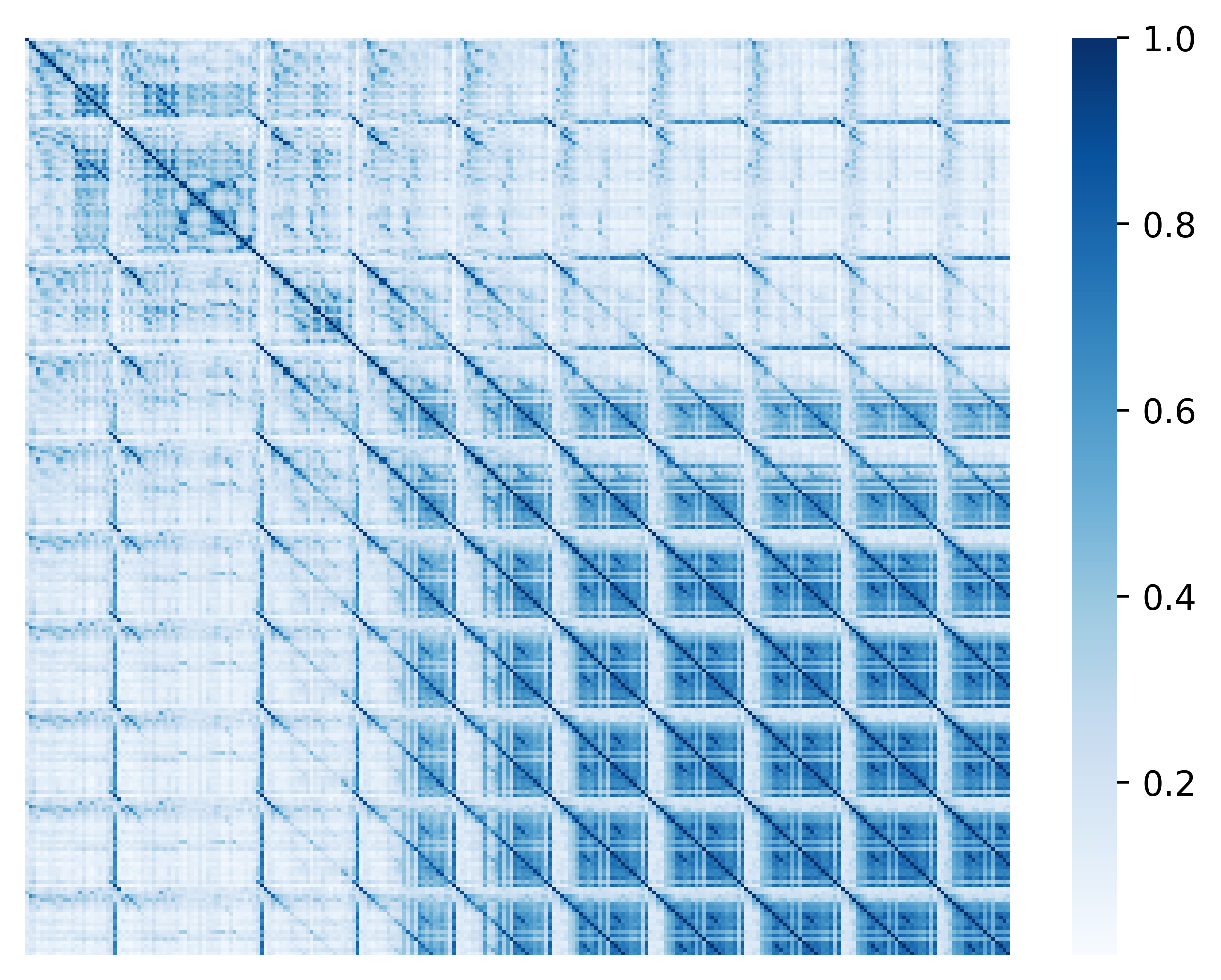
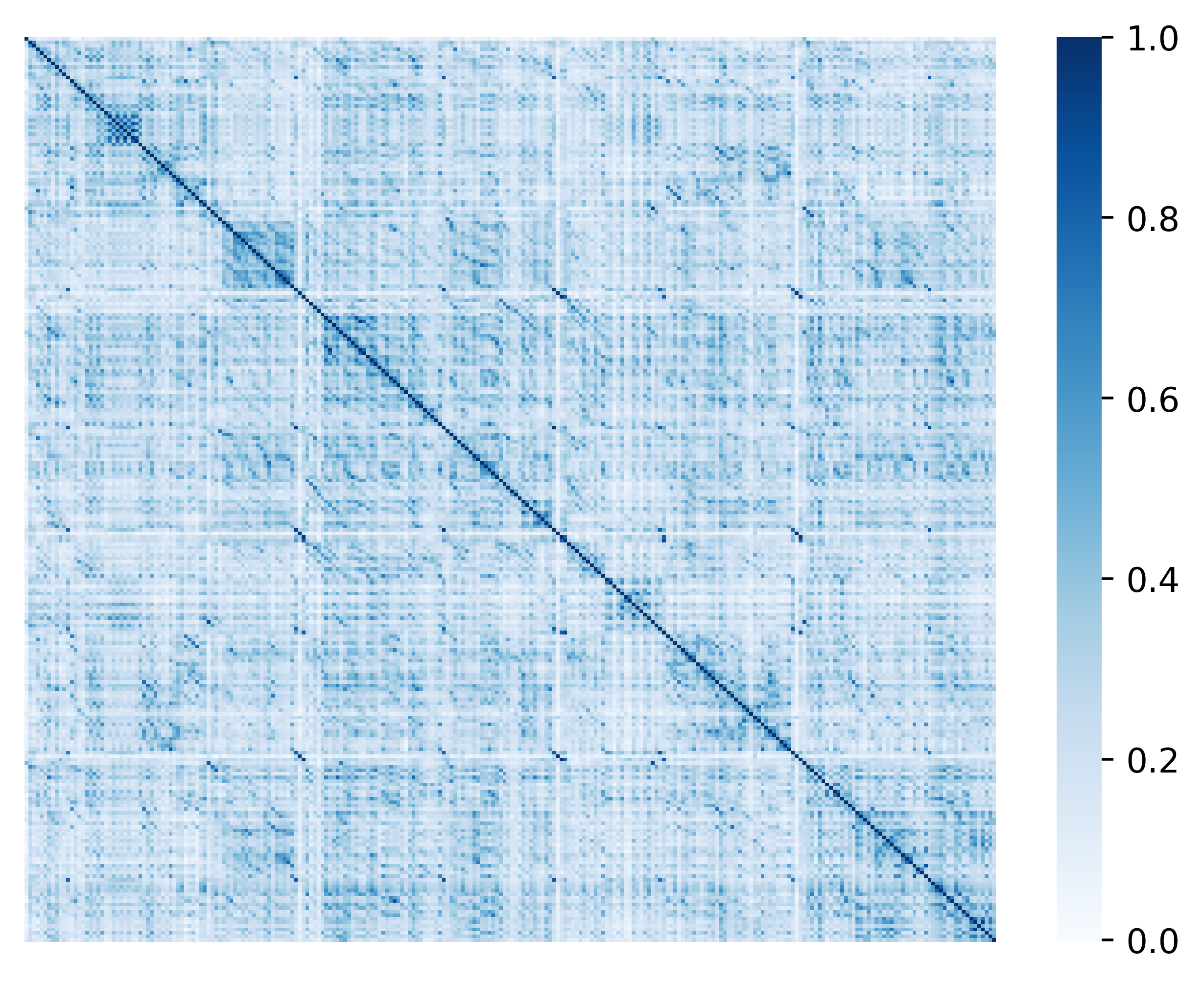
[Remark] From the results of greedy search, we see high similarity scores within the off-diagonal entries which clearly indicates the generated repetitions by greedy search. Quite the opposite, in the results of contrastive search, the high similarity scores mostly appear within the diagonal entries which verifies that the degeneration problem is successfully addressed. This nice property of contrastive search is achieved by the introduction of degeneration penalty (see Section 5.1) through the decoding process.
6. More Generated Examples:
On this section, we offer more generated examples to match different decoding methods.
6.1. Example One – GPT-2:
On this part, we use GPT-2 to generate text with the prefix text from the unique OpenAI blog that announced the discharge of GPT-2.
In a shocking finding, scientist discovered a herd of unicorns living in a distant, previously unexplored valley, within the Andes Mountains. Much more surprising to the researchers was the indisputable fact that the unicorns spoke perfect English.
Load the language model and prepare the prefix text:
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
prefix_text = r"In a shocking finding, scientist discovered a herd of unicorns living in a distant, previously unexplored valley, within the Andes Mountains. Much more surprising to the researchers was the indisputable fact that the unicorns spoke perfect English."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
6.1.1. Generating Text with Greedy Search:
Code: [click to expand]
output = model.generate(input_ids, max_length=512)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output: [click to expand]
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a distant, previously
unexplored valley, within the Andes Mountains. Much more surprising to the researchers was the very fact
that the unicorns spoke perfect English.
The researchers, led by Dr. David R. Williams of the University of California, Santa Cruz,
discovered the unicorns within the Andes Mountains of Peru. The realm is thought for its unique geology
and is home to a lot of rare species of animals.
The researchers found the unicorns within the Andes Mountains of Peru.
"We were surprised to seek out that the unicorns were in a position to communicate with one another," Williams
said. "We were also surprised to seek out that they were in a position to communicate in English."
The researchers imagine that the unicorns are descendants of the traditional Incas, who lived within the
area around 2,000 years ago.
"The Incas were the primary people to make use of the Andes Mountains as a refuge from the cruel climate of
the Andes," Williams said. "They were also the primary people to make use of the Andes Mountains as a spot
to hunt and gather food."
The researchers imagine that the unicorns are descendants of the traditional Incas, who lived within the
area around 2,000 years ago.
"The Incas were the primary people to make use of the Andes Mountains as a refuge from the cruel climate of
the Andes," Williams said. "They were also the primary people to make use of the Andes Mountains as a spot
to hunt and gather food."
The researchers imagine that the unicorns are descendants of the traditional Incas, who lived within the
area around 2,000 years ago.
"The Incas were the primary people to make use of the Andes Mountains as a refuge from the cruel climate of
the Andes," Williams said. "They were also the primary people to make use of the Andes Mountains as a spot
to hunt and gather food."
The researchers imagine that the unicorns are descendants of the traditional Incas, who lived within the
area around 2,000 years ago.
"The Incas were the primary people to make use of the Andes Mountains as a refuge from the cruel climate of
the Andes," Williams said. "They were also the primary people to make use of the Andes Mountains as a spot
to hunt and gather food."
The researchers imagine that the unicorns are descendants of the traditional Incas, who lived within the
area around 2,000 years ago
----------------------------------------------------------------------------------------------------
6.1.2. Generating Text with Nucleus Sampling:
Code: [click to expand]
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=512, top_p=0.95, top_k=0)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output: [click to expand]
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a distant, previously
unexplored valley, within the Andes Mountains. Much more surprising to the researchers was the very fact
that the unicorns spoke perfect English. The study was published within the Journal of Zoology in
March 2016.
Polygynous mammals akin to unicorns have remained largely unknown to science. Professor Gustavo
Giacota, from the University of Oxford who led the study, said that they'd been documented as
far as Eastern Siberia in Russia, but had only been seen a handful of times within the Gobi Desert.
Tiny animals with pale and glossy coats live within the presence of human beings and are hardly likely
to be victims of any cruelty. Nonetheless, there may be some evidence of the condition occurring in each
humans and animals in distant regions, which might need similarities to "black moles" that coexist
on the skin.
It is believed that Unicorns could possibly be inside themselves, that they've different scents depending
on their current environment, or simply fall out and there are many legends of how they've
survived. Experts speculate that the moths and other animals could possibly be remnants of the Yezidi Isis
and Charon, which accurately is each the word which implies great bird, and the Greek word for sound.
It is claimed that the Isis and Charon taught their young using voice in the shape of calling out
to others.
The scientists think that it could possibly be ancient folklore that has survived and isn't any longer attributed
to an actual entity
----------------------------------------------------------------------------------------------------
6.1.3. Generating Text with Contrastive Search:
Code:
output = model.generate(input_ids, max_length=512, penalty_alpha=0.6, top_k=4)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output:
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a distant, previously unexplored
valley, within the Andes Mountains. Much more surprising to the researchers was the indisputable fact that the unicorns
spoke perfect English.
In accordance with the BBC, a team of scientists led by Dr David MacKay, from the University of Bristol, spent
two years looking for the unicorn herd, which they found during a survey of the realm.
"It's a really rare find," MacKay told the BBC. "There are just a few within the Himalayas, but that is the primary
time we have been in a position to find one in such a distant area."
The team was surprised to seek out a herd of unicorns living in a region that has been known to be a hotbed
of poaching, with most of the animals poached for his or her horns, that are utilized in traditional Chinese
medicine to treat all the pieces from rheumatism to cancer.
"We knew that the realm was wealthy in rhino horn, but we had no idea what number of there have been, or what they were
doing there," MacKay said. "That is an area of high poaching pressure, and we wanted to seek out out what was
happening."
With a view to accomplish that, the team used GPS collars to trace the animals as they moved across the mountain and
the encompassing area. The GPS data was then compared with information gathered from local villagers, who
had a wealth of knowledge in regards to the animals' movements, including where they were eating, what they were
doing at night, and the way much time they spent within the mountains every day.
After analyzing the information, the team determined that the herd consisted of a minimum of three species of unicorns,
including a male and two females. One among the females was the mother of the male, and the opposite two were her
daughters. All three had the identical horn color, which is believed to be an indication of purity within the animal kingdom.
While the invention is exciting, it is not the primary time scientists have discovered an animal that speaks
English. Last yr, scientists discovered a species of porcupine that may be heard by humans, and has been
dubbed "Porcupine Man" for his ability to converse with the human race.
----------------------------------------------------------------------------------------------------
6.2. Example Two – OPT:
On this part, we use the OPT model [5] which is recently released by Meta to generate text by taking the primary two sentences from the abstract of the celebrated ResNet paper [6].
Deeper neural networks are tougher to coach. We present a residual learning framework to ease the training of networks which might be substantially deeper than those used previously.
Load the language model and prepare the prefix text:
import torch
from transformers import AutoTokenizer, OPTForCausalLM
model_name = r'facebook/opt-1.3b'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OPTForCausalLM.from_pretrained(model_name)
prefix_text = r"Deeper neural networks are tougher to coach. We present a residual learning framework to ease the training of networks which might be substantially deeper than those used previously."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
6.2.1. Generating Text with Greedy Search:
Code: [click to expand]
output = model.generate(input_ids, max_length=256)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output: [click to expand]
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are tougher to coach. We present a residual learning framework to ease
the training of networks which might be substantially deeper than those used previously. We show that the
residual learning framework may be used to coach deep neural networks which might be significantly more
difficult to coach than those used previously. We also show that the residual learning framework can
be used to coach deep neural networks which might be significantly tougher to coach than those used
previously.
The paper presents a brand new residual learning framework for deep neural networks that is predicated on the
concept of residuals. The residuals are the residuals of the network that usually are not utilized in the training
process. The residuals are computed by taking the residuals of the network which might be utilized in the training
process and subtracting the residuals of the network that usually are not utilized in the training process. The
residuals are then used to coach the network. The residuals are computed by taking the residuals of
the network which might be utilized in the training process and subtracting the residuals of the network that
usually are not utilized in the training process. The residuals are then used to coach the network. The residuals
are computed by taking the residuals of the network which might be utilized in the training process and
subtracting the residuals of the
----------------------------------------------------------------------------------------------------
6.2.2. Generating Text with Nucleus Sampling:
Code: [click to expand]
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=256, top_p=0.95, top_k=0)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output: [click to expand]
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are tougher to coach. We present a residual learning framework to ease the
training of networks which might be substantially deeper than those used previously. The idea focuses on
several features of learning, including the dynamics of replicative and non-replicative features of learning.
This framework emphasizes learning by entropy. Recent randomized algorithms enable training networks with
residual learning, in order that deep networks may be deployed as reliably and as efficiently as their more
conventional counterparts.
----------------------------------------------------------------------------------------------------
6.2.3. Generating Text with Contrastive Search:
Code:
output = model.generate(input_ids, max_length=256, penalty_alpha=0.6, top_k=6)
print("Output:n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
Model Output:
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are tougher to coach. We present a residual learning framework to ease
the training of networks which might be substantially deeper than those used previously.
On this paper, we propose a model-based residual learning (MBRL) framework that is predicated on neural
networks trained on data that's sparse by way of dimensionality (e.g., 1, 2, 3, etc.). The network
parameters are chosen such that there's a high probability of convergence, i.e., the variety of
iterations is large enough to attenuate the variance of the residuals. That is achieved by training
the network on a set of coaching data, by which the information is sparse by way of dimensionality, and
then discarding the nonparametric a part of the information after training is complete.
We show that MBRL outperforms other methods for deep reinforcement learning (RL) and deep convolutional
neural networks (CNNs) by an element of a minimum of 2. As well as, we show that, in comparison with CNNs, MBRL
performs higher in two-dimensional (2D) and three-dimensional (3D) cases.
----------------------------------------------------------------------------------------------------
7. Resources:
For more details of contrastive search, please check our papers and code as
8. Citation:
@inproceedings{su2022a,
title={A Contrastive Framework for Neural Text Generation},
writer={Yixuan Su and Tian Lan and Yan Wang and Dani Yogatama and Lingpeng Kong and Nigel Collier},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
yr={2022},
url={https://openreview.net/forum?id=V88BafmH9Pj}
}
@article{su2022contrastiveiswhatyouneed,
title={Contrastive Search Is What You Need For Neural Text Generation},
writer={Su, Yixuan and Collier, Nigel},
journal={arXiv preprint arXiv:2210.14140},
yr={2022}
}
Reference:
[1] Su et al., 2022 “A Contrastive Framework for Neural Text Generation”, NeurIPS 2022
[2] Su and Collier, 2022 “Contrastive Search Is What You Need For Neural Text Generation”, Arxiv 2022
[3] Fan et al., 2018 “Hierarchical Neural Story Generation”, ACL 2018
[4] Holtzman et al., 2020 “The Curious Case of Neural Text Degeneration”, ICLR 2020
[5] Zhang et al., 2022 “OPT: Open Pre-trained Transformer Language Models”, Arxiv 2022
[6] He et al., 2016 “Deep Residual Learning for Image Recognition”, CVPR 2016
– Written by Yixuan Su and Tian Lan
Acknowledgements:
We would really like to thank Joao Gante (@joaogante), Patrick von Platen (@patrickvonplaten), and Sylvain Gugger (@sgugger) for his or her help and guidance in adding contrastive search mentioned on this blog post into the transformers library.