

On this blog post, we cover the fundamentals of graph machine learning.
We first study what graphs are, why they’re used, and the way best to represent them. We then cover briefly how people learn on graphs, from pre-neural methods (exploring graph features at the identical time) to what are commonly called Graph Neural Networks. Lastly, we peek into the world of Transformers for graphs.
Graphs
What’s a graph?
In its essence, a graph is an outline of things linked by relations.
Examples of graphs include social networks (Twitter, Mastodon, any citation networks linking papers and authors), molecules, knowledge graphs (equivalent to UML diagrams, encyclopedias, and any website with hyperlinks between its pages), sentences expressed as their syntactic trees, any 3D mesh, and more! It’s, subsequently, not hyperbolic to say that graphs are in all places.
The items of a graph (or network) are called its nodes (or vertices), and their connections its edges (or links). For instance, in a social network, nodes are users and edges their connections; in a molecule, nodes are atoms and edges their molecular bond.
- A graph with either typed nodes or typed edges is named heterogeneous (example: citation networks with items that will be either papers or authors have typed nodes, and XML diagram where relations are typed have typed edges). It can’t be represented solely through its topology, it needs additional information. This post focuses on homogeneous graphs.
- A graph can be directed (like a follower network, where A follows B doesn’t imply B follows A) or undirected (like a molecule, where the relation between atoms goes each ways). Edges can connect different nodes or one node to itself (self-edges), but not all nodes should be connected.
If you ought to use your data, you will need to first consider its best characterisation (homogeneous/heterogeneous, directed/undirected, and so forth).
What are graphs used for?
Let’s take a look at a panel of possible tasks we are able to do on graphs.
On the graph level, the important tasks are:
- graph generation, utilized in drug discovery to generate latest plausible molecules,
- graph evolution (given a graph, predict how it can evolve over time), utilized in physics to predict the evolution of systems
- graph level prediction (categorisation or regression tasks from graphs), equivalent to predicting the toxicity of molecules.
On the node level, it’s always a node property prediction. For instance, Alphafold uses node property prediction to predict the 3D coordinates of atoms given the general graph of the molecule, and subsequently predict how molecules get folded in 3D space, a tough bio-chemistry problem.
On the edge level, it’s either edge property prediction or missing edge prediction. Edge property prediction helps drug side effect prediction predict opposed uncomfortable side effects given a pair of medication. Missing edge prediction is utilized in suggestion systems to predict whether two nodes in a graph are related.
It is usually possible to work on the sub-graph level on community detection or subgraph property prediction. Social networks use community detection to find out how individuals are connected. Subgraph property prediction will be present in itinerary systems (equivalent to Google Maps) to predict estimated times of arrival.
Working on these tasks will be done in two ways.
When you ought to predict the evolution of a particular graph, you’re employed in a transductive setting, where all the pieces (training, validation, and testing) is completed on the identical single graph. If that is your setup, watch out! Creating train/eval/test datasets from a single graph shouldn’t be trivial. Nevertheless, a number of the work is completed using different graphs (separate train/eval/test splits), which is named an inductive setting.
How can we represent graphs?
The common ways to represent a graph to process and operate it are either:
- because the set of all its edges (possibly complemented with the set of all its nodes)
- or because the adjacency matrix between all its nodes. An adjacency matrix is a square matrix (of node size * node size) that indicates which nodes are directly connected to which others (where (A_{ij} = 1) if (n_i) and (n_j) are connected, else 0). Note: most graphs aren’t densely connected and subsequently have sparse adjacency matrices, which may make computations harder.
Nevertheless, though these representations seem familiar, don’t be fooled!
Graphs are very different from typical objects utilized in ML because their topology is more complex than simply “a sequence” (equivalent to text and audio) or “an ordered grid” (images and videos, for instance)): even in the event that they will be represented as lists or matrices, their representation mustn’t be considered an ordered object!
But what does this mean? If you’ve got a sentence and shuffle its words, you create a brand new sentence. If you’ve got a picture and rearrange its columns, you create a brand new image.
This shouldn’t be the case for a graph: should you shuffle its edge list or the columns of its adjacency matrix, it remains to be the identical graph. (We explain this more formally a bit lower, search for permutation invariance).
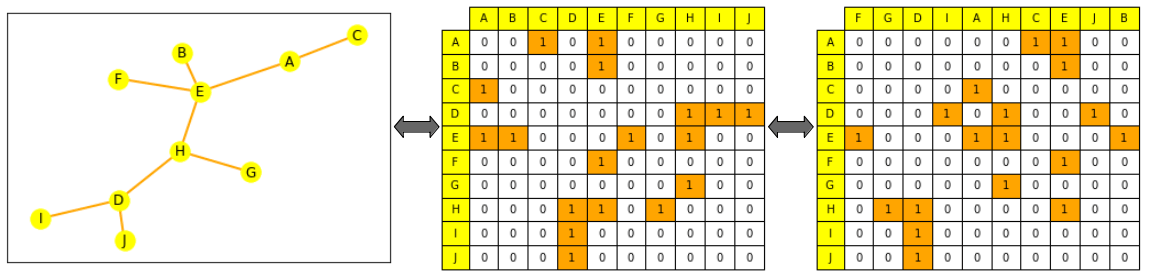
Graph representations through ML
The standard process to work on graphs with machine learning is first to generate a meaningful representation in your items of interest (nodes, edges, or full graphs depending in your task), then to make use of these to coach a predictor in your goal task. We wish (as in other modalities) to constrain the mathematical representations of your objects in order that similar objects are mathematically close. Nevertheless, this similarity is tough to define strictly in graph ML: for instance, are two nodes more similar once they have the identical labels or the identical neighbours?
Note: In the next sections, we are going to deal with generating node representations.
Once you’ve got node-level representations, it is feasible to acquire edge or graph-level information. For edge-level information, you may concatenate node pair representations or do a dot product. For graph-level information, it is feasible to do a worldwide pooling (average, sum, etc.) on the concatenated tensor of all of the node-level representations. Still, it can smooth and lose information over the graph — a recursive hierarchical pooling could make more sense, or add a virtual node, connected to all other nodes within the graph, and use its representation as the general graph representation.
Pre-neural approaches
Simply using engineered features
Before neural networks, graphs and their items of interest might be represented as mixtures of features, in a task-specific fashion. Now, these features are still used for data augmentation and semi-supervised learning, though more complex feature generation methods exist; it will possibly be essential to seek out how best to supply them to your network depending in your task.
Node-level features may give details about importance (how vital is that this node for the graph?) and/or structure based (what’s the shape of the graph across the node?), and will be combined.
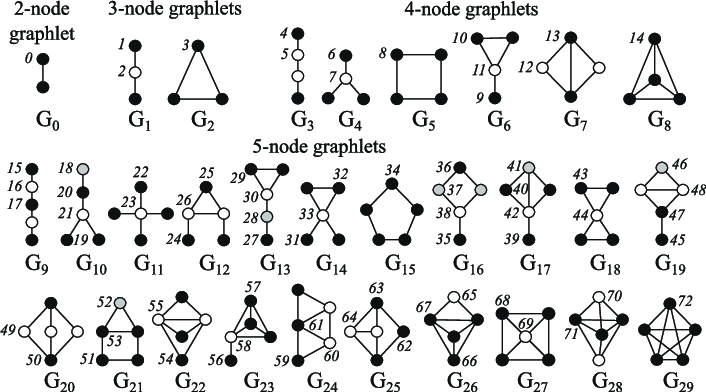
The node centrality measures the node importance within the graph. It may possibly be computed recursively by summing the centrality of every node’s neighbours until convergence, or through shortest distance measures between nodes, for instance. The node degree is the amount of direct neighbours it has. The clustering coefficient measures how connected the node neighbours are. Graphlets degree vectors count how many alternative graphlets are rooted at a given node, where graphlets are all of the mini graphs you may create with a given variety of connected nodes (with three connected nodes, you may have a line with two edges, or a triangle with three edges).
Edge-level features complement the representation with more detailed information in regards to the connectedness of the nodes, and include the shortest distance between two nodes, their common neighbours, and their Katz index (which is the variety of possible walks of as much as a certain length between two nodes – it will possibly be computed directly from the adjacency matrix).
Graph level features contain high-level details about graph similarity and specificities. Total graphlet counts, though computationally expensive, provide information in regards to the shape of sub-graphs. Kernel methods measure similarity between graphs through different “bag of nodes” methods (much like bag of words).
Walk-based approaches
Walk-based approaches use the probability of visiting a node j from a node i on a random walk to define similarity metrics; these approaches mix each local and global information. Node2Vec, for instance, simulates random walks between nodes of a graph, then processes these walks with a skip-gram, very like we’d do with words in sentences, to compute embeddings. These approaches can be used to speed up computations of the Page Rank method, which assigns an importance rating to every node (based on its connectivity to other nodes, evaluated as its frequency of visit by random walk, for instance).
Nevertheless, these methods have limits: they can not obtain embeddings for brand new nodes, don’t capture structural similarity between nodes finely, and can’t use added features.
Graph Neural Networks
Neural networks can generalise to unseen data. Given the representation constraints we evoked earlier, what should a superb neural network be to work on graphs?
It should:
- be permutation invariant:
- Equation: with f the network, P the permutation function, G the graph
- Explanation: the representation of a graph and its permutations must be the identical after going through the network
- be permutation equivariant
- Equation: with f the network, P the permutation function, G the graph
- Explanation: permuting the nodes before passing them to the network must be corresponding to permuting their representations
Typical neural networks, equivalent to RNNs or CNNs aren’t permutation invariant. A brand new architecture, the Graph Neural Network, was subsequently introduced (initially as a state-based machine).
A GNN is fabricated from successive layers. A GNN layer represents a node as the mix (aggregation) of the representations of its neighbours and itself from the previous layer (message passing), plus normally an activation so as to add some nonlinearity.
Comparison to other models: A CNN will be seen as a GNN with fixed neighbour sizes (through the sliding window) and ordering (it shouldn’t be permutation equivariant). A Transformer without positional embeddings will be seen as a GNN on a fully-connected input graph.
Aggregation and message passing
There are numerous ways to aggregate messages from neighbour nodes, summing, averaging, for instance. Some notable works following this concept include:
- Graph Convolutional Networks averages the normalised representation of the neighbours for a node (most GNNs are literally GCNs);
- Graph Attention Networks learn to weigh different neighbours based on their importance (like transformers);
- GraphSAGE samples neighbours at different hops before aggregating their information in several steps with max pooling.
- Graph Isomorphism Networks aggregates representation by applying an MLP to the sum of the neighbours’ node representations.
Selecting an aggregation: Some aggregation techniques (notably mean/max pooling) can encounter failure cases when creating representations which finely differentiate nodes with different neighbourhoods of comparable nodes (ex: through mean pooling, a neighbourhood with 4 nodes, represented as 1,1,-1,-1, averaged as 0, shouldn’t be going to be different from one with only 3 nodes represented as -1, 0, 1).
GNN shape and the over-smoothing problem
At each latest layer, the node representation includes increasingly more nodes.
A node, through the primary layer, is the aggregation of its direct neighbours. Through the second layer, it remains to be the aggregation of its direct neighbours, but this time, their representations include their very own neighbours (from the primary layer). After n layers, the representation of all nodes becomes an aggregation of all their neighbours at distance n, subsequently, of the total graph if its diameter is smaller than n!
In case your network has too many layers, there’s a risk that every node becomes an aggregation of the total graph (and that node representations converge to the identical one for all nodes). This is named the oversmoothing problem
This will be solved by :
- scaling the GNN to have a layer number sufficiently small to not approximate each node as the entire network (by first analysing the graph diameter and shape)
- increasing the complexity of the layers
- adding non message passing layers to process the messages (equivalent to easy MLPs)
- adding skip-connections.
The oversmoothing problem is a very important area of study in graph ML, because it prevents GNNs to scale up, like Transformers have been shown to in other modalities.
Graph Transformers
A Transformer without its positional encoding layer is permutation invariant, and Transformers are known to scale well, so recently, people have began adapting Transformers to graphs (Survey). Most methods deal with the most effective ways to represent graphs by searching for the most effective features and best ways to represent positional information and changing the eye to suit this latest data.
Listed below are some interesting methods which got state-of-the-art results or close on considered one of the toughest available benchmarks as of writing, Stanford’s Open Graph Benchmark:
- Graph Transformer for Graph-to-Sequence Learning (Cai and Lam, 2020) introduced a Graph Encoder, which represents nodes as a concatenation of their embeddings and positional embeddings, node relations because the shortest paths between them, and mix each in a relation-augmented self attention.
- Rethinking Graph Transformers with Spectral Attention (Kreuzer et al, 2021) introduced Spectral Attention Networks (SANs). These mix node features with learned positional encoding (computed from Laplacian eigenvectors/values), to make use of as keys and queries in the eye, with attention values being the sting features.
- GRPE: Relative Positional Encoding for Graph Transformer (Park et al, 2021) introduced the Graph Relative Positional Encoding Transformer. It represents a graph by combining a graph-level positional encoding with node information, edge level positional encoding with node information, and mixing each in the eye.
- Global Self-Attention as a Alternative for Graph Convolution (Hussain et al, 2021) introduced the Edge Augmented Transformer. This architecture embeds nodes and edges individually, and aggregates them in a modified attention.
- Do Transformers Really Perform Badly for Graph Representation (Ying et al, 2021) introduces Microsoft’s Graphormer, which won first place on the OGB when it got here out. This architecture uses node features as query/key/values in the eye, and sums their representation with a mix of centrality, spatial, and edge encodings in the eye mechanism.
Probably the most recent approach is Pure Transformers are Powerful Graph Learners (Kim et al, 2022), which introduced TokenGT. This method represents input graphs as a sequence of node and edge embeddings (augmented with orthonormal node identifiers and trainable type identifiers), with no positional embedding, and provides this sequence to Transformers as input. It is amazingly easy, yet smart!
A bit different, Recipe for a General, Powerful, Scalable Graph Transformer (Rampášek et al, 2022) introduces, not a model, but a framework, called GraphGPS. It allows to mix message passing networks with linear (long range) transformers to create hybrid networks easily. This framework also incorporates several tools to compute positional and structural encodings (node, graph, edge level), feature augmentation, random walks, etc.
Using transformers for graphs remains to be very much a field in its infancy, however it looks promising, because it could alleviate several limitations of GNNs, equivalent to scaling to larger/denser graphs, or increasing model size without oversmoothing.
Further resources
If you ought to delve deeper, you may have a look at a few of these courses:
- Academic format
- Video format
- Books
- Surveys
- Research directions
- GraphML in 2023 summarizes plausible interesting directions for GraphML in 2023.
Nice libraries to work on graphs are PyGeometric or the Deep Graph Library (for graph ML) and NetworkX (to govern graphs more generally).
Should you need quality benchmarks you may take a look at:
- OGB, the Open Graph Benchmark: the reference graph benchmark datasets, for various tasks and data scales.
- Benchmarking GNNs: Library and datasets to benchmark graph ML networks and their expressivity. The associated paper notably studies which datasets are relevant from a statistical standpoint, what graph properties they permit to guage, and which datasets should now not be used as benchmarks.
- Long Range Graph Benchmark: recent (Nov2022) benchmark long range graph information
- Taxonomy of Benchmarks in Graph Representation Learning: paper published on the 2022 Learning on Graphs conference, which analyses and type existing benchmarks datasets
For more datasets, see:
External images attribution
Emojis within the thumbnail come from Openmoji (CC-BY-SA 4.0), the Graphlets figure comes from Biological network comparison using graphlet degree distribution (Pržulj, 2007).