



In this text, you’ll learn find out how to use Habana® Gaudi®2 to speed up model training and inference, and train greater models with 🤗 Optimum Habana. Then, we present several benchmarks including BERT pre-training, Stable Diffusion inference and T5-3B fine-tuning, to evaluate the performance differences between first generation Gaudi, Gaudi2 and Nvidia A100 80GB. Spoiler alert – Gaudi2 is about twice faster than Nvidia A100 80GB for each training and inference!
Gaudi2 is the second generation AI hardware accelerator designed by Habana Labs. A single server accommodates 8 accelerator devices with 96GB of memory each (versus 32GB on first generation Gaudi and 80GB on A100 80GB). The Habana SDK, SynapseAI, is common to each first-gen Gaudi and Gaudi2.
That signifies that 🤗 Optimum Habana, which offers a really user-friendly interface between the 🤗 Transformers and 🤗 Diffusers libraries and SynapseAI, works the very same way on Gaudi2 as on first-gen Gaudi!
So in case you have already got ready-to-use training or inference workflows for first-gen Gaudi, we encourage you to try them on Gaudi2, as they may work with none single change.
Find out how to Get Access to Gaudi2?
One in every of the straightforward, cost-efficient ways in which Intel and Habana have made Gaudi2 available is on the Intel Developer Cloud. To begin using Gaudi2 there, you need to follow the next steps:
-
Go to the Intel Developer Cloud landing page and register to your account or register in case you should not have one.
-
Go to the Intel Developer Cloud management console.
-
Select Habana Gaudi2 Deep Learning Server featuring eight Gaudi2 HL-225H mezzanine cards and latest Intel® Xeon® Processors and click on on Launch Instance within the lower right corner as shown below.
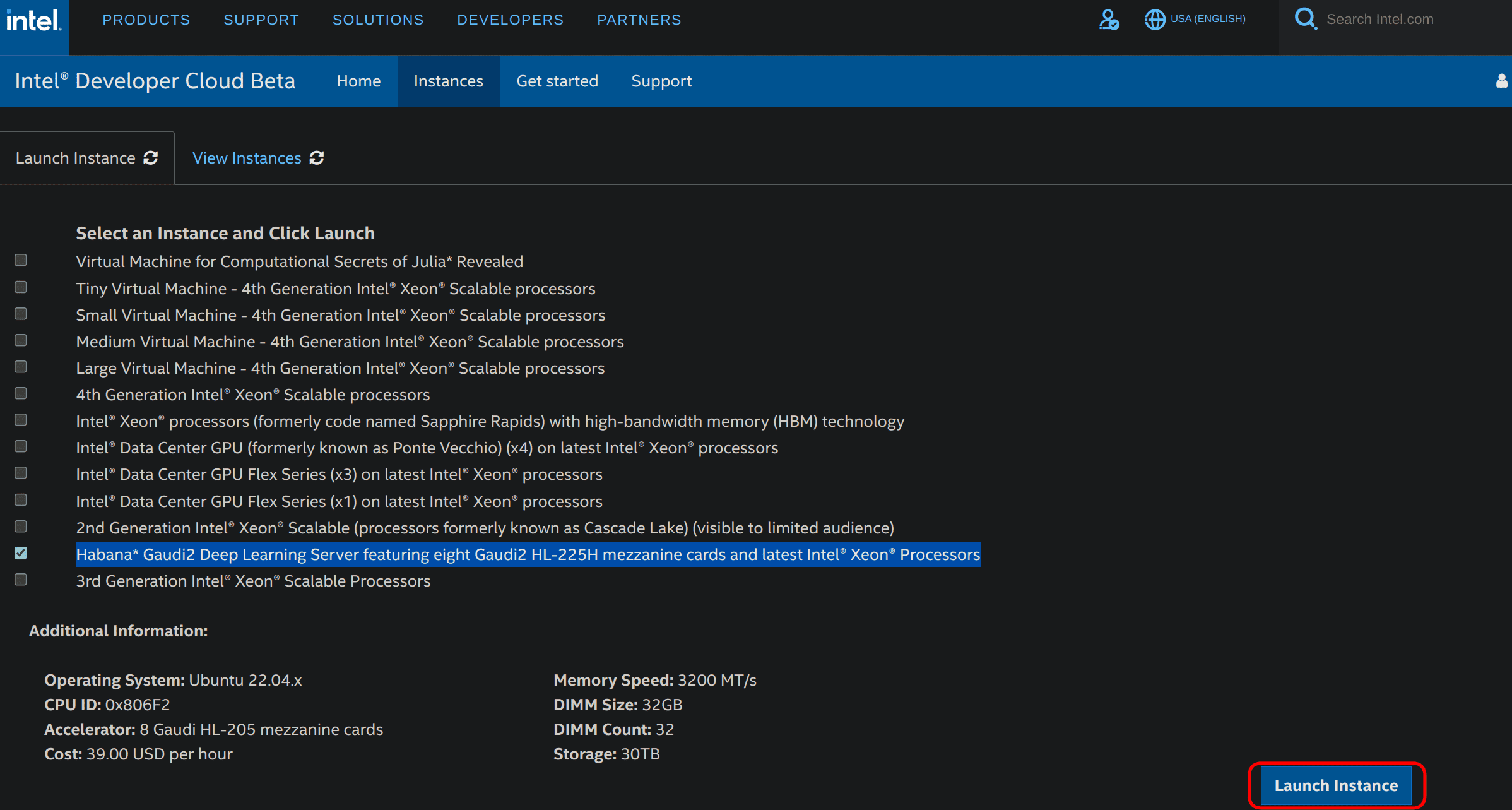
-
You’ll be able to then request an instance:
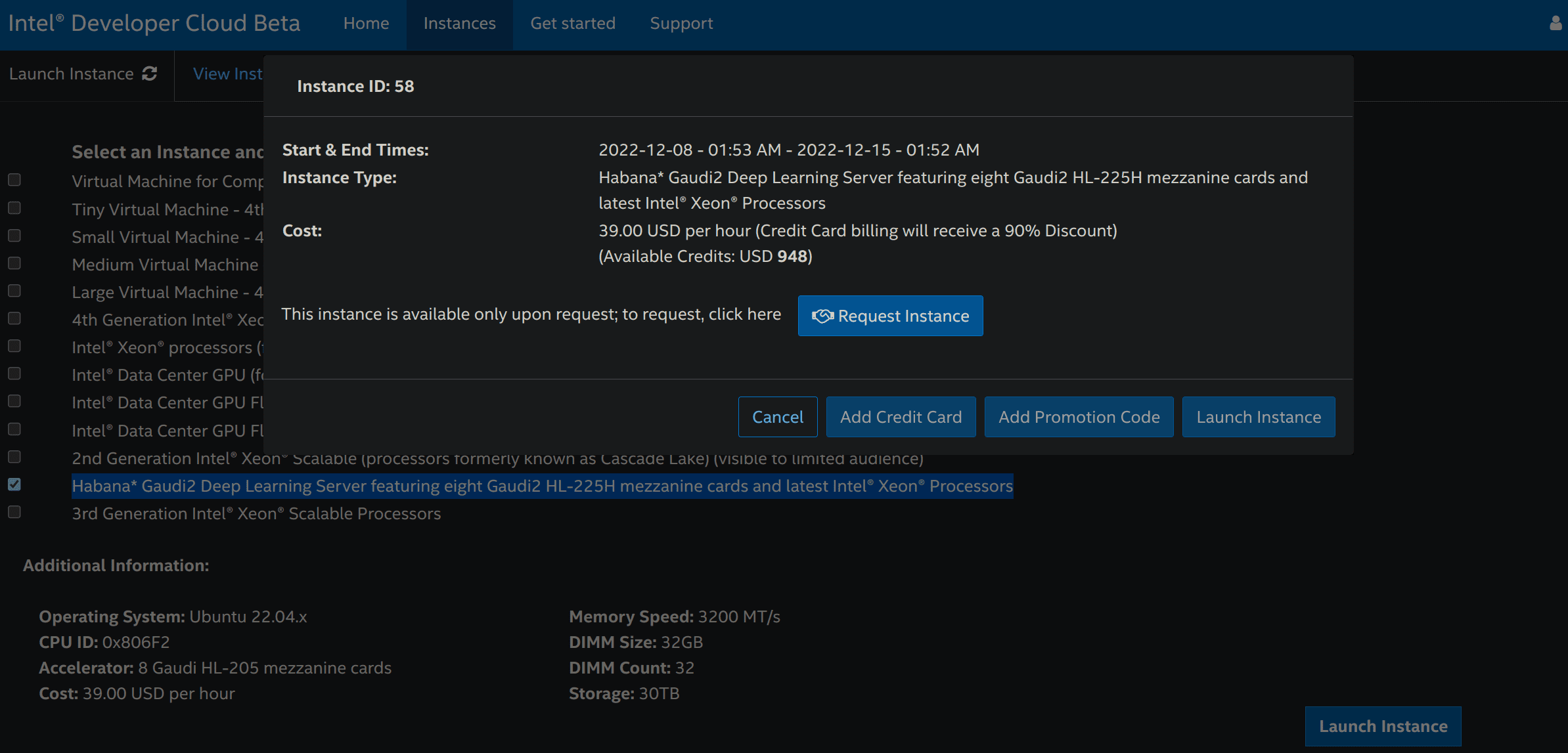
-
Once your request is validated, re-do step 3 and click on on Add OpenSSH Publickey so as to add a payment method (bank card or promotion code) and a SSH public key that you would be able to generate with
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa. You might be redirected to step 3 every time you add a payment method or a SSH public key. -
Re-do step 3 after which click on Launch Instance. You should have to just accept the proposed general conditions to truly launch the instance.
-
Go to the Intel Developer Cloud management console and click on on the tab called View Instances.
-
You’ll be able to copy the SSH command to access your Gaudi2 instance remotely!
In the event you terminate the instance and wish to make use of Gaudi2 again, you should have to re-do the entire process.
You will discover more details about this process here.
Benchmarks
Several benchmarks were performed to evaluate the skills of first-gen Gaudi, Gaudi2 and A100 80GB for each training and inference, and for models of assorted sizes.
Pre-Training BERT
A couple of months ago, Philipp Schmid, technical lead at Hugging Face, presented find out how to pre-train BERT on Gaudi with 🤗 Optimum Habana. 65k training steps were performed with a batch size of 32 samples per device (so 8*32=256 in total) for a complete training time of 8 hours and 53 minutes (you possibly can see the TensorBoard logs of this run here).
We re-ran the identical script with the identical hyperparameters on Gaudi2 and got a complete training time of two hours and 55 minutes (see the logs here). That makes a x3.04 speedup on Gaudi2 without changing anything.
Since Gaudi2 has roughly 3 times more memory per device in comparison with first-gen Gaudi, it is feasible to leverage this greater capability to have greater batches. This can give HPUs more work to do and may even enable developers to try a variety of hyperparameter values that was not reachable with first-gen Gaudi. With a batch size of 64 samples per device (512 in total), we got with 20k steps an identical loss convergence to the 65k steps of the previous runs. That makes a complete training time of 1 hour and 33 minutes (see the logs here). The throughput is x1.16 higher with this configuration, while this latest batch size strongly accelerates convergence.
Overall, with Gaudi2, the full training time is reduced by a 5.75 factor and the throughput is x3.53 higher in comparison with first-gen Gaudi.
Gaudi2 also offers a speedup over A100: 1580.2 samples/s versus 981.6 for a batch size of 32 and 1835.8 samples/s versus 1082.6 for a batch size of 64, which is consistent with the x1.8 speedup announced by Habana on the phase 1 of BERT pre-training with a batch size of 64.
The next table displays the throughputs we got for first-gen Gaudi, Gaudi2 and Nvidia A100 80GB GPUs:
| First-gen Gaudi (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) | |
|---|---|---|---|---|---|
| Throughput (samples/s) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| Speedup | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
BS is the batch size per device. The Gaudi runs were performed in mixed precision (bf16/fp32) and the A100 runs in fp16. All runs were distributed runs on 8 devices.
Generating Images from Text with Stable Diffusion
One in every of the primary latest features of 🤗 Optimum Habana release 1.3 is the support for Stable Diffusion. It’s now very easy to generate images from text on Gaudi. Unlike with 🤗 Diffusers on GPUs, images are generated by batches. Resulting from model compilation times, the primary two batches can be slower than the next iterations. On this benchmark, these first two iterations were discarded to compute the throughputs for each first-gen Gaudi and Gaudi2.
This script was run for a batch size of 8 samples. It uses the Habana/stable-diffusion Gaudi configuration.
The outcomes we got, that are consistent with the numbers published by Habana here, are displayed within the table below.
Gaudi2 showcases latencies which might be x3.51 faster than first-gen Gaudi (3.25s versus 0.925s) and x2.84 faster than Nvidia A100 (2.63s versus 0.925s). It might probably also support greater batch sizes.
| First-gen Gaudi (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) | |
|---|---|---|---|
| Latency (s/img) | 3.25 | 0.925 | 2.63 |
| Speedup | x1.0 | x3.51 | x1.24 |
Update: the figures above were updated as SynapseAI 1.10 and Optimum Habana 1.6 bring a further speedup on first-gen Gaudi and Gaudi2.
BS is the batch size.
The Gaudi runs were performed in bfloat16 precision and the A100 runs in fp16 precision (more information here). All runs were single-device runs.
Positive-tuning T5-3B
With 96 GB of memory per device, Gaudi2 enables running much greater models. For example, we managed to fine-tune T5-3B (containing 3 billion parameters) with gradient checkpointing being the one applied memory optimization. This will not be possible on first-gen Gaudi.
Here are the logs of this run where the model was fine-tuned on the CNN DailyMail dataset for text summarization using this script.
The outcomes we achieved are presented within the table below. Gaudi2 is x2.44 faster than A100 80GB. We observe that we cannot fit a batch size larger than 1 on Gaudi2 here. That is resulting from the memory space taken by the graph where operations are accrued in the course of the first iteration of the run. Habana is working on optimizing the memory footprint in future releases of SynapseAI. We’re looking forward to expanding this benchmark using newer versions of Habana’s SDK and in addition using DeepSpeed to see if the identical trend holds.
| First-gen Gaudi | Gaudi2 (BS=1) | A100 (BS=16) | |
|---|---|---|---|
| Throughput (samples/s) | N/A | 19.7 | 8.07 |
| Speedup | / | x2.44 | x1.0 |
BS is the batch size per device. Gaudi2 and A100 runs were performed in fp32 with gradient checkpointing enabled. All runs were distributed runs on 8 devices.
Conclusion
In this text, we discuss our first experience with Gaudi2. The transition from first generation Gaudi to Gaudi2 is totally seamless since SynapseAI, Habana’s SDK, is fully compatible with each. Which means latest optimizations proposed by future releases will profit each of them.
You’ve seen that Habana Gaudi2 significantly improves performance over first generation Gaudi and delivers about twice the throughput speed as Nvidia A100 80GB for each training and inference.
You furthermore may know now find out how to setup a Gaudi2 instance through the Intel Developer Zone. Try the examples you possibly can easily run on it with 🤗 Optimum Habana.
In the event you are thinking about accelerating your Machine Learning training and inference workflows using the newest AI hardware accelerators and software libraries, take a look at our Expert Acceleration Program. To learn more about Habana solutions, examine our partnership here and contact them. To learn more about Hugging Face efforts to make AI hardware accelerators easy to make use of, take a look at our Hardware Partner Program.
Related Topics
Thanks for reading! If you could have any questions, be at liberty to contact me, either through Github or on the forum. You may as well connect with me on LinkedIn.